
Site Navigation
Contents of Thesis ack'ments - Introduction - Context - Accessibility - W3C/WAI - LitReview - Metadata - Accessibility Metadata - PNP - DRD - Matching - UI profiles - Interoperability - Framework - Implementation - Conclusion - References - Appendix 1 - Appendix 2 - Appendix 3 - Appendix 4 - Appendix 5 - Appendix 6 - Appendix 7
| Images | Explanations |
|---|---|
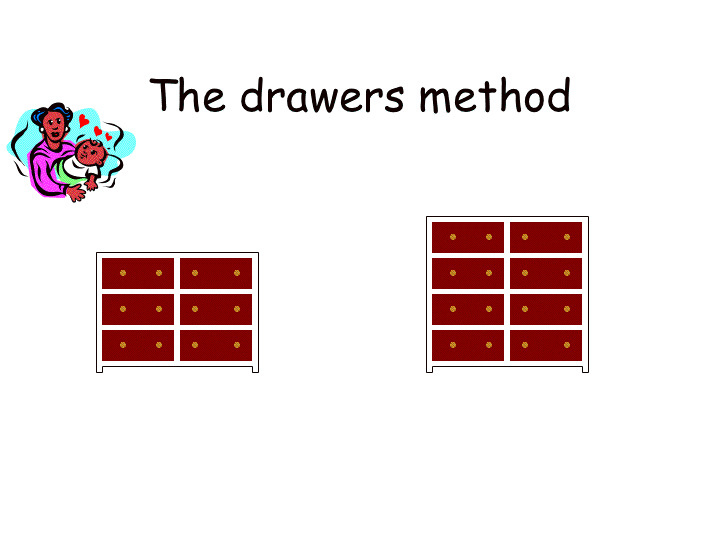 |
In the home, we put our clothes away and remember which drawer holds what and assume that, if we're not wearing the clothes, they will be in the drawers or in the wash. We know which drawer to go to for our socks. |
 |
In the office, we put documents in files in drawers and number them so we can look up the number, or name, and find the file and thus the document. |
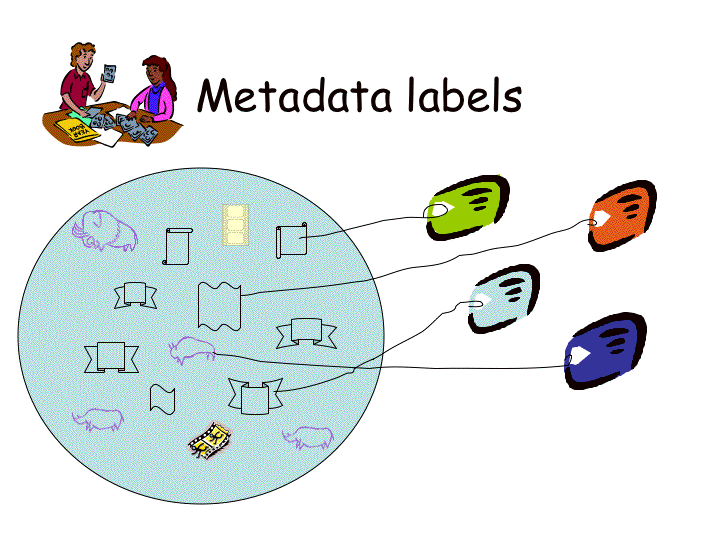 |
In the digital world, we have invisible digital objects so we write labels for them and look through the labels to find the object we want. |
 |
If we label our digital objects in the same way, even using the same grammar, we can attach a lot of different labels to the same object and still find what we want. |
 |
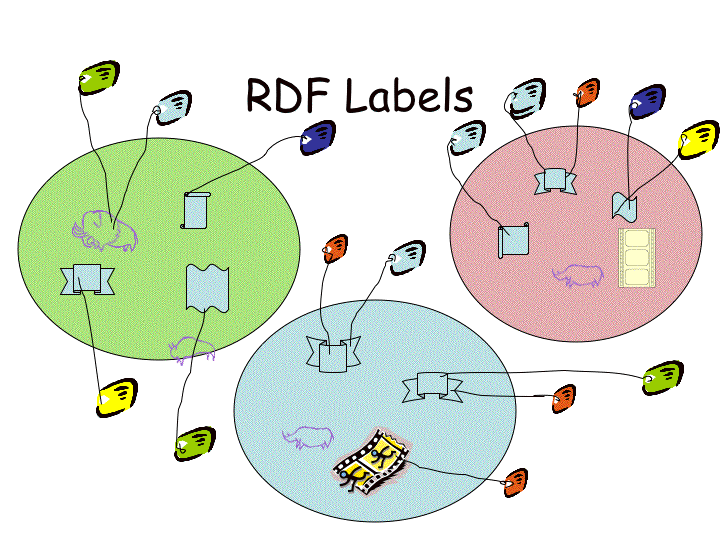
If we have rules for organising the labels, we can use the labels to sort and organise the objects. |
 |
Then we can connect objects to each other by referring to the labels, even without looking at the objects themselves. |
(ref - AGLS pres)... the abstraction of labels from the objects they label.
W3C says that, "Metadata is machine understandable information for the web." (W3C Metadata Activity)
DCMI's description in plain English includes:
Metadata has been with us since the first librarian made a list of the items on a shelf of handwritten scrolls. The term "meta" comes from a Greek word that denotes "alongside, with, after, next." More recent Latin and English usage would employ "meta" to denote something transcendental, or beyond nature. Metadata, then, can be thought of as data about other data. It is the Internet-age term for information that librarians traditionally have put into catalogs, and it most commonly refers to descriptive information about Web resources.
A metadata record consists of a set of attributes, or elements, necessary to describe the resource in question. For example, a metadata system common in libraries -- the library catalog -- contains a set of metadata records with elements that describe a book or other library item: author, title, date of creation or publication, subject coverage, and the call number specifying location of the item on the shelf.
The linkage between a metadata record and the resource it describes may take one of two forms:
1. elements may be contained in a record separate from the item, as in the case of the library's catalog record; or
2. the metadata may be embedded in the resource itself.Examples of embedded metadata that is carried along with the resource itself include the Cataloging In Publication (CIP) data printed on the verso of a book's title page; or the TEI header in an electronic text. Many metadata standards in use today, including the Dublin Core standard, do not prescribe either type of linkage, leaving the decision to each particular implementation. (DCMI Usage Guide)
In describing the Content Standard for Digital Geospatial Metadata, the Clinton administration's Federal Geographic Data Committee said;
The objectives of the standard are to provide a common set of terminology and definitions for the documentation of digital geospatial data. The standard establishes the names of data elements and compound elements (groups of data elements) to be used for these purposes, the definitions of these compound elements and data elements, and information about the values that are to be provided for the data elements. (FGDC 1998)
mmmm... this format or this: the date elements. (ref) or the data elements (ref). ???
They go on to add:
The standard was developed from the perspective of defining the information required by a prospective user to determine the availability of a set of geospatial data, to determine the fitness [of] the set of geospatial data for an intended use, to determine the means of accessing the set of geospatial data, and to successfully transfer the set of geospatial data. As such, the standard establishes the names of data elements and compound elements to be used for these purposes, the definitions of these data elements and compound elements, and information about the values that are to be provided for the data elements. The standard does not specify the means by which this information is organized in a computer system or in a data transfer, nor the means by which this information is transmitted, communicated, or presented to the user.
There are many definitions of metadata but generally they share two characteristics; they are about "a common set of terminology and definitions" and they have a structure for that language that is shared. Although metadata is analogous to catalogue and other filing descriptions, the name usually indicates that it is recorded and used electronically.
One difficulty in the use of the term is that it is, correctly, a plural noun but as that is awkward and not common practice, it will herein be treated as a singular noun, following the practice described by Murtha Baca, Head, Getty Standards Program, in her introduction to a book about metadata written by Getty staff and others:
Note: The authors of this publication are well aware that the noun "metadata" (like the noun "data") is plural, and should take plural verb forms. We have opted to treat it as a singular noun, as in everyday speech, in order to avoid awkward locutions. (Baca, 1998)
Another difficulty is the frequency with which the word 'mapping' is used. The current author wishes to write about mapping but is aware of its use in the context of 'metadata mapping' where it is usually meant to denote the relating of one mapping scheme to another, and the 'metadata application profile' (MAP) where it means a particular set of metadata rules, and even more specifically as used by the DCMI, a set of rules where the rules are a combination of rules from other sets.
Yet another difficulty is a quality of good metadata: one man's metadata can be another's data. The characteristic of metadata being referred to here is what is known as its 'first class' nature: any metadata can be either the data about some other data or itself the subject of other metadata. This is exemplified by the work of the Open Archives Initiative [OAI] who have developed a standard for describing metadata so that it can be 'harvested'. Typical OAI metadata is as follows:
<header> <identifier>oai:arXiv:cs/0112017</identifier> <datestamp>2002-02-28</datestamp> <setSpec>cs</setSpec> <setSpec>math</setSpec> </header> <metadata> <oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd"> <dc:title>Using Structural Metadata to Localize Experience of Digital Content</dc:title> <dc:creator>Dushay, Naomi</dc:creator> <dc:subject>Digital Libraries</dc:subject> <dc:description>With the increasing technical sophistication of both information consumers and providers, there is increasing demand for more meaningful experiences of digital information. We present a framework that separates digital object experience, or rendering, from digital object storage and manipulation, so the rendering can be tailored to particular communities of users. </dc:description> <dc:description>Comment: 23 pages including 2 appendices, 8 figures</dc:description> <dc:date>2001-12-14</dc:date> <dc:type>e-print</dc:type> <dc:identifier>http://arXiv.org/abs/cs/0112017</dc:identifier> </oai_dc:dc> </metadata> <about> <provenance xmlns="http://www.openarchives.org/OAI/2.0/provenance" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/provenance http://www.openarchives.org/OAI/2.0/provenance.xsd"> <originDescription harvestDate="2002-02-02T14:10:02Z" altered="true"> <baseURL>http://the.oa.org</baseURL> <identifier>oai:r2:klik001</identifier> <datestamp>2002-01-01</datestamp> <metadataNamespace>http://www.openarchives.org/OAI/2.0/oai_dc/</metadataNamespace> </originDescription> </provenance> </about>
(OAI, 2002)
In this example, there is metadata about metadata.
In "Metadata Principles and Practicalities" (Weibel et al, 2002), the authors comment that:
The global scope of the Web URI namespace means that each data element in an element set can be represented by a globally addressable name (its URI). Invariant global identifiers make machine processing of metadata across languages and applications far easier, but may impose unnatural constraints in a given context.
Identifiers such as URIs are not convenient as labels to be read by people, especially when such labels are in a language or character set other than the natural language of a given application. People prefer to read simple strings that have meaning in their own language. Particular tools and applications can use different presentation labels within their systems to make the labels more understandable and useful in a given linguistic, cultural, or domain context."(Weibel et al, 2002)
In fact, although it is often hoped that metadata will be human-readable, the more it becomes useful to computers, the more that it seems to become unreadable to humans. In large part this is due to its generally being encoded in languages that make it essential for the reader to know what is encoding and what is the metadata, but it is also perhaps an artifact of how it is presented.
Atlases are useful collections of maps, traditionally collected from a range of cartographers (Ashdowne et al, 2000). Such a collection makes more sense, or is more useful if the conventions for representation used in each map are the same. In this writing, metadata is used to denote structured descriptions of resources that are organised in a common way and use a common language. The way of writing the descriptions and terms used should be defined in an open way so they can be interpreted by machines and people.
When collecting descriptive metadata for discovery, one usually has a database or repository and specifications for the structure of the data to be stored in that repository that makes it possible to ‘publish' the data in a consistent way. In order to share metadata for repositories, it is necessary to have the same structure for all metadata but usually, to make one's own metadata most useful locally, those who develop such metadata tend to want idiosyncratic structures that suit their local purposes. So local specificity and global share-ability, inter-operability, are competing interests. Sharing of the metadata means that more people can reuse it whereas local specificity makes it more valuable in the immediate context, where it is usually engaged with more frequently, and where the cost is often borne.
One of the features of good metadata is that it is suitable for use in a simple way but that it can handle complexity. Another is that it operates widely on the dimension of locally-specific to globally-interoperable.
simple
^
|
locally-specific <----------------------> globally interoperable
|
v
complex
The Dublin Core Metadata Element Set (more recently known as the DC Terms and now called the Description Set???) provides an excellent example of how this might be achieved. It is a formal definition of the way in which descriptive information about a resource can be stored. It has a core set of elements that have been found to be extremely useful in describing almost every type of resource on the Web. Elements can be qualified in various ways for greater precision. In addition, selected elements can be combined with others in what is called an 'application profile' to create a new set for a given purpose. 'Dublin Core' metadata is considered to be such if it conforms to the formal definition of such metadata although there is no requirement for the number of elements that must be used beyond that there must be a unique identifier for the resource being described. DC metadata can be expressed in a range of computer languages.
Originally, DC metadata was used in HTML tags in simple resources. The choice of meaning for elements was, to a certain extent, arbitrary and based on a pragmatic approach to the high-cost of quality metadata and the experience of cataloguers in the bibliographic world - mostly. Some of the definitions were arrived at as a sort of compromise and they were fairly loosely defined, even where experienced cataloguers knew there were problems being hidden within them.
Over the last decade, the definitions and supporting documentation have been slowly improved, always with the need to ensure that this will not alienate existing systems.
Currently, the DC terms are defined as follows:
Each term is specified with the following minimal set of attributes:
- Name:
- The unique token assigned to the term.
- URI:
- The Uniform Resource Identifier used to uniquely identify a term.
- Label:
- The human-readable label assigned to the term.
- Definition:
- A statement that represents the concept and essential nature of the term.
- Type of Term:
- The type of term, such as Element or Encoding Scheme, as described in the DCMI Grammatical Principles.
- Status:
- Status assigned to term by the DCMI Usage Board, as described in the DCMI Usage Board Process.
- Date issued:
- Date on which a term was first declared.
Where applicable, the following attributes provide additional information about a term:
- Comment:
- Additional information about the term or its application.
- See:
- A link to authoritative documentation.
- References:
- A citation or URL of a resource referenced in the Definition or Comment.
- Refines:
- A reference to a term refined by an Element Refinement.
- Qualifies:
- A reference to a term qualified by an Encoding Scheme.
- Broader Than:
- A reference from a more general to a more specific Vocabulary Term.
- Narrower Than:
- A reference from a more specific to a more general Vocabulary Term. (DC Terms)
Despite the aim of having strict adherence to the original definitions of the DC terms, it became difficult to deal with the many moves to expand, qualify and otherwise change the DC terms. Doggedly sticking to the original documentation without further explanation and improved interoperability was proving a threat to the utility of DC metadata as the technology developed. In 2000, Thomas Baker described the grammar of the DCMES in an attempt to make it clear how it manages extensibility of elements:
with examples:
In 1999, a meeting about how to use DC metadata in educational portals was convened at Kattamingga in Australia by the author. At this meeting, educationalists discussed the suitability of the DC terms to provide for descriptions of learning resources. The international group agreed that there were some extra things that collectively they wanted to use and that if there were a way of 'regularising' these, interoperability between educational catalogues (repositories) would be improved.
Ad hoc rules for extensions and alterations of terms were suggested on the spot by the Director of the DCMI, Stu Weibel, who said that all qualifications should:
In addition, there was the idea that certain communities would find particular terms useful and the DCMI should provide for their inclusion, perhaps as a second layer of terms for use. Significantly, this was the first formal application profile. An application profile was understood to be a metadata profile, conformant to DC principles, but suited to the needs of the local or domain specific community using it. The development led to the formation of working groups for communities of interest within the DCMI structure, and soon was followed by others such as the Government Working Group.The Government working group of the DCMI followed the lead of the education Working Group by developing an application profile. Many years later, the term 'audience' was added to the core DC set of terms.
In 2000 a seminal article describing application profiles was written by Rachel Heery and others ( Heery et al, 2000), and these are now established within DC practice. The essence of an application profile is that it allows for the mixing of metadata terms from different schema: the constraint on it is that it should not, itself, define new metadata terms but derive them from existing schema. When this is not possible because the community in fact wants a new term, this is achieved by the community defining that term in a new name space and then referring to it, alongside other terms used in the application profile.
The DCMI glossary of 2006 offered the following:
application profile
In DCMI usage, an application profile is a declaration of the metadata terms an organization, information resource, application, or user community uses in its metadata. In a broader sense, it includes the set of metadata elements, policies, and guidelines defined for a particular application or implementation. The elements may be from one or more element sets, thus allowing a given application to meet its functional requirements by using metadata elements from several element sets including locally defined sets. For example, a given application might choose a specific subset of the Dublin Core elements that meets its needs, or may include elements from the Dublin Core, another element set, and several locally defined elements, all combined in a single schema. An application profile is not considered complete without documentation that defines the policies and best practices appropriate to the application. (DCMI Glossary-A)
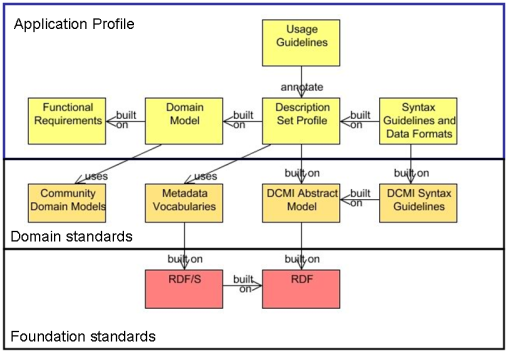
In an attempt to further clarify the Dublin Core approach to metadata, the DCMI Architecture Working Group published two diagrams and some description of them in March 2005. Version 1.0 of what is known as the Abstract Model [DCMI AM] emerged after six months of interaction and consideration by the Working Group in an open forum.
It should be noted that its authors, Powell et al., stated that: “the UML modeling used here shows the abstract model but is not intended to form a suitable basis for the development of DCMI software applications”. Software developers were, however, explicitly stated to be one of the three target audiences for the DCAM, the other two being developers of syntax encoding guidelines and of application profiles.
That Abstract Model was a substantial step towards making it easier for implementers to model the DC metadata but it still did not solve all the problems. In 2006, a funded effort to provide an abstract model was commissioned by the DCMI. This produced a more formal graphical representation.
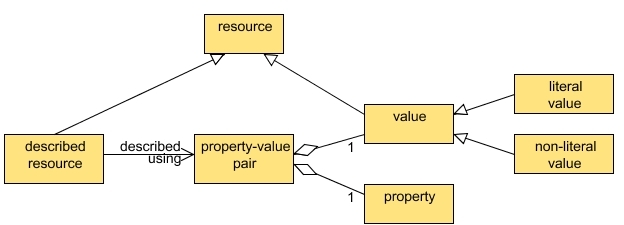
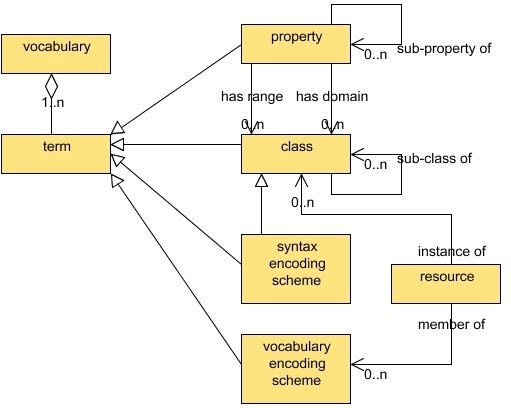
DCMI Resource Model (Powell
et al, 2007)
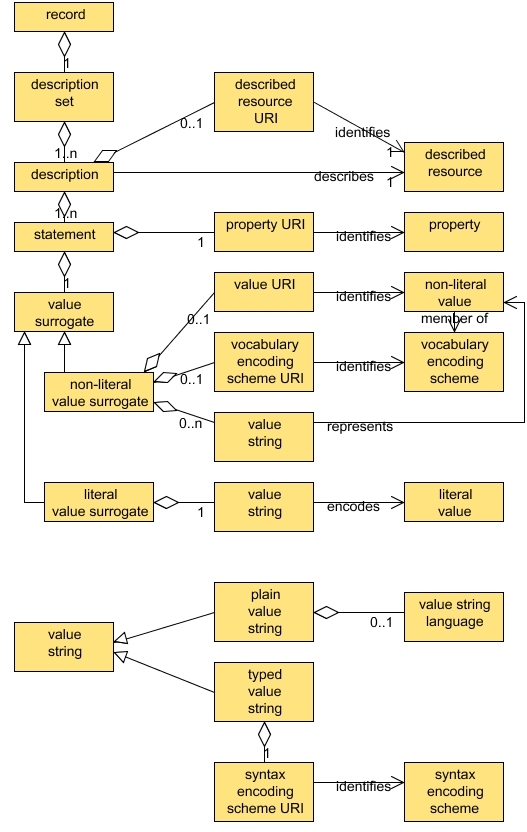
DCMI Description Set Model (Powell
et al, 2007)
DCMI Vocabulary Model (Powell
et al, 2007)
That model did not adhere to the strict rules for such diagrams set by the Unified Modeling Language (ref) and was not as easy to interpret as had been hoped. The author and a student (Pulis & Nevile, 2006), and indeed another set of authors (ref), presented papers at the DC 2006 Conference in which they argued for a yet better model that was represented in strict UML form, pointing to a number of inconsistencies in the then current model. A new one was commissioned in 2007 and at the DC 2007 Conference, Mikael Nilsson (2007) presented a formal version and what is to be known as the Singapore Framework.
Having more precisely defined models enables profile developers to be more certain about what they need to do. This is important and the lack of a clear model, to a large extent, explains many of the difficulties faced in the accessibility metadata work.
DCMES can thus be seen as providing a three-dimensional mapping of the characteristics of Web resources:
with the facility for application profiles that contain combinations of these.
As some might see it, DC is providing for infinitely extensible, n-dimensional mapping of resources.
In general, the maps of metadata are not read so much as used in the discovery or identification process. But mapping in this sense is analogous to mapping as we commonly think of it in the cartographic sense. There are rules for the co-ordinates (descriptions) of resources and there are structural rules known in the information world as taxonomies that are topologies. The browse structure of a Web site allows one to zoom in and out on details and map intersections and location finders are common.
Web 2.0 is not a new Web but it is a world in which resources are distributed and combined in many ways at the instigation of both the publisher and the user. It is not possible to limit the ways in which this will be done and it is not yet clear how to 'freeze' or later reconstruct any given instantiation of a resource.
There is another aspect of Web 2.0 that is relevant to the work in accessibility. Social interaction on the Web is being generated in many cases by what is known as 'tagging' of resources. These resources are often very small, atomic, objects such as an image, or a small piece of text, or a sound file. While these objects have been on the Web since the beginning, in general they have been published within composite resources that have not been separately identified and they have rarely been described in metadata. The move is towards what is known as microformats:
a set of simple open data format standards that many (including Technorati) are actively developing and implementing for more/better structured blogging and web microcontent publishing in general. (Microformats)
Associated with this move is the departure of many Web users from Web site visitations to the use of 'back doors' into information stores. So many people use Google and its equivalent to find what they want and then 'click' their way into the middle of Web sites, that the time has come to think seriously about the role of Web sites. Blogs and wikis as publishing models are increasingly becoming the source of information for many people. As will be seen (in ch ???), the increasing availability of atomic objects, or objects in what is becoming known as micro-formats, is expected to increase the accessibility of the Web.
With respect to taxonomies, Lars Marius Garshol has the following to say:
The term taxonomy has been widely used and abused to the point that when something is referred to as a taxonomy it can be just about anything, though usually it will mean some sort of abstract structure. Taxonomies have their beginning with Carl von Linné [3], who developed a hierarchical classification system for life forms in the 18th century which is the basis for the modern zoological and botanical classification and naming system for species. In this paper we will use taxonomy to mean a subject-based classification that arranges the terms in the controlled vocabulary into a hierarchy without doing anything further, though in real life you will find the term "taxonomy" applied to more complex structures as well. ...
Note that the taxonomy helps users by describing the subjects; from the point of view of metadata there is really no difference between a simple controlled vocabulary and a taxonomy. The metadata only relates objects to subjects, whereas here we have arranged the subjects in a hierarchy. So a taxonomy describes the subjects being used for classification, but is not itself metadata; it can be used in metadata, however (Garshol, 2004).
He then points out that at one level higher, there are thesauri that usually provide preferred terms, wider and narrower terms. Of these he says:
Thesauri basically take taxonomies as described above and extend them to make them better able to describe the world by not only allowing subjects to be arranged in a hierarchy, but also allowing other statements to be made about the subjects (Garshol, 2004).
The ISO 2788 standard for thesauri provides for more details and helps make thesauri more useful for information discovery. The extra qualifiers are similar to those used in metadata definition, such as scope note, use top term and related term.
'Tagging' has become a feature of what many people think of as Web 2.0, the social information space where users contribute to content. This is often done simply by that adding of some 'tags' or freely chosen labels to others' content. For example, a user may visit a site and then send a tag referring to that site to a tag repository, organised by such as del.icio.us or digg. Typically such tags have values chosen freely by the user and so they may vary enormously for one concept, as well as the concepts associated with tags varying incredibly. In 2006, the STEVE Museum's Jennifer Trant (2006) reported that museum visitors who viewed paintings on site were prone to submit one tag but a completely different one when they re-visited the same painting remotely via a digital image. As indicated below, tags are generally displayed in what might be called a graphical form, for example, in tag clouds. With the increasingly graphical representation of metadata, including tags, metadata maps are starting to emerge. These can be used in a variety of ways, as considered below. Associated with the tags are not thesauri, as in the case of more structured metadata but what are called folksonomies. These are, in fact, ontologies but with very different characteristics from the more traditional library subject terms and generally not structured; that is, users typically add tags with subject, author, format, etc., all mixed in together. This is not necessary, and some users are precise in their use of tags, including encoding them to relate to standard DC Terms (see Pete Johnston's work...).
It should be noted that in response to the increased use of tags on sites, the author started a community within the Dublin Core Metadata Initiative that is concerned with the relationship between standard metadata and tagging (DC Social Tagging). It is not yet known if tagging is merely a fashion or here to stay as a robust way of getting user-generated metadata but it is of interest to see how users use words, and so might help in the selection of terms for standard thesauri (ed, STEVE, etc).
Rel-Tag is one of several MicroFormats. By adding rel="tag" to a hyperlink, a page indicates that the destination of that hyperlink is an author-designated "tag" (or keyword/subject) of the current page. (Microformats-2)
Tags are described on the Microformats Web site as follows:
rel="tag" hyperlinks are intended to be visible links on pages and posts. This is in stark contrast to meta keywords (which were invisible and typically never revealed to readers), and thus is at least somewhat more resilient to the problems which plagued meta keywords.
Making tag hyperlinks visible has the additional benefit of making it more obvious to readers if a page is abusing tag links, and thus providing more peer pressure for better behavior. It also makes it more obvious to authors, who may not always be aware what invisible metadata is being generated on their behalf. (Microformats-2)
In other words, the format
<a href="http://example.com/tag/example" rel="tag">example</a>
is recommended in preference to
<link rel="tag" href="..." />
Tags are typically gathered and presented in a variety of ways including in tag piles as shown in an extract from an author cloud:

A tag cloud (Library Thing)
Tag clouds have no specific structure. They tend to be simply piles of words, in no particular order except perhaps either alphabetical or temporal, with more popular terms displayed in larger font than less popular ones. Other systems use the graphical representation to show relationships between terms used, displaying the underlying structure in hierarchical, or other maps. Sometimes this is done explicitly, as in the case of the subject terms used in the Dewey Decimal System (DDS), for example, or implicitly, as done with the DC terms, in an abstract model that is completed for any set of actual terms. (See Fig ??? above).
Organization schemes like ontologies are conceptual; they reflect the ways we think. To convert these conceptual schemes into a format that a software application can process we need more concrete representations... (Lombardi, 2003)
Lars Marius Garshol describes several types of organising schemes:
Data Model - A description of data that consists of all entities represented in a data structure or database and the relationships that exist among them. It is more concrete than an ontology but more abstract than a database dictionary (the physical representation).
Resource Description Framework (RDF) - a W3C standard XML framework for describing and interchanging metadata. The simple format of resources, properties, and statements allows RDF to describe robust metadata, such as ontological structures. As opposed to Topic Maps, RDF is more decentralized because the XML is usually stored along with the resources.
Reference:Topic Maps - An ISO standard for describing knowledge structures and associating them with information resources. The topics, associations, and occurrences that comprise topic maps allow them to describe complex structures such as ontologies. They are usually implemented using XML (XML Topic Maps, or XTM). As opposed to RDF, Topic Maps are more centralized because all information is contained in the map rather than associated with the resources (Garshol, 2002)
He writes:
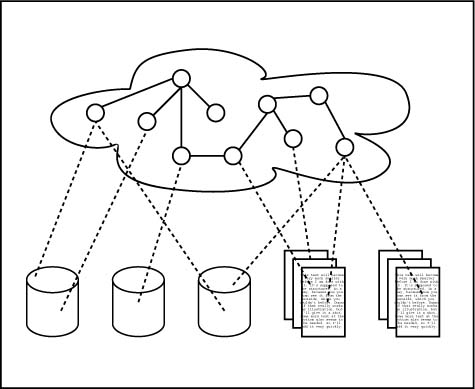
When XML is introduced into an organization it is usually used for one of two purposes: either to structure the organization's documents or to make that organization's applications talk to other applications. These are both useful ways of using XML, but they will not help anyone find the information they are looking for. What changes with the introduction of XML is that the document processes become more controllable and can be automated to a greater degree than before, while applications can now communicate internally and externally. But the big picture, something that collects the key concepts in the organization's information and ties it all together, is nowhere to be found.
This is where topic maps come in. With topic maps you create an index of information which resides outside that information, as shown in the diagram above. The topic map (the cloud at the top) describes the information in the documents (the little rectangles) and the databases (the little "cans") by linking into them using URIs (the lines).
The topic map takes the key concepts described in the databases and documents and relates them together independently of what is said about them in the information being indexed. So when a document says "The maintenance procedure for part X consists of the following steps..." the topic map may say "Part X is of type Q and is contained in parts Y and Z and its maintenance procedure resides in document W". This means taking a step back from the details and focusing on the forest rather than the trees. Or, to put it another way, it means managing the meaning of the information, rather than just the information.
The result is an information structure that breaks out of the traditional hierarchical straightjacket that we have gotten used to squeezing our information into. A topic map usually contains several overlapping hierarchies which are rich with semantic cross-links like "Part X is critical to procedure V." This makes information much easier to find because you no longer act as the designers expected you to; there are multiple redundant navigation paths that will lead you to the same answer. You can even use searches to jump to a good starting point for navigation (Garshol, 2002).
Faceted classification, according to Garshol, was first developed by S.R. Ranganathan in the 1930s.
and works by identifying a number of facets into which the terms are divided. The facets can be thought of as different axes along which documents can be classified, and each facet contains a number of terms. How the terms within each facet are described varies, though in general a thesaurus-like structure is used, and usually a term is only allowed to belong to a single facet ...
In faceted classification the idea is to classify documents by picking one term from each facet to describe the document along all the different axes. This would then describe the document from many different perspectives (Garshol, 2004).
In Rangathan's case, he picked 5 axes. There has been significant work on faceted classification since this was first invented and recently it has been demonstrated as a powerful and useful way to use metadata (Childress and al, http://www.oclc.org/research/publications/2000-2009.htm)
Garshol list of classification systems includes categories, taxonomies, thesauri, facets and then ontologies. He argues that as we progress through the list we are getting more expressive power with which to describe objects for their discovery. Of ontologies, he says:
With ontologies the creator of the subject description language is allowed to define the language at will. Ontologies in computer science came out of artificial intelligence, and have generally been closely associated with logical inferencing and similar techniques, but have recently begun to be applied to information retrieval.
He goes on in this article to describe topic maps as an ontology framework for information retrieval and to show that topic maps have a very rich structure for information about an object that is also quite likely to be interoperable. As his example he gives:
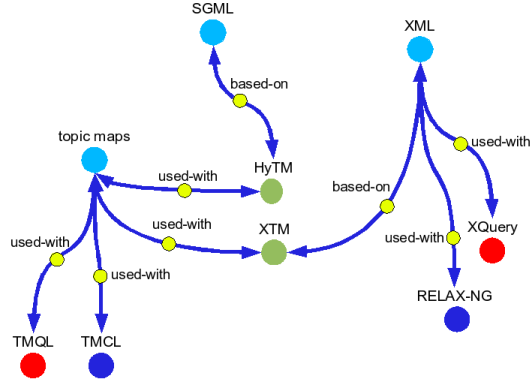
The colours have significance as shown:
| Identifier | Meaning |
|---|---|
| round discs | names of topics |
| arrows | associations |
| aqua | occurrences of a topic |
| blue | vocabulary languages |
| red | query languages |
| green | markup languages |
| yellow | these show the association types |
| Note: | different colours of discs could be read as scope of topic names, or type of topic |
Ontopia's Omnigator is a tool that allows the user to click on any topic name and have it become the 'centre of the universe' with its connections surrounding it. This makes interactive navigation around the graphical maps very simple and intuitive, and seamless across topic maps encoded differently [Ontopia].
In a similar way, the Resource Description Framework (RDF) provides a very flexible way of mapping resources. RDF requires the description of properties of resources to be strictly in the form:
resource ----- relationship ----- property
or
subject ---- predicate ---- object
as in
http://dublincore.org ---- has title ---- Dublin Core Metadata Initiative
The theory is that if all the properties are so described, it will be easy to make logical connections between them. Currently, RDF is implemented in XML, as that is the language of most common use today, but the framework is independent of the encoding. RDF maps, like other good metadata systems, are interoperable and extensible. A simple example of RDF maps and how they interoperate is provided by the following:
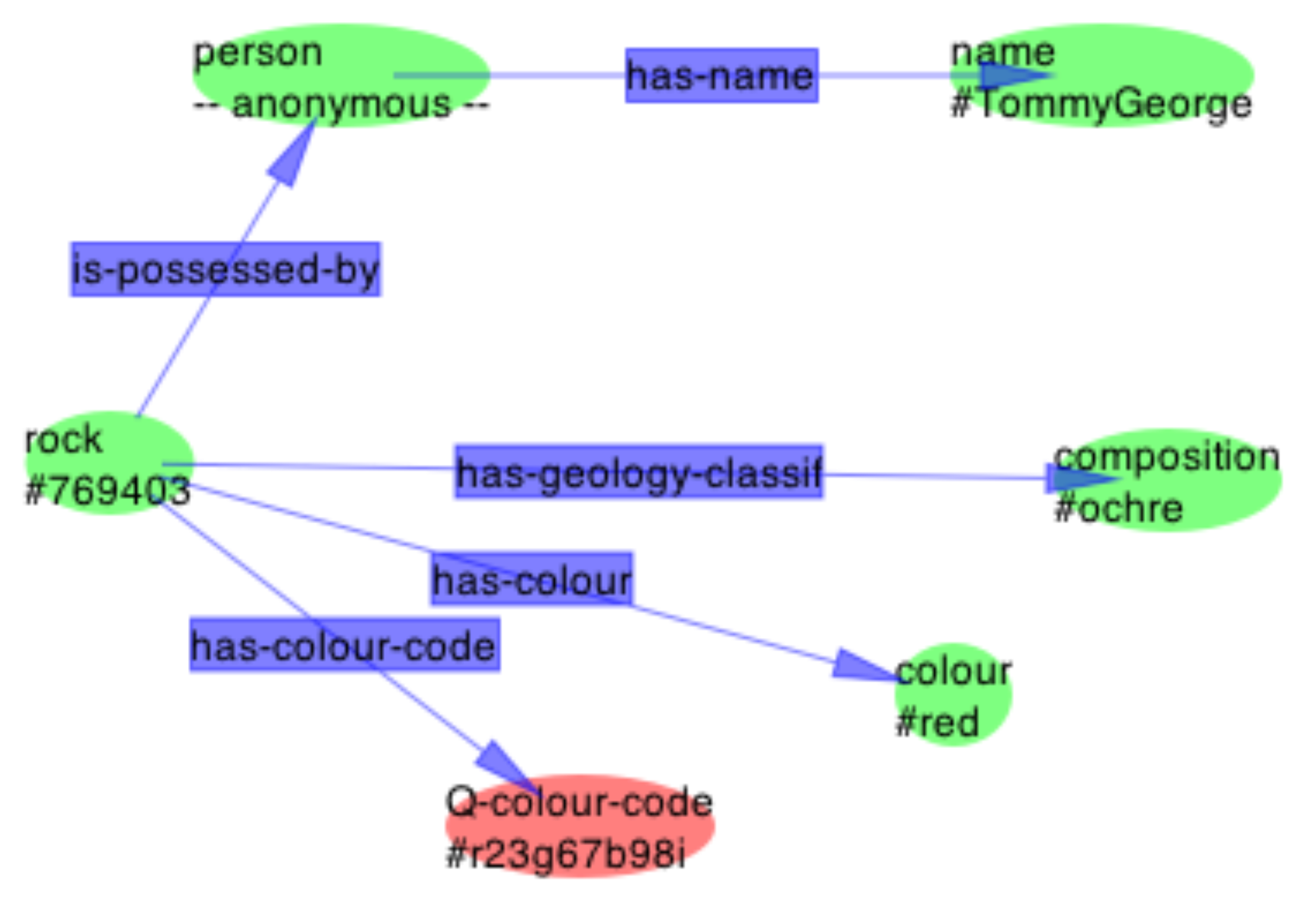 and
and 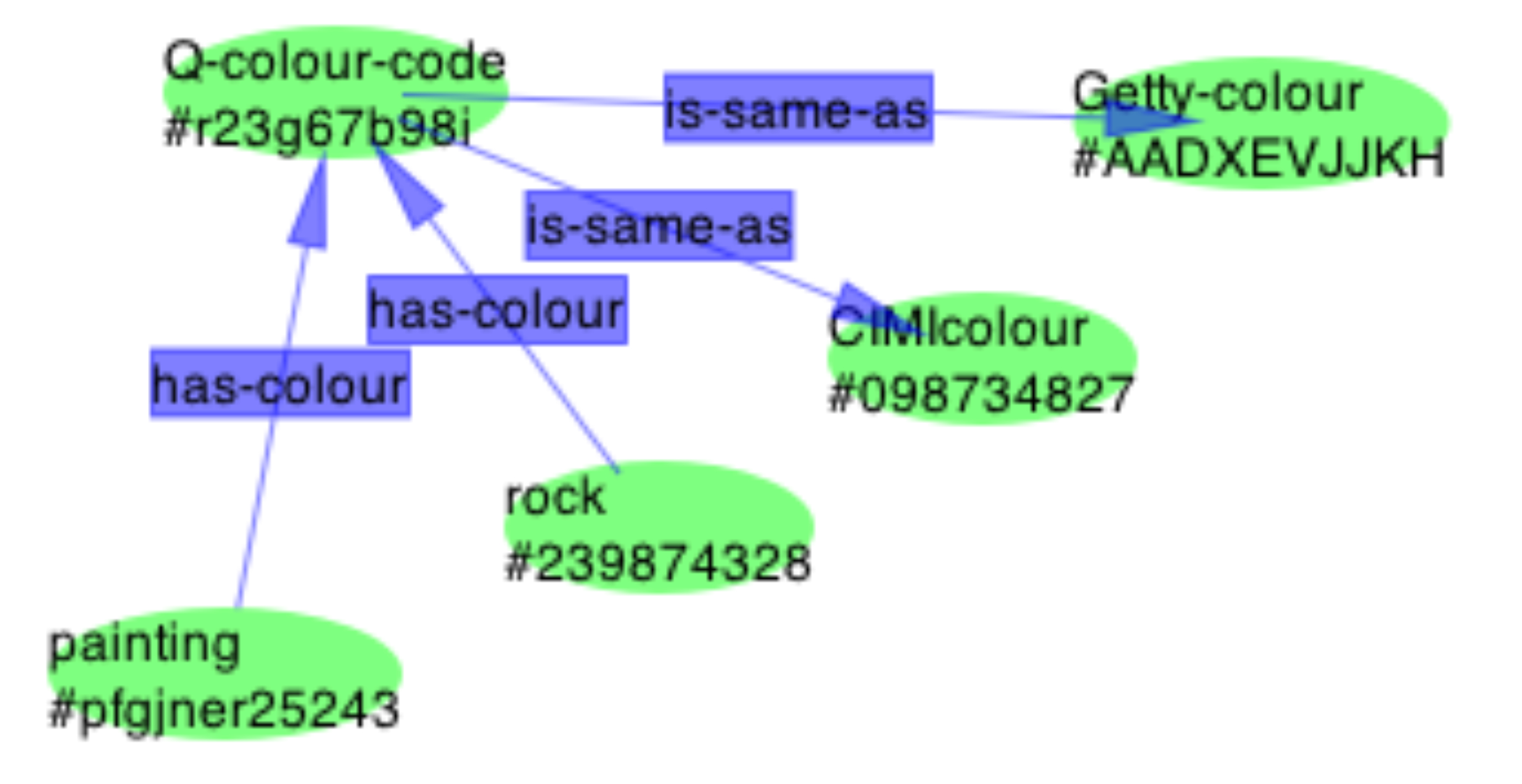
which are combined simply by overlaying the matching entities Q-colour-code #r23g67b98i to form the greater map:
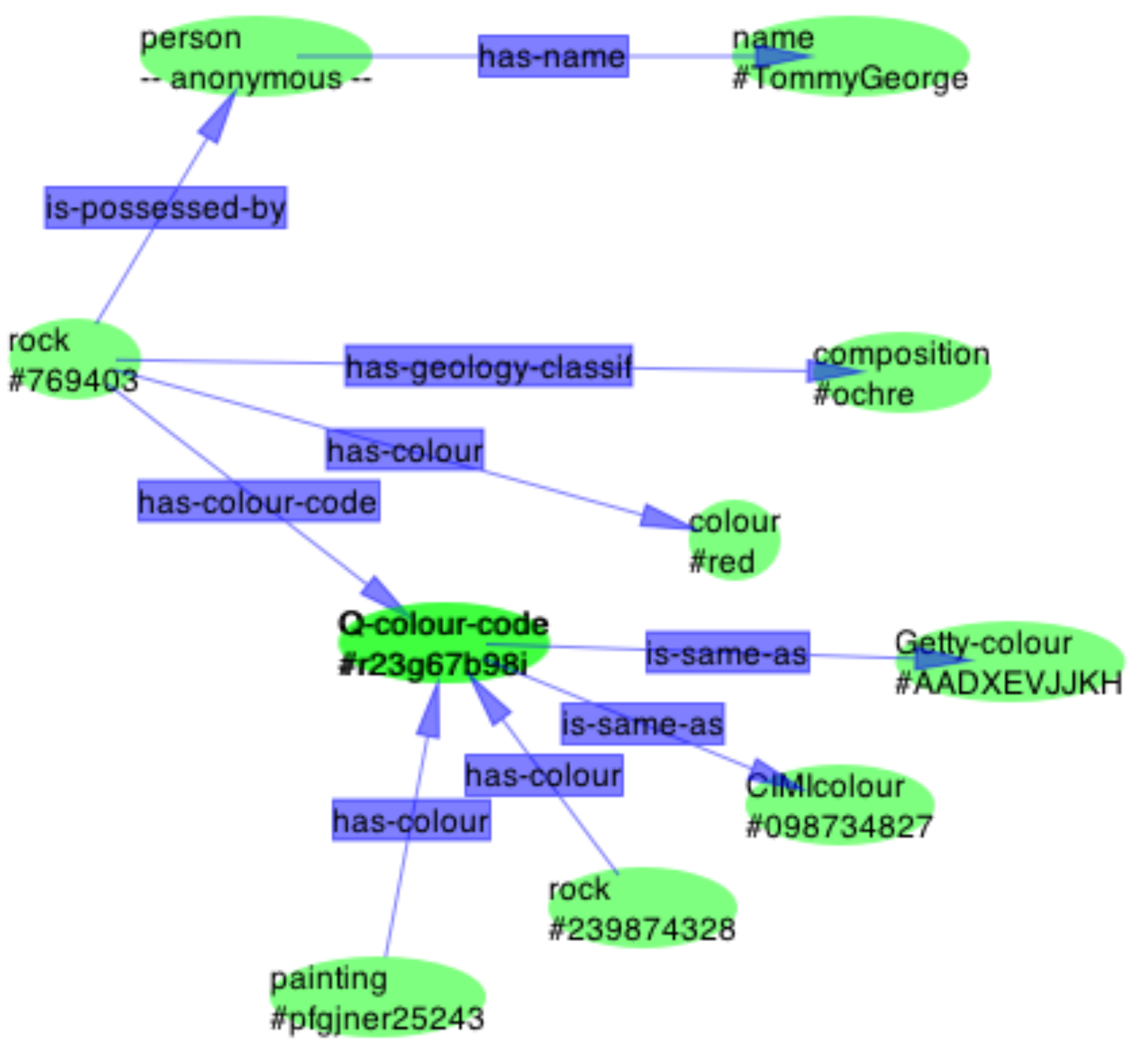
Dr Tommy George: "A lot of paintings are made in red." (Nevile & Lissonnet, 2003)
One of the features of graphical maps that is of interest to those with vision disabilities, and many programmers, is that graphical programming is, when undertaken with the right tools, simultaneously graphical and textual. This is the same as for traditional geospatial maps, where databases often hold the data and where they can be interrogated by users who do not choose to work graphically (sometimes just because of the complexity and enormity of the graphical representation). This is also typical of the way CAD designers work.
Queensland University of Technology (QUT) has a system in which they not only use metadata, but provide what they call a map of it. The following is a QUT metadata map of a three page site.
[QUT]
and they have metadata records that are referred to by interaction with the map, namely by clicking on a link. While it stretches the imagination to call the QUT metadata tool a 'map', or interactive, there is an interactive map that is more common and familiar but less often thought of as that: the browse and inverse browse mapping that appears on many sites as what are often referred to as 'breadcrumbs', for example:
You are here: Home → Standards → Projects → FGDC Standards Projects → Content Standard for Digital Geospatial Metadata (FGDC).
The interoperability of metadata is considered one of its strengths and it has, in its short recent history, led to many institutional digital libraries sharing their metadata to develop what operate as united libraries, following a range of organisational and technical models. Where sets of metadata are to be combined for some purpose, such as integration, if the metadata sets are not based on the same standards, they are often at least able to be mapped from one to the other.
The mapping can be loss-less when the two systems are fully compatible but often this is not the case and some compromises are made. Dublin Core metadata, for example, follows the flat model of one property for each metadata statement and all properties can be repeated and none but the identifier of the resource are mandatory. IEEE Learning Object Metadata (LOM), on the other hand, is deeply hierarchical that is, a property can also have sub-properties and the sub-properties can have their own sub-properties. Mapping from LOM to DC metadata is not possible without loss at this stage, in general, although it is possible to do some mapping from LOM to DC when RDF encoding principles are applied (not the general case).
This is discussed in greater detail later (Ch ???)
see omnigator!!! it's wonderful - at http://www.ontopia.net/omnigator/models/index.jsp
do we want stuff on this?
| Qualities and Characteristics of Cartographic Maps | Qualities and Characteristics of Electronic Catalogues (Metadata) |
|---|---|
| formal definition of .. | |
| international cartographic standards | international metadata standards |
| search | search |
| browse | browse |
| topology | taxonomy |
| crossing of boundaries | application profiles |
| increased scale | qualifiers |
| decreased scale | |
| visual form - printed map | visual form - screen browse |
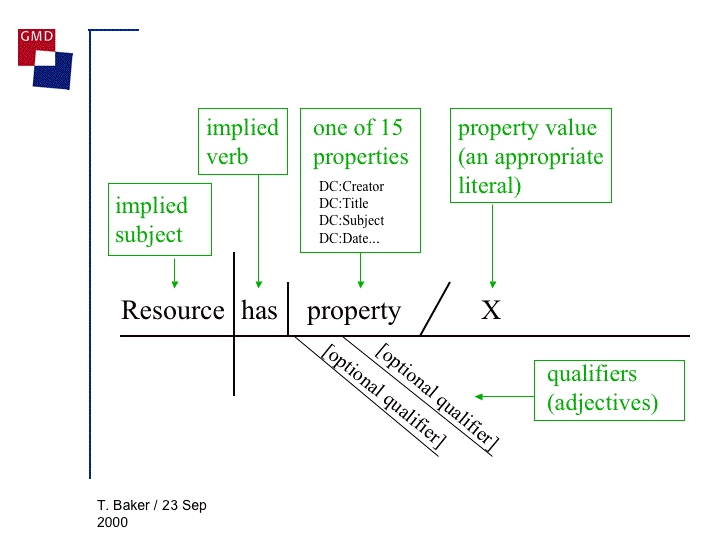
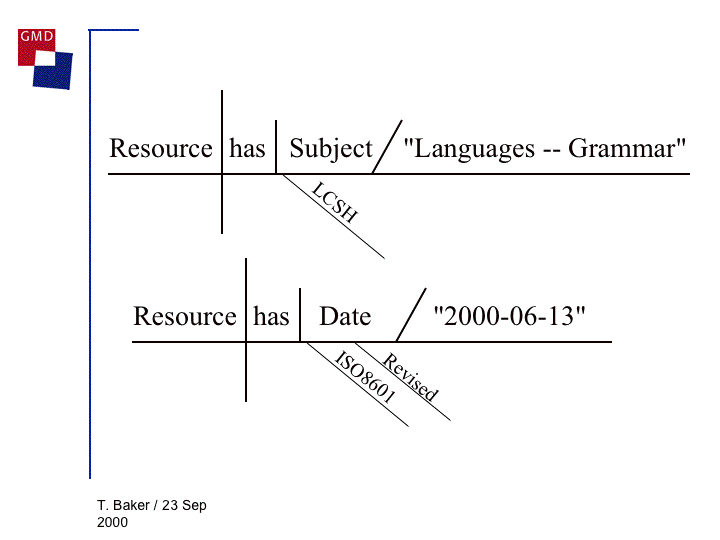
 (
(
{kind=link}