
Site Navigation
Contents of Thesis ack'ments - Introduction - Context - Accessibility - W3C/WAI - LitReview - Metadata - Accessibility Metadata - PNP - DRD - Matching - UI profiles - Interoperability - Framework - Implementation - Conclusion - References - Appendix 1 - Appendix 2 - Appendix 3 - Appendix 4 - Appendix 5 - Appendix 6 - Appendix 7
In this chapter, the various pieces that will form the infrastructure for accessibility come together as a framework for accessibility. In isolation, none of these pieces can make a significant difference, but in combination there is some hope. In the next chapter, how the framework is being adopted is considered. But first, why a framework? What is it and how does it help?
What is the most appropriate framework? W3C provides a set of generalised technical specifications for accessibility, IMS GLC proposes a structure for LOM metadata to support accessibility in that educational sector; Brian Kelly and colleagues in the UK argue for some form of combination of activities in what they variously think of as a mixed model, and then a tangram model, and Andy Heath argues for technical specifications that are 'standards' because otherwise it is too hard. The question remains, is the best framework determined as legal requirements, for objects or processes or organisations?
Providing an accessibility solution to satisfy legal requirements, in the absence of a “single” standard, can involve very complex considerations. Alternative and sometimes conflicting advice abounds and the provider has a difficult task in making choices. Sometimes the choices can be arbitrary. For example there are many ways to make PowerPoint presentations accessible, some better than others, and no obvious single source of advice or way to choose that is best in any particular situation. Solutions chosen arbitrarily, rather than in a generic framework, can also be expensive to administer and maintain.
One effective way to reduce the costs of managing these issues in organizations is with the use of standards. Standards can effectively reduce unnecessary arbitrary variation so that more things are done “in the same way” yielding benefits of scale.
In recent years there has been significant work in technology standards for accessibility including but not limited to the Web Accessibility Initiative’s guidelines and work in IMS. There is now sufficient work for it to be possible to say how some of the standards and practices can be used together in a coherent framework.
One standard likely to be of significant benefit to organizations providing accessible systems and content, both in improving the accessibility of their systems and in reducing costs, is the IMS Learner Information Package Accessibility for LIP 6 (known as AccessForAll or ACCLIP). This specification provides an effective way for a learner’s accessibility preferences with respect to display, control and content, to be recorded in a standard way. This important specification is ideal for development as a British Standard to provide one plank in a framework for implementing solutions to comply with the DDA Part 4. The central recommendation of this paper is that this specification be localized with an application profile to meet UK requirements.
During the process there would be opportunity to consider other related specifications such as the CEN-ISSS Learning Technologies Workshop Agreement on the Description of Languages Capabilities 7 and to develop some Best Practice recommendations in terms of Codes of Practice, roles of accessibility organizations in content and systems certification and some specific media usage recommendations and practices. Work on the latter items could be useful in providing opportunities for greater engagement of organizations participating in developing the standard and help with take-up after publication.
Though the context has been described in terms of educational systems it is likely that parts of such a standard would be useful beyond the educational domain for example in the provision of general content and public-facing government systems.
A British Standard addressing these matters could provide some steps towards a coherent framework for content and systems needing to meet the requirements of the DDA Part 4 and at the same time improve the accessibility provision for all (Heath, 2004).
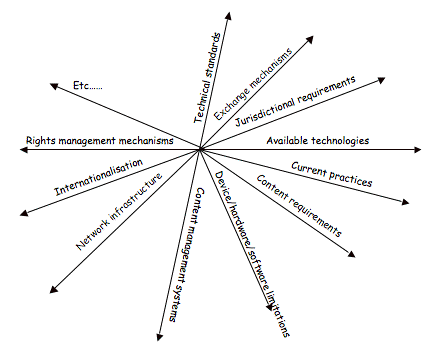
Some of the many dimensions that are necessarily considered in the development of a framework.
----------------------------------------------------------------------------------------
A generalised system for growth?

-----------------------------------------------------------------
From  to
to 
"Interoperability Standards Framework for the SOCCI" slides by Jon Mason - 2001 see http://www.thelearningfederation.edu.au/ tlf2/sitefiles/images/brochures/archive/interop.ppt
-----------------------------------
There are many reasons why metadata is needed to increase accessibility for people. This idea was tested at an international workshop held in Brussels in 2005 as part of the work associated with the development of the AfA metadata (Ford & Nevile, 2005). The reasons agreed upon by the participants follow a short description of the group that developed them:
A Special Workshop on accessibility was held in April 2004 with thirty international experts from the field of accessibility attending. The focus of the Workshop was to arrive at scenarios of current situations in this field in order to develop a plan for further work. Participants spent time thinking about what accessibility metadata needs they could identify in their experience and what solutions they were aware of that might help solve their, or others' problems. The process involved some presentations and the development of scenarios that represented problems. An open-ended list of issues was created.
It was clear from the meeting that there has been a lot of work done to develop technologies and techniques for making accessible resources and services. Participants were challenged to think about the role of metadata in the situation where, as is the case currently, most resources and services are not accessible but nevertheless people are required to function so have to try to use them.
The Workshop participants worked through an agenda that had them refining problems and issues. The documents at Annex C represent the range of documents produced in the process. The content of the many documents has been analyzed and summarized in the main report. The first documents collected were pre-seminar statements from participants explaining their interest in a seminar on accessibility metadata. These were followed by small group definitions of people who might need to be considered. Following this, participants developed comprehensive scenarios and considered the issues they raised. Finally they considered possible solutions, available and being developed and outstanding issues.
A specific problem for people when thinking about accessibility is to separate the role of those who develop the technologies and techniques from that of the metadata. Another was associated with the advances being made in the field of metadata, particularly the use of metadata in what is known as the ‘Semantic Web'. Machine readable and usable information is the distinguishing feature of Semantic Web work that increases the need for standardization of ways of describing people's needs and resources and services.
In addition, it is often hard to distinguish between needs with respect to digital resources and services and physical objects and contexts. Conventionally, metadata is used to describe digital objects and the familiar model of description for physical resources, such as books, is carried across to the field of description of digital objects. Many digital objects, however, are closely linked to physical ones.
A movie review, for instance, is usually read after having been found as part of a result set when a person is looking for a movie to view. The next question, or perhaps the first, for the person is usually when is the film on and where. In cases where the person has a disability, the answers for this query that are likely to be of interest are only those that point to viewing the movie in a location that is physically accessible. Quickly it becomes obvious that accessibility of physical locations is of major concern to people with disabilities, and so metadata describing them should be made available.
A number of scenarios were developed during the Workshop. One of the outstanding themes was the repetition of discussion about the need for a framework for accessibility and CLA to show what needs to be achieved in order to adopt a sensible policy on this issue. A number of organisations are working on aspects of the problem but there is not a unifying agency that is supervising the transition/distinction of work on metadata from work on technologies and techniques. While cooperation is a feature of the work done by those concerned about accessibility, coordination is a problem. Funding for such an activity is not forthcoming because what funding there is, is consistently directed towards solving a particular problem, depending on the goodwill and generosity of others to help coordinate the work.
NEED 4
A framework for accessibility and CLA This framework requires a set of guidelines for metadata to help the implementer maintain interoperability, meeting the needs of accessibility for all at all times, while considering locally specific and relevant aspects. The W3C Semantic Web programme would form part of this framework.
NEED 5
The need to ensure that Dublin Core is actively involved with the work of such groups as EuroAccessibility, IMS Global Learning Consortium, W3C/WAI, INCITS V2, the Semantic Web programme of W3C, and more.
NEED 6
Location-specific access metadata elements to describe physical locations and access to them. This could include contexts that necessitate special user profiles. Examples include where a context has special characteristics such as that there is a high level of noise and sound features of resources and services will not be audible, or there is a safety need for gloves so that fine motor-coordination will not be available for use of keys and a mouse.
A person, who wishes to see a film in a cinema and needs wheelchair access in order to do so, is not very interested in being told how many places are showing the film but have no access for them. They need to know if there is wheelchair access and if there is a space available to them.
A person who has to make considerable effort to get to an automatic teller machine does not want to find that it is physically beyond their reach. They need to know if the machine is accessible to them.
A blind person does not want to be directed to a graphical kiosk and a deaf person does not want to be told to listen to the recorded descriptions for interpreting a museum display. They need to know what is available to them.
In many cases, the providers have taken time to make their services or locations accessible but it is just too hard to find out that this is the case, so people avoid the services or locations for fear of finding them inaccessible. Making location specific metadata will allow providers to offer a more refined search.
NEED 7
A way to record and store information that describes the access needs of users. A student with disabilities and so special needs using computers on a university campus needs the computer being used to automatically be configured for their use and to revert to a default state for subsequent users. Providers of computing facilities and content needs a convenient way to discover what is required for them to be able to satisfy a user's needs. Information about a user's needs should be in a standard form to ensure its inter-operability.
NEED 8
A tool that allows a student considering embarking on a course to determine the accessibility of the course content and to assess what will be required to make the course fully accessible to them. The course providers need information that will allow them to make accurate assessments of the work required and the cost of such work and the chance of success of any work to be undertaken. Such information should be in a standard form so that it is interoperable.
As part of the process of identifying possible solutions to problems, several presentations were made to show what is possible and what is already being developed. Industry Canada initiated work that has now been adopted and supported by many and should emerge as a standard in the field of accessibility. The following scenarios illustrate some of the possibilities.
NEED 9
A member of the public goes to their local library to find some specific information and is directed to the government information service available there on the computers. An assistant sits with them to help them find what they need. As this is the first visit, the assistant runs through a series of tests to determine what will be suitable in terms of control, display and content, for this person. The assistant adjusts the display so the person can see what is on the screen, and when all is well, records the person's access profile. Once this is done, the assistant is able to show the person how to use a search engine that takes account of the profile, including in the enquiry terms relating to language density and transformability, to focus the search for information that is particularly geared towards that person's needs. Suitable content is found and, having been reviewed on the screen, is made available to the person in large print for them to take away.
It is hard to see how accessibility needs can be met without this user profile approach. No two people are the same according to some neat, generic class, and no person is the same in all contexts. Having a multiplicity of profiles related to contexts makes it possible for a person with disabilities to use one that is appropriate at the time, including one that takes into account that as it is late in the day, they will probably be extra tired and able to exert less effort.
All scenarios describing user needs point to the need for standardised metadata as the means of recording user profiles and metadata on the resources and services that allow for the recording of data on language density and transformability.
Another aspect of metadata use that emerged as significant was the way in which Semantic Web technologies are helping solve problems. Third parties are often required to increase the accessibility of resources and this can be achieved by having a system that associates annotations with the original content and then uses those annotations to transform the original content. This has been done with content for dyslexic people but needs to be made available for the range of needs and preferences. It depends, in the end, on Semantic Web technologies to help transform the artistic or ‘semantic' part of the content. For example, an item containing a rich text section describing a bed of tulips by using a metaphor associated with a well-known landmark in Warsaw may need to be replaced by an image of the range of reds available in flames to demonstrate equivalent meaning. The connection between the flames and Warsaw may not be direct, but determinable by reference to the Semantic Web (Ford & Nevile, 2005).
---------------------------------
The definition of accessibility implied here is that the relationship between the user and the resource is one that enables the user to make sensory and cognitive contact with the content of the resource. This is expected to occur at the time of accessing the resource or, in other words, to be achieved just-in-time. This is the definition being advocated by the IMS Global Project's Accessibility Special Interest Group and supported in a growing number of communities. It is known as the AccessForAll definition of accessibility (http://www.imsglobal.org/accessibility/).
In addition to the availability of the necessary components to satisfy the relationship required by the user, there is a requirement for the metadata that will be used to arrange the final composition of the resource. There is also, of course, a need for a way of communicating the requirements, or the metadata. The vocabularies and common specifications for their description are the topic of this paper. W3C is working on similar issues in their Device Independent Working Group and their focus is on what they call the Composite Capabilities and Personal Preferences specifications (http://www.w3.org/Mobile/CCPP/). Collaboration between IMS and W3C will hopefully mean these developments will work together.
4 A user needs and preferences application profile
It is obvious from the discussion above that in order to match a resource or service to a user to achieve accessibility, there is no need to identify the user. All that is required is machine-readable information about their needs and preferences.
The Dublin Core practice of creating a set of elements for use where those elements come from already established element sets is known as the process of creating an ‘application profile'. An application profile for user accessibility needs and preferences that satisfies the requirements needs to contain one vital element; the DC:identity of the information (resource) expressed as a URI. This URI must, therefore, point to the user's accessibility needs and preferences information which should be in a machine-readable form. Users may like to think of profiles as being associated with certain contexts, for instance the lecture theatre version, or the JAWS lap-top version, and in such a case the profile could be named. So we could find DC:title being used for this. The application profile may contain more DC elements, such as DC:subject, DC:description, DC:creator, etc. None of these need identify the user for or by whom the AccessForAll information will be used. They may, on the other hand, clarify who could take advantage of the profile: for instance, all students in a lecture theatre will probably share the need for large print on the overhead screen. This could be explained in a DC:description element. It may be of interest to know who developed the user needs and preferences profile, so DC:creator could be used to indicate this. The date of a profile might be significant when new versions of adaptive software are released so DC:date may be useful.
Recommended best practice for describing the accessibility characteristics of resources and services is to use the structure and vocabulary developed by the DC Accessibility Working Group in collaboration with the IMS Global Consortium and others. As metadata about resource accessibility characteristics has to be matched to metadata about a user's needs and preferences, best practice for the description of the user's needs and preferences is to use the same structure and vocabulary as for the resource characteristics. The structures and vocabularies for describing the resources and the users' needs are known as the AccessForAll profiles and are described below.
A resource that contains some components that will not be accessible to a particular user will need to have those components replaced, transformed or augmented by the time of delivery of the resource to the user. An intelligent service will be needed to determine if the resource contains such components, and what to do if it does. It will need to know how to find the alternatives and how to re-assemble the resource for the user. AccessForAll has been designed to work when this information and such applications are available. It should be noted that universal accessibility, without the AccessForAll process, might result in no accessibility for a user who cannot find a matching service that informs them of the availability of an accessible resource.
The information about the components that is needed by the system is what is usually called metadata: a structured, machine-readable description of the component that provides the necessary information. This information can be provided in a variety of ways but should use established vocabularies for describing the relevant characteristics where possible. Where the same vocabularies are used, systems can easily swap and share metadata. If they can swap and share the metadata, they can usually share the components it describes. The metadata is used for discovery and it can be stored in federated repositories, where the owner/creator of the metadata contributes it to a central repository but maintains it, or in distributed repositories, where a central service sends search requests to distributed metadata repositories. Either way, discovery can be enabled across the repositories.
The AccessForAll information model encapsulates the information that is required for accessibility. That is, the information about components that relate to the adaptability of resources and services that can affect their accessibility, explicitly including needs and preferences that relate to human modality, control and content requirements. These requirements are defined to match those specified for the description of user needs and preferences.
As user needs and preferences are often affected by the context in which the user is operating, such as when conference participants all need large font text in projected presentations, compared with when they view the same content on a private computer, an individual will use a set of needs and preferences descriptions and also want to be able to change them dynamically. On the other hand, there is no personal information in these descriptions. They do not need to identify the user or any disabilities they may have. The needs and preferences descriptions can usefully be stored and made available on the Web, on smart cards, or otherwise.
As the metadata needed is quite detailed, there may be some concern about who will produce it. Even where the metadata is created by a well-intentioned party, there may be a question about how reliable it is. Fortunately, there are a number of applications available that help with the description process and even do some of it automatically. Most of these produce their reports in a language called Evaluation and Report Language (EARL http://www.w3.org/TR/EARL10/ accessed 15/9/2005) that requires all statements to be identified with a time and the person or agent making them. This makes it easier to identify the source of the description for trust purposes. EARL statements are generally intended to convey information about compliance to some stated standard or specification. This information is typical of what is needed for accessibility. An example is an EARL statement that includes information about the transformability of text determined by reference to the relevant WCAG provisions.
The World Wide Web Consortium [W3C] has a working group dedicated to bringing together the technologies necessary for adaptability and accessibility. They show the overlap between adaptability (which they call ‘device independence') and accessibility with the following example:
Pat has been given the task of booking the evening entertainment: a musical event followed by a good meal. On the Web, Pat discovered several potentially good venues but found it hard to follow the details on the pages because there was too much text with insufficient navigation. The form to book the restaurant was the hardest, requiring Pat to type everything instead of selecting from options.
Which of the following is Pat?
Patrick is a radio presenter who is partially blind and has limited use of his hands. Although he uses a screen magnifier and sometimes a screen reader, he finds many Web pages difficult to follow. Web forms are his biggest problem because they require him to do a lot of typing, which is understandably difficult.
Patricia is a marketing manager who is always on the road. Her constant companion is her cell-phone, which is equipped to access the Web. She finds that the Web pages she wants to view will not work on her device. Of those that work, there is too much text to be able to read properly, and Web forms require too much typing with the miniature keyboard.
W3C developed Composite Capabilities and Personal Preferences protocols (CC/PP CC/PP Information Page, http://www.w3.org/Mobile/CCPP/ accessed 15/9/2005 ) “to permit the conveyance of device characteristics and user preferences. This information may include details of assistive technology incorporated into the browser, and specific user requirements such as the preference for text instead of graphics” (according to the W3C DI Working Group). CC/PP and other W3C languages such as EARL, make it possible to convey the accessibility information in standard, machine-readable ways.
Other metadata standards, of which there are many specially for describing components in ways that enable discovery, will need to be used to identify equivalent alternatives and supplementary components in cases where modal alternatives are not available. Users seeking resource by subject, author, date, coverage and many other facets will use other metadata for this.
Metadata standards, which determine the ‘semantics' or information models for the descriptions, also use standard syntax and languages to encode the metadata. The standardisation of the syntax makes it possible to mix and match metadata: pieces of description for a range of sources can be combined in a single metadata record if they are encoded in standard formats.
In general, the first step in matching resources and services to needs and preferences of a user is to discover the needs and preferences of the user. The second step is to determine if there is a cause for concern: are there components that use what might be difficult modalities according to the identified needs and preferences? If so, are there alternatives available for these components? If so, is their identity available? (The alternatives do not need to be co-located with the main resource components or even produced by the same developers. The alternatives may not yet exist but be able to be generated.) If the alternatives are available and identified, are they suitable? This is a repeat of the first question but with respect to a component instead of the whole resource or service. The process continues and if the needs are satisfied, the resource is re-formed using them. If not, it may be necessary to work with compromised components or to find another resource and start the whole process over again. (Such a decision will be handled according to the particular implementation being used.)
Accessibility, dependent on the successful matching of resources and services to user needs and preferences, does not have to define syntax for its representation. That is well provided for by other fields of endeavour. Accessibility has to concern itself with the personal aspects of adaptability and how these can be organized and described. The adaptability metadata model, with an information model such as the AccessForAll model, can be incorporated into the general adaptability framework when the relevant information about the user's needs and preferences and the relevant information about the resource and its components are represented as metadata.
This paper proposes a significant shift from former approaches to accessibility that focus on the isolated resource or service, attempting to judge accessibility in isolation from the individual user, and not identifying what will suit the user even where accessible components are available. It exploits the potential of metadata to be used in dynamic customization of resources, significantly increasing the flexibility offered by many designing with the user in mind. The new approach does not avoid the need for accessible components but it allows for them to be distributed and cumulatively developed, significantly increasing the publishers' potential to provide accessible resources and services. It depends upon a framework of metadata embodying the adaptability of resources and services that allows for management of the resource and service components in relation to the needs and preferences of individual users at the time of using the resource. The approach proposed is demonstrated in an online system at the University of Toronto called The Inclusive Learning Exchange (TILE).
The following table represents the layers that form the AccessForAll framework. Different people and processes and products are involved in the various layers. It clarifies the need to move beyond the common situation where there is, at best, a champion of accessibility somewhere in an organisation who tries their best to ensure that what is published is as accessible as possible.
| Layer | Name | Description |
|---|---|---|
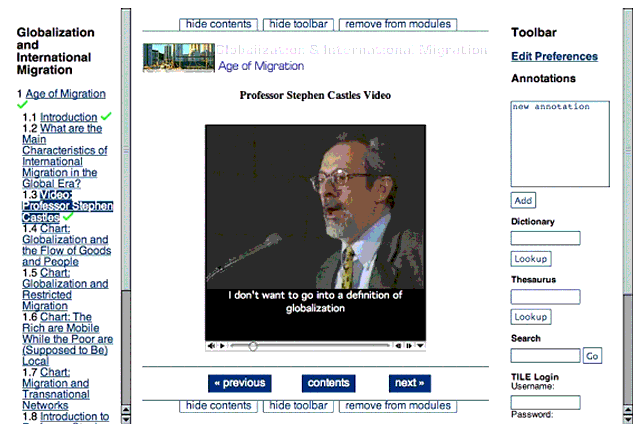 |
Delivered resource in form that is fully accessible to the individual user. | A TILE-delivered Web page accessed 14/12/2004. Any user who requests the page will receive a version that is comprised of components that they can or choose to access. There will not be components that they cannot access and do not have information about. |
| <?xml version="1.0"?> <accessForAll xmlns="http://www.imsglobal.org/xsd/acclip" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.imsglobal.org/xsd/acclip AccessForAllv1p0d27.xsd"> <context identifier="TILE" xml:lang="en"> <content> <alternativesToVisual> <altTextLang xml:lang="en"/> <longDescriptionLang xml:lang="en"/> <colorAvoidance> <avoidBlueYellow value="false"/> <avoidGreenYellow value="false"/> <avoidRed value="false"/> <avoidRedGreen value="false"/> <useMaximumContrastMonochrome value="false"/> </colorAvoidance> </alternativesToVisual> </content> </context> </accessForAll> |
AccLIP | Examples from http://www.imsproject.org/accessibility/accmdv1p0/imsaccmd_bestv1p0.html accessed 17/12/2004. An encoded description of an individual user's needs. |
Preferences |
User needs and preferences selection page | Taken from TILE preferences page at http://www.inclusivelearning.ca/tile/servlet/prefs accessed 14/12/2004. A user who changes their needs or preferences while viewing a resource will be able to change those parameters immediately and receive an adjusted resource, where necessary. |
<accessibility xmlns="http://www.imsglobal.org/xsd/accmd"> <resourceDescription> <equivalent supplementary="false"> <primaryResource> urn:uuid:2b449e70-424a-11d8-a524-0002b3af6db8 </primaryResource> <content> <alternativesToVisual xmlns="http://www.imsglobal.org/xsd/acclip"> <longDescriptionLang xml:lang="en"/> </alternativesToVisual> </content> </equivalent> </resourceDescription> </accessibility> |
Equivalent resource profile | An encoded description of a resource that can be matched by a user (or thier agent) to the individual user's chosen needs and preferences profile. |
| <accessibility xmlns="http://www.imsglobal.org/xsd/accmd"> <resourceDescription> <primary hasText="true" hasVisual="true" hasAudio="false"/> <equivalentResource> urn:uuid:55b210d0-922f-11d8-a73a-0002b3af6db8 </equivalentResource> </primary> </resourceDescription> </accessibility> |
Primary resource profile | A minimal set of metadata that provides the user (or their agent) with sufficient information for them to know whether or not they will be able to access the main content of a resource. |
Leo's Icon Archive -
10,000+ free icons, desktop icons,
clip art ...10000+ free icons in gif & ico
format. 28 categories. ... Additional free clip art, desktop
icons, buttons, bullets, cartoons, lines, dividers, initial
caps. ... www.iconarchive.com/ - 3k - Cached - Similarハpages |
Content Metadata (Google) | A set of metadata that provides users with the opportunity to select from a number of resources or resource combinations. |
from http://www.humanfactors.com/downloads/accessibletesting.asp accessed 15/1/2005. |
composite Webpages | The range of potential pages from a set of resources, from wherever they are served to the Web, including when they all come from different servers. |
 |
Web objects | If content providers produce well-formed, atomic components, they are easily combined to form composite resources, and their transmission can be free of unnecessary components that may be required if a resource is to be universally accessible. |
 |
content creators | Creators may be working together or distributed. Their content components may be designed to work together or produced entirely independently of each other. For example, one organisation may create a component about an event and it may be useful as an alternative to another component about the same event that is pure video. |
table entries in LH column need formatting....
In this thesis, the major contention is that as the field of Web accessibility has matured, the focus has shifted from intense concentration on code to the role of code, the languages in which code is written, metalangauges that describe those encodings, and finally the practices related to the writing of content and services.
This is, as Jason White observed in his paper presented to the OZeWAI Conference in Melbourne in December 2004 (and the OZ/Chi Conference in November 2004), a continual process of abstraction. White was building on the comments of Gregg Vanderheiden (1997) and observing that what had been done with content markup was also the model for user interfaces and that such abstractions were instrumental in making increased accessibility possible.
As described in this thesis, the development of the URC (see chapter ???) is symbolic of this process. Rather than develop a device with certain capabilities in a given context, the INCITS V2 Working Group focussed on the metadata that would be required to make such devices so that they woud be interoperable.
In his paper, White reviews what he calls the 'technological tradition' of using abstract representations of content (abstractions from content), as he says, "focusing predominantly on the nature and advantages of a ‘single authoring' approach to the creation of content". This is the principle that underlies the development of WCAG, not surprisingly as White was the Co-Chair of the WCAG Working Group and a major author of that document. What is interesting to the author is that while White is praising abstraction, he is caught in the detail, himself very close to the WCAG and maybe not looking at the larger context in which it operates.
The question for this thesis is to what extent such abstractions, while typical of computer science, are equivalent to mappings in a more generic sense, and therefore 'abstract cartography'. In the US it is not uncommon to think of computer science as engineering, in fact as 'abstract engineering'. It is comonly taught in engineering faculties.
Cartography involves finding ways to represent content and ways to represent information about content. The result is usually pictorial although often also textual and certainly so when machines are likley to be required to interpret and use it. The same is true of work in accessibility. The content needs to be in a flexible, one authoring suits all presentations mode, according to the principles of WCAG, but then it needs to be described or represented by type, role, or other attributes, for processing.
White asserts that the shift from immediate 'turn on italics' ... 'now turn off italics' commands throughout a document to descriptions of structure and a related set of instructions as to what to do with different elements of structure, was the big step for accesibility in the mark-up world. This he calls "the move from concrete procedural semantics toward more abstract structural descriptions of the document". He says this was brought about by the introduction of "a distinction between a declarative, structural description of the document, and the operations and parameters needed for its realization by a typesetting system". The former process, of using direct formatting markup, was, presumably, a procedural approach to content that made the production of content all part of the process. Now, the content is a combination of objects and there is a manifestation of that content when it is presented, whether on a screen, printed, voiced, or rendered in Braille. This manifestation, according to White, involves "the conception of an electronic document as instantiating a formally defined grammar, a so-called ‘document type', to use the terminology of the Standard Generalized Markup Language (SGML) [International Organization for Standardization, 1986], and its simplified but more popular successor, the Extensible Markup Language (XML) [Bray et al., 2004]."
The definition of a particular document type was originally contained in what was called a document type definition (DTD) but are now more commonly specified in what is called a schema, often an XML document. Such a document will be machine readable and manifestations of content will be possible when their specification is valid according to the schema. White asserts that the separation of markup languages and the grammar for specifying the process of production for a given manifestation make possible the production of content with markup that is completely independent of the presentation process. This, in turn, means that the presentation process can be developed separately, modified or transformed independently fo the content.
It is this last possibility that promises the most for accessibility. Bring able to work on a proposed production process and modify it introduces yet more flexibility into the process, and it is this that the IMS model has taken advantage of. Instead of associating content with a production process, it allows for that process to be manipulated to suit idividual needs and preferences of users.
To achieve this opportunity, technical development has again taken a step towards the abstract. Stylesheets were originally written as statements that defined the production of content, once it was structured according to the necessary document definition. As soon as these sets of instructions became separate from the content itself, it became obvious that they could be replaced by procedures. So what was originally a grammar for declaring presentation types (CSS) has become a language for describing presentation procedures, XSLT.
White laments that this has not worked as well as it might have because generally the user agents that receive the content use the production information to manifest the content and they are often limited in their capacity. In the common situation of user agents being browsers (such as IE or netscape), in order to increase the capabilities of the agent the re is often a need for additional software, 'plug-ins' to be added to the user agent. This is cumbersome and not always possible so the capabilities remain limited. If, White asserts, user sgeents were more capable they could use production information to offer greater flexinility to the user. He observes that this is unlikel to happen, however, as user agents become more vaied and smaller, as manufacturers need to constrai their software. Instead, he suggests, some of the rendering could be done at the server end, saving the user agent and increasing the flexibility at the device level. He does not consider tht all the work has yet been done: "there is a need to develop more sophisticated document presentation systems, encompassing scalable rendering functionality suitable to a variety of devices and output modalities, and high-level style languages for generating optimal presentations of content in a range of delivery contexts".
It is necessary at this point to recognise two things:
White continues:
"Promising work has recently been carried out in extending the basic approach to interfaces which, unlike static documents, accept input from the user and undergo modification, whether in response to input or other changes in the state of a program, as application software is executed." While the point that White is trying to illustrate is clear, the examples do not include the work described in this text to do with enabling servers to match resources to users' needs and preferences and deliver, in real time, what suits the user. That this has been implements in a dynamic system where it is possible for the user to change reauirements after having received content, and so get a new version of the 'same' content, makes it another clear example of what White is talking about.
So the author wishes to add to the two specifications of interest to White, the third set of AccessForAll Learner Information Package (AccLIP) and the Accessibility Metadata AccMD) specifications (IMS, 2004). White referred to the specifications for XForms (XML Forms Language - Dubinko et al., 2003) and the draft Protocols for a Universal Remote Console currently under development by the INCITS V2 working group [InterNational Committee for Information Technology Standards , 2004a,b,c,d,e], which are described earlier in this text (see ch ???).
White draws the analogy between the WCAG approach to content and the work of the XForms and URC specification developers and comments:
Most user interfaces designed today are written in a conventional programming language, with a quite specific delivery context in mind, for example a graphical workstation, and are carefully designed for the intended environment. Other delivery options are, at best, treated as secondary concerns: a user interface library may, for instance, support accessibility via assistive technologies that provide alternative input and output mechanisms for people with disabilities, but the graphical interface remains the primary focus of the design. What distinguishes XForms and the Universal Remote Console specifications is the achievement of a more adequate demarcation of the underlying structure from those aspects of the user interface which vary with the delivery context, while allowing additional resources to be specified that enable the interface to be automatically enhanced or customized for specific environments. (White ???)
He argues that "Furthermore, this generic approach challenges the traditional distinction between user interfaces as such, intended to be operated directly by human beings, and application interfaces exposed to external software." The present author agrees and wishes that the separation could be valued and replicated in other contexts, such as with respect to content creators who should be encouraged to save time and money and buy good authoring tools instead of spending huge amounts of time and money on training to write raw code.!!!!
White says that: "In short, it is partly through making the user interface amenable to automated as well as human interaction that the technological future which Vanderheiden imagines can become actualized." he refers to Vanderheiden and Zimmermann's description of the URC and show that there are now physical working examples of these principles.
-----------------
In considering the case for the use of WYSIWYG editors for publishing and the old fashioned approach where the content provider markedup the content and the setter applied rules to it, Conrad Taylor (. points out some of the side-effects of the adoption of WYSIWYG editors that may explain their popularity. As an expert publisher, he comments that:
.. a WYSIWYG paradigm certainly gives control, but also makes you responsible for the low-grade task of making sure all these bits end up in the right places. Surely it would be better to surrender that low-level control in favor of greater automation? Putting it another way: Wouldn't it be better to move control to a higher level of generality -- such as rules for how side headings behave -- and forgo the need to exert control over minutiae (unless you really want to make such local alterations)?
he points out that the advantages of WYSIWYG apply most particuilarly to smaller content objects - when there is a large object:
Analyzing structure saves time. It helps to get the best out of a program like Ventura or FrameMaker if you are prepared to analyze the structure of your publication carefully, matching each element type with a style-sheet item, variable or other generic construct. It takes longer to set up a new document type this way, but you save time in the long run by not having to interact with document elements at a low level.
Later he says that in fact people are finding reasons for wanting the structural markup approach with freedoms about del;ivery and mainly this is because, as Nicholas Negroponte says, newspapers may evolve into this form:
Imagine an electronic newspaper delivered to your home as bits... The interface solution is likely to call upon mankind's years of experience with headlining and layout, typographic landmarks, images, and a host of techniques to assist browsing. Done well, this is likely to be a magnificent news medium. Done badly, it will be hell. ..
[B]eing digital will change the economic model of news selections, make your interests play a bigger role, and, in fact, use pieces from the cutting-room floor that did not make the cut on popular demand. ... Imagine a future in which your interface agent can read every newswire and newspaper and catch every TV and radio broadcast on the planet, and then construct a personalized summary. This kind of paper is printed in an edition of one. [Negroponte, 1995]
he also points to certain document types that don't make so much sense in an electronic era in a fixed content format:
There are also certain reference publications that do not make sense as printed volumes. Encyclopedias and dictionaries are out of date the day you buy them, if not before. Bus, train and airline timetables -- ditto. It would be more logical for these publications to be online where they can be kept up to date, perhaps charged to readers on a pay-per-view basis.
Taylor was wiritng in 1996 but little has changed in this sense. the flexibility that he was imagining is exactly the same as that now being offered using the AccLIP and AccMD specifications and a system such as TILE. he concludes:
The thing that makes these publications special is that they may never have been typeset before you request them to appear before your eyes, for two reasons:
• Some documents won't exist until you ask for them, such as custom collations from a TV listing or a classified ad database. [what Taylor proposes might be called "smörgåsbord publishing"]
• The variety of means of delivery argue in favor of the "late binding" of typography to semantic structure, to suit the characteristics of the particular delivery medium. The document may be viewed on a pocket computer with a monochrome lcd screen or a desktop computer with a color screen, or after it has been printed onto paper from a fax machine or a high-resolution laser printer. Each instance should look and behave differently. (You can't read 8-point Bodoni on a screen or fax, and you can't scroll or hyperlink to notes on a paper page.)
If the results are to be "magnificent" rather than "hellish," we will need to rely on intelligent typesetting and pagination on the fly -- the return of batch formatting, perhaps along the lines of how TeX does it.
Taylor concludes with a call for smarter software so that there is better replication of the now largely obsolete human functioning of doiong such things as getting the hyphens right, and so the software does this. He was writing 10 years ago. What has changed? the techniques for making the content both WYSIWYG and styled have emerged. The best of both worlds is here but nobody uses it! The styles are in Word etc - but the lousy code it produces off-sets the benefits. Dreamweaver offers both but people are wedded to Microsoft for the price - as well as soetimes the quality of the products - mostly price and familiarity ...