Chapter 11: Interoperability
Introduction
In this chapter, interoperability is considered as the essential characteristic of fully functional metadata. It is relevant both at the level of semantics, where an additional resource may be sought and all that is available for the search is additional semantic metadata; and at the level of syntax and structure, where the semantics need to be machine processable. It is argued that interoperability is a form of elegance, making for simpler but more powerful metadata. So first, why it is so important is considered. Then, the difference between hierarchical metadata of the kind developd so far for AccessForAll by the IMS and ISO working groups is contrasted with metadata of the kind that complies with the Dublin Core model, and the Semantic Web is discussed.
Much of the content of this chapter has been contributed to co-authored
journal article (Nevile
& Treviranus, 2006), a co-authored paper presented
at the World Summit on the Information Society [WSIS
2005] conference in Tunisia (Nevile
& Mason, 2005), and the development of the ISO/IEC standards 24751 Parts 1-3, 5-6, for AccessForAll accessibility, and 19788 Part 1 (refs???). A significant amount of the chapter was submitted to ISO/IEC JTC1 SC36 WG4 as WG N???
The adoption by ISO/IEC JTC1 SC36 of a new model for metadata for Learning resources has resulted from significant work on the part of the author and others, and will be extended into a revision of the AccessForAll N24751 standard (ref???).
Background
AccessForAll fits within a framework for educational accommodation
that supports accessibility, mobility, cultural, language
and location appropriateness and increases educational flexibility.
Its effectiveness will depend upon widespread use that will
exploit the ‘network effect' to distribute the responsibility
for the availability of accessible resources across the globe.
Widespread use will depend upon the interoperability of AccessForAll
which, in turn, will depend on the success of the four major
aspects of its interoperability: structure, syntax, semantics
and systemic adoption. The last criterion, systemic adoption,
is added here deliberately to the convention trio of criteria
(Weibel
et al, 2002).
There is no doubt that an important aspect of achieving
interoperability is the widespread adoption of common solutions
to problems. Another important aspect, easily forgotten, is that interoperability means not only that different systems can use the same information, but that computers themselves can use it. Humans who have somewhat different ways of recording information about resources can develop transformations so that what is said one way can be reformed so it is said another way. This can be done completely, losslessly as librarians say, or with some tolerable loss. The acceptable level of loss is a question of choice but in the accessibility context, for poeple who are dependent on the information being exact, losslessly is the only way.
In the case of educational resources and
services, there are many major communities concerned with
relevant aspects of descriptive standards and of those, a
number have been engaged in the development of the AccessForAll
model. Cross-domain metadata also has well-established standards
need to be considered. The best model for accessibility information will be one that is based on a set of
principles that, when implemented in a variety of standard
languages or systems, maintain their interoperability
at syntactic, structural and semantic levels (including machine comprehension of the semantics). It also depends
upon widespread systemic adoption to generate the volume
of accessible components required.
The AccessForAll strategy complements work to determine
how to make resources as accessible as possible done primarily
by the World Wide Web Consortium Web Accessibility Initiative
[WAI]. The focus of
that work is technical specifications for the representation
and encoding of content and services, to ensure that they
are simultaneously accessible to as many people as possible.
W3C also develops protocols and languages that become industry
standards to promote interoperability for the creation, publication,
acquisition and rendering of resources.
The focus of AccessForAll is ensuring that the composition
of resources, when delivered, is accessible from the particular
user's immediate perspective. It complements the W3C work
by enabling a situation where a particular suitable resource
is discoverable and accessible to an individual user even
when it may not be accessible to all users. In some cases,
this may mean discovery and provision of alternative, supplementary
or additional resource components to increase the accessibility
of an original resource. The distinguishing feature of AccessForAll
is that it assembles distributed, sometimes cumulatively-created,
content into accessible resources and so is not wholly dependent
upon the universal accessibility of the original resource.
The AccessForAll specifications, while initiated in the
educational community, are suitable for any user in any computer-mediated
context. These contexts may include e-government, e-commerce,
e-health and more. Their use in education will be enhanced
if they are adopted across a broad range of domains and used
to describe the accessibility of resources available to be
used in education even if that was not their initial purpose.
The specifications should also work equally for users of fixed and mobile devices, of whatever size or shape. They will need to be useful for metadata development for use in a number of
ways, including: to provide information about how to configure
workstations or software applications, to configure the display
and control of on-line resources, to search for and retrieve
appropriate resources, to help evaluate the suitability of
resources for a learner, and in the sharing and aggregation
of resources.
The AccessForAll specifications are designed to gain extra
value from what is known as the ‘network effect': the more
people use the specifications, the more there will be opportunities
for interchange of resources or resource components, and
the more opportunities there are, the more accessibility
there will be for users. Equally, the more the descriptions of the resources are machine comprehensible and usable, the more computers will be able to do the discovery and matching work. That is, instead of humans having to build connections between one system and another, the interoperability of the metadata should attract the computers use of the metadata to make connections not anticipated by humans.
Semantic Interoperability and Information Models
A small section of the IMS version of AccessForAll will be used to illustrate the problems that can occur with interoperability and then the same information will be presented in Dublin Core style, and finally in Semantic Web style. This example is used to discuss semantic interoperability and the problems with the early versions of AccessForAll standards.
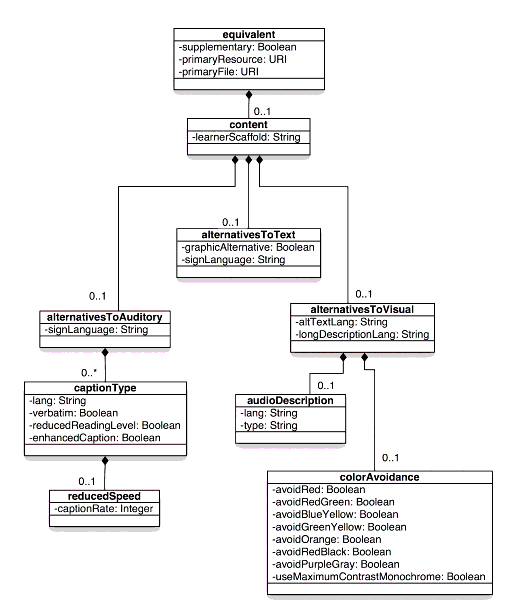
Figure ???: Equivalent Class Data Model. Figure 2.3 from Jackl, A. (2004). "IMS AccessForAll Meta-data Information Model, Version 1.0 Final Specification" p 3 Retrieved November 17, 2008 from http://www.imsglobal.org/accessibility/accmdv1p0/images/imsaccmd_infov1p03.gif
The information to be conveyed is about the range of possibilities that may describe a resource that is to be used as an alternative to a given resource. The information model is set out to be read one step at a time. For example, it may be read as follows in a particular instance.
This resource is a 'primary' and is available at http://321.321.321.321 (let's say it is a video). There is a supplementary resource, located at http://123.123.123.123. The secondary resource provides an alternative component for a visual component of the primary resource. That alternative component is 'black and white' and thus avoids distinctions being perceivable only by comparison of colours in such as 'red-green combinations'. The alternative component also avoids any use of subtle differences in colour and thus has maximal contrast. Incidentally, it also satisfies the case of not having red, of not having blue-yellow comparisons, etc.
In other words, red-green comparisons are avoided in the colour combination of the (alternative) visual component in the secondary resource that is a supplementary alternative to the primary resource.
The process of 'reading' the information is one of following down the hierarchy. The colour avoidance criteria that occur deeply embedded in the description of the supplementary are the same criteria that would have been used to determine the characteristics of the primary resource, but they are somewhere else on the hierarchy (a lot higher up and then down another branch). To discover the colour combination information about the alternative, it is necessary to work one's way down to that information. In order to make this information machine readable, it is necessary to have 'bindings' that distinguish the description of a supplementary resource from that of a primary resource, for example. Such 'bindings' provide a way for a computer to identify this information, in case it is needed.
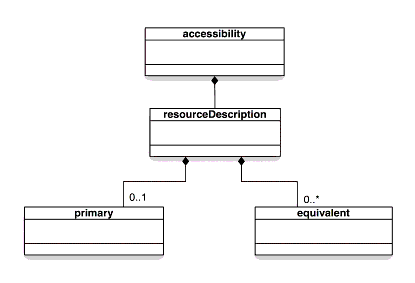
Figure ???: Overall Accessibility Data Model. Figure 2.1 from Jackl, A. (2004). "IMS AccessForAll Meta-data Information Model, Version 1.0 Final Specification" p 3 Retrieved November 17, 2008 from http://www.imsglobal.org/accessibility/accmdv1p0/images/imsaccmd_infov1p0a.gif
Another way to think about the information is to think about resources and their description and then add the relationship between them. In such a case, one might think of all the types of things that should be said about a resource. These could then be said about any resource in the same way, whether it is a 'primary' or a 'secondary' resource (Figure ???).
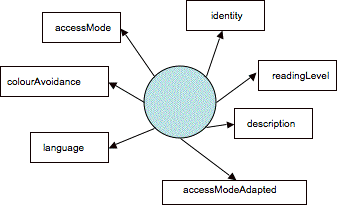
Figure ???: 'Flat' model of characteristics of a resource
One such thing that could be said about a resource is its relationship to another given resource. According to such a model, we might have the following diagram (Figure ???). The large arrow at the top might identify R1 as having an alternative R2, and the bottom large arrow as R2 being an alternative to R1. These arrows would thus simply be describing another property of the resources.
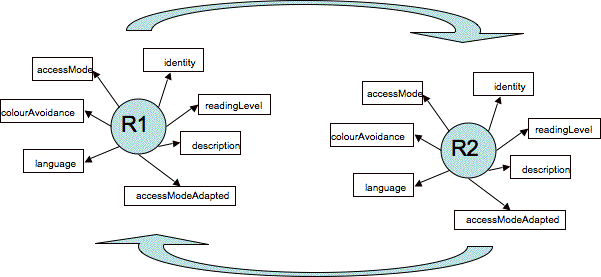
Figure ???: Pair of resources similarly described with relationship evident
In Figure ???, we see that there is no need to distinguish between the way the colour characteristics for a primary resource and those for a secondary resource are described. In addition, the arrows top and bottom, used to represent the relationship between the two resources, can be labelled reflexively: R2 might be an alternative to R1 but it is possible that R1 is thus also a useful alternative to R2 for some users. Given the hierarchical model above, it would be necessary for a human to identify the role reversal between R1 and R2 to take advantage of it. Given the 'flat' model, it would be easy for a computer to discover the possibility.
So perhaps the first thing to note about the difference between a flat model and a hierarchical one is the simplicity of the flat model. This can be confusing. It is achieved not by aiming for an exhaustive model of the information, which the hierarchical model makes explicit, but by the selection of 'core' types of information. This is not easy: all the information must be analysed to discover how it can be grouped so that necessary refinements can be accommodated by the model.
Let us use the example of the two characteristics language and ReadingLevel, as in Figure ??? above. The relevant values for language in the context of accessibility will clearly need to include sign languages, tactile languages and natural languages. Let us suppose we want to be able to distinguish between American and Australian sign language. In a hierarchical model, we'd first determine that it is a sign language and then identify which one. With a flat model, we'd probably replaced language with typeOfSignLanguage. We'd do this by considering language to be a resource, albeit an abstract one, and using the model to make a direct connection to the typeOfSignLanguage, as shown in Figure ???
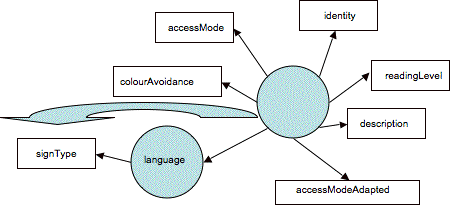
Figure ???:The Flat model accommodates 'hierarchy' or 'composite' elements.
In Figure ???, 'language' has become a resource, simply by being given a digital identity, and it has a set of descriptions, including one that says what sign language type it is, if it is a sign language. What has had to be done to make this possible is:
- an abstract idea has to be given an identity (and so can be defined);
- the idea is defined by its attributes, and
- just as a resource can connect to the idea, it can also connect directly to a characteristic of the idea.
This is how the Dublin Core metadata model works. Arbirtarily, characteristics such as language were chosen as the 'core' characteristics, and in the case of Dublin Core metadata, a rule was established that said any core characteristic could be replaced by a refinement of that characteristic, and such characteristics could be refined in one of three ways:
- with a controlled vocabulary, i.ie a limited set of values;
- by an encoding scheme e.g. that date should be written yyyy-mm-dd, or
- by a characteristic that is narrower than the 'core' characteristic, e.g. sign language type rather than language type.
The use of 'core' characteristics and rules relating to them is a quality of Dublin Core metadata. There are not the same restrictions in the case of the Semantic Web. Whereas originally the Dublin Core 'core' characteristics were chosen arbitrarily, and by consensus, from among those librarians were familiar with, they could be chosen in many ways. A typical set that is often mooted is the 'five W's and H'. The five W's stand for what, where, when, who, why and how is the H. Work on this set is ongoing in the Dublin Core community where it is known as the 'kernel' set (ref???). Concurrently, the notion that the 'core' is a fixed set of fifteen terms (as they are now known in the DC world) is being discouraged energetically by DC afficionadoes (ref???).
The notion of core characteristics, and then rules to control how they are extended, is used in the DC model to promote interoperability. Where two systems are not using exactly the same metadata schemes, but are using schemes based on the same DC model, if one term is more refined than another, it can be 'gracefully degraded' back to being treated as a value for the core term. The effectiveness of this is dependent on the refinement rules and their application in the context. As Dublin Core requires all terms to be defined and their relationship one to anther to be defined, and all these definitions to be available on the Web, computers can always access them and perform the necessary functions to relate values one to another.
This process is supported by what is known as the Dublin Core Registry [DC Metadata Registry]. This registry is for schemes that are developed by users and then shared via the registry. When such schemas are developed and expressed in the same way, supporting the DC model, a refinement of a term as used in one schema can be related to another refinement of the same term in a different schema, by a computer. In other words, the interoperability of the terms can be automated so that even if humans do not know of the relationships, computers can work with them. Where a new term is introduced by a schema, although it will not necessarily relate well to all the terms in another schema, it will be defined (according to the DC rules) and so at least its value will be able to be related to any term that has the same identity, in whatever schema. A registry is not necessary for this result but it can make it easier to have all the information in one place. As the terms in the registry are defined using conforming Semantic Web standards, by virtue of following Dublin Core standards, terms declared elsewhere as part of the Semantic Web can also be connected to those in the registry.
(It should be noted that in the 'flat' DC model, there can be multiple descriptions of a single characteristic if there is more than one thing to be said about it. This keeps the model simple. It is also the case that no descriptions of characteristics are required. There is no resource description, in fact, if there is not a characteristic that provides the identity of the resource being described.)
The author has adopted a 'octopus' metaphor for describing how DC terms and the Semantic Web work.This is described, as is the Dublin Core metadata model, in Chapter 6). The octopus metaphor is useful for thinking about core terms and their refinement, and also for application profiles.
This section on semantic interoperability has built on the discussion in Chapter 6. There, it was argued unless metadata is defined in a formal, consistent way, it cannot
be used by machines that cannot reason or make judgements
about how to interpret resource descriptions. this idea has been further elaborated in this chapter. Implied in Chapter 6 was
the need for these constraints from a discovery perspective.
That is, if metadata is to be used to find distributed resources,
the same query will need to be applied to a number of search
engines. Interoperability implies that the single query will
be comprehensible and useful to all such query engines. It
is not necessary that the query is used by all of them in
its original form as they may be able to transform it, prior
to using it, to suit their purposes. In some cases, this
means a cross-walk where two sets of metadata are linked
by a mapping, one-way or two-ways. If such a mapping is not
perfect, in other words is not lossless, the mappings will
be, correspondingly, less than perfectly interoperable.
In Chapter 10 the problem of finding an alternative on the Web when a given, or discovered, resource was found to be inadequate, was considered. This is more than merely being able to send a query to a range of discovery services because it includes having a way to successively enrich the description of what is sought, when a search does not find a suitable alternative. In the same way as using the Semantic Web can be done to relate metadata terms that were not previously known so their values can be investigated and used for discovering metadata about a resource, so might the terms used in those values be enriched. For this to happen, they too must be defined appropriately, so they can be linked automatically. Dublin Core rules are constraining with respect to values in order to promote interoperability in this context (see Chapter 6). Such constraints include the specification of domains and ranges for properties, and the provision of machine-readable definitions of all terms (including potential values).
Interoperbility between LOM and DC Metadata
The problem of mapping from a LOM-style, hierarchical metadata model to a DC model, and vice versa, has been considered at length by Mikael Nilssen (2007a) and Ambjörn Naeve, among others. Nilssen shows the goal being achieved (Figure ???) and offers a table (adapted in Table ???) that shows where the problems occur.
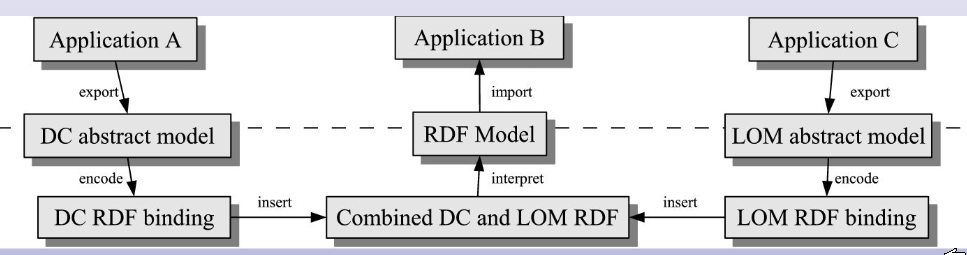
Figure ???: (Nilssen, 2007a)
Interpreting XML and RDF Metadata
| Format |
Extended with Fragment from |
Processable by LOM application |
Processable by DC application |
Processable by RDF application |
| LOM XML |
DC XML |
Only LOM part |
none |
|
| DC XML |
LOM XML |
none |
Only DC part |
|
| LOM/DC RDF |
LOM + DC RDF |
Only LOM part |
All DC part
most of LOM part |
All DC part and
all
LOM part |
Table ???: Interpreting XML and RDF Metadata - adapted from
(Nilssen, 2007a)
Nilssen says that while there appears to be surface interoperability, because the two standards both use XML namespaces and RDF, "the interpretation of these expressions differ". This problem led Nilssen et al (2008) to present what is now known as the Singapore Framework that shows how interoperability can occur more, or less (Figure ???).
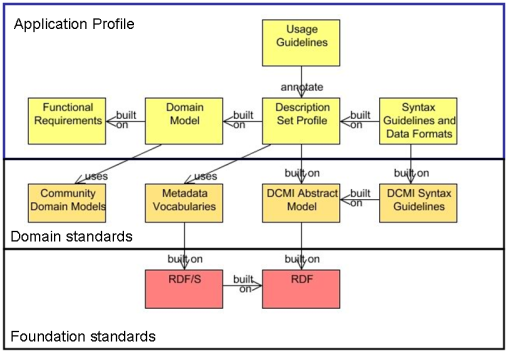
Figure ???: The Singapore Framework
(Nilsson et al,
2008)
Nilssen et al's diagram (Figure ???) shows the dependence on the W3C Resource Description Framework standards [RDF] required for interoperability of DC Application profiles. They argue that simply using the same RDF foundation stanars does not ensure interoperability between metadata sets so that adaptations (including extensions) of DC metadata are not fully interoperable unless they are strictly comformant to the domain standards. By implication, LOM metadata is not fully interoperable with DC metadata because the models are not compatible.
Cross-walks and mappings
The interoperability of metadata is considered one of its
strengths and it has, in its short recent history,
led to many institutional digital libraries sharing their
metadata to develop what operate as united libraries, following
a range of organisational and technical models. Where sets
of metadata are to be combined for some purpose, such as integration,
if the metadata sets are not based on the same standards, it
is often possible to map them both to a third set of metadata
terms so they can be shared, even if with some loss.
The mapping can be loss-less when the two systems are fully
compatible but often this is not the case and some compromises
are made. Dublin Core metadata, for example, follows the flat
model of one property for each metadata statement and all properties
can be repeated and none but the identifier of the resource
are mandatory. IEEE Learning Object Metadata (LOM), on the
other hand, is deeply hierarchical, that is, a property can
also have sub-properties and the sub-properties can have their
own sub-properties. Mapping from LOM to DC metadata is not
necessarily possible without loss, although it
is possible to use both LOM and DC metadata with RDF encoding
so the metadata can be fully interoperable (Nilssen, 2007a). This is dealt with in detail in Chapter 11.
Syntactic Interoperability
In Chapter 7, the need
to ascertain if the metadata of resources that are already
available and suitable as alternatives for inaccessible resources,
led to an analysis of the potential interoperability of AccessForAll
metadata and the original metadata. In Chapters
9 and 10, the task of
finding an accessible alternative to an inaccessible resource
was considered. In such a case, it is obvious that the metadata
search for the alternative needs to be interoperable with
any catalogue referring to such a resource.
Syntactic Interoperability
Developing metadata for interoperability
One aspect of interoperability is the ability to share
the same kind of information with others using the same systems
and acting with the same goals. Another is to work across
devices including using different hardware and software without
losing the necessary ‘look and feel' that facilitates learner
mobility between devices.
W3C has a working group focused on Device Independence,
another focused on the Mobile Web, another working on Evaluation
and Repair, and a fourth working on metadata, the POWDER
working group. All four Working Groups produce specifications
that are important to the interoperability of AccessForAll
(Table 9).
The vision we share with others is to allow the Web to
be accessible by anyone, anywhere, anytime, anyhow. The
focus of the W3C Web Accessibility
Initiative is on making the Web accessible to anyone,
including those with disabilities. The focus of the W3C
Internationalization Activity is on making the Web
accessible anywhere, including support for many writing
systems and languages. The focus of the W3C
Device Independence Activity is on making the Web accessible
anytime and anyhow, in particular by supporting many access
mechanisms (including mobile and personal devices, that
can provide access anytime) and many modes of use (including
visual and auditory ones, that can provide access anyhow).
Table 9: Relevant W3C metadata and interoperability activities
| W3C Activity |
Activity description |
| Device Independence |
"Content authors can no longer afford
to develop content that is targeted for use via a single
access mechanism. The key challenge facing them is to
enable their content or applications to be delivered
through a variety of access mechanisms with a minimum
of effort. Implementing a web site or an application
with device independence in mind could potentially save
costs, and assist the authors in providing users with
an improved user experience anytime, anywhere and via
any access mechanism." (W3C,
Device Independence, 2003) |
| Mobile Web |
This group aims to tackle ""interoperability
and usability problems that make the Web difficult to
use for most mobile phone subscribers." (W3C,
Mobile Web, 2005) |
| Evaluation and Repair Language |
"The Evaluation And Report Language
is an RDF based framework for recording, transferring
and processing data about automatic and manual evaluations
of resources. The purpose of this is to provide a framework
for generic evaluation description formats that can be
used in generic evaluation and report tools." (W3C
EARL, 2001) |
| POWDER |
"Working Group is to develop a mechanism
through which structured metadata ("Description
Resources") can be authenticated and applied to
groups of Web resources. This mechanism will allow retrieval
of the description resources without retrieval of the
resources they describe."
(W3C
POWDER, 2007) |
For a network delivery system to match users' needs with
the appropriate configuration of a resource, two kinds of
descriptions are required: a description of the user's preferences
or needs and a description of the resource's relevant characteristics.
If users are to be able to quickly configure their devices,
they need their needs and preferences to be quickly recognized
and implemented by the device they are using. Similiarly,
if they are to search for appropriate resources (including
where their search for resources causes their system to search
for accessible components from which to make the resource
they want), their needs and preferences descriptions have
to be available to the search engine for searching and matching
with the resources and their components. Where this is happening
across collections of resources, a common way of describing
the resources will be necessary and it will need to mirror
the descriptions of the resources. So
interoperability between the two sets of descriptions is
necessary so that even though one is concerned with the user's
needs and the other with a resource, they can both be used
by the search engine. In effect, this means that the description
of the user's needs should be in the same format as the description
of the resource.
Typically, users with special needs will be looking for
resource components that are developed by specialists. Usually
specialists who have not made the original resources produce
closed captions, image descriptions and video files of people
signing. They are likely to know the standard assistive technologies
and what they will require and can do to use the special
components. In automating the matching process for the user,
it is very important that the standard triggers are available
for the assistive technologies. This means that the resources
should be described in the way they can be understood by
particular assistive technologies but also so that there
is a generic description specification that all the assistive
technologies can be expected to refer to. For this reason,
care has been taken in AccessForAll to ensure that there
is a seamless match and the established industry terms are
used.
The implications for interoperability here are for exchange
between systems known as ‘user agents' that typically include
browsers. It is well known that browser developers pride
themselves on the non-standard features they offer and that
it is not easy to satisfy all browser specifications simultaneously.
Fortunately, assistive technology developers who have a much
smaller market are often more concerned to serve their customers
and their industry associations. Nevertheless, it is important
to recognize their differences and allow for their use so
the AccessForAll model has to be capable of such flexibility.
In fact, it aims for some generic functions to be described
in a common way while allowing for extensions to accommodate
custom functions or features.
AccessForAll metadata was first developed for use within
the educational sector. As most resources for educational
purposes are created within educational institutions, and
therefore described by the educational community, descriptions
of those resources are usually created according to standards
designed for the educational community. Having worked with
the goal of sharing resources for some time now, the educational
communities have a number of ‘standards', the best-known
being those developed by IEEE LOM, known as Learning Object
Metadata [IEEE/LOM].
Clearly, the accessibility characteristics of resources that
are ‘learning objects' need to be described in a way that
interoperates with all other aspects of LOM descriptions.
Often, however, educational activities involve learners
using resources that have been developed and described by
other communities for their own purposes. For example, technical
manuals are often used in Computer Science courses but they
are not usually written for this purpose. Government information
is often used in education, as are images of paintings and
objects held in museums and galleries. The resources to be
used by learners then, do not always originate from the educational
or even the same communities and their description for discovery
purposes can be very specific to the community from whence
they come. In order to discover resources
across communities or disciplines, then, the descriptions
of the accessibility characteristics of resources need to
be consistent with descriptions used in those communities.
Dublin Core metadata is not domain specific. As DC metadata
is commonly used by governments, museums, galleries, and
others for information sharing, AccessForAll needs to be
able to take advantage of their interoperability. DC metadata
also has the advantage that it is used in many countries
for resources that are created in many different languages
and so can be used for cross-language discovery.
DC Metadata and IEEE LOM and IMS LIP metadata are very
different (Chapters 6, 7).
They vary at several levels, including specifically at the
structural, and semantic levels.
Not everything that will be useful to have as AccessForAll
metadata is unique to the AccessForAll model so in a DC implementation,
a significant amount of information will be expressed using
standard DC elements. Exactly how to do this will be described
in a DC Application Profile for which specific terminology
(semantic values) will be defined. The value of this work
for DC users is that they will be able to express the AccessForAll
metadata in DC compliant ways so it will interoperate with
other DC metadata. They will also be able to use standard
DC applications without significant modification.
In summary, AccessForAll needs to interoperate with a number
of other relevant metadata specifications and standards.
Interoperability in educational contexts
In 2003, Kevin Keenoy reported on the main metadata standards
in use in education (2003):
The Dublin Core Metadata Element Set seems to be by far
the most widely accepted and used set of metadata standards
for ‘core’ categories applicable to any internet-based
content. Almost all existing learning object metadata standards
use the Dublin Core as a basis and then extend it with
more specialised elements. (Keenoy,
2003, p.2)
He continued:
The standard builds on the Dublin Core, and is based on
recommendations from the ARIADNE project and IMS (see later).
The LOM metadata specification forms the basis of almost
all existing implementations of metadata specifications
for learning objects, and should probably be the basis
for metadata used in SeLeNe. (Keenoy,
2003, p.3)
He goes on the explain the complex relationship between
the LOM standard in many contexts and formats but explains
they are closely related. This is also the case in Australia
where the Educational network of Australia uses a DC-based
metadata schema anas do many of the other educational systems
in Australia,
So, between them, IEEE LOM and DC metadata describe a vast
proportion of the resources that are of interest in education.
Many educational systems use IEEE LOM metadata to describe
their resources but others use DC metadata. It makes sense
that these two communities should be able to exchange metadata
records about their resources so they can, in fact, share
their resources. To do this, they need to be able to transform
metadata from one specification to the other. There is an
activity, started in 2001, that aims to bring the two sets
of specifications into harmony. It cannot be done easily
because LOM and DC metadata are based on very different models.
The LOM abstract model is hierarchical and instead of having
property-value pairs as DC metadata does, it has a rule that
every element is either a container (of another element)
or a leaf (to another element). This is a more typical model
but very different from the DC one. Attempts to cross-walk
(transform) metadata from the LOM to DC metadata, or vice-versa,
typically result in substantial loss either in detail or
value. LOM metadata has many more elements than the simple
DC core set and so when LOM metadata is transformed into
DC metadata there is a many-to-few transformation with a
lot of metadata being discarded. When DC metadata is transformed
for use as LOM metadata, a lot of the metadata of interest
to educators is found to be missing. DC metadata lacks the
structure of LOM metadata: DC metadata is ‘flat' while LOM
metadata is hierarchical.
Figure ??? shows that in order to send a query across
a number of metadata repositories in use in education, a
special federated sytem is required. In this case, Stefaan
Ternier et al (2008)
have defined a new query language to facilite this process
but each repository has to develop its own special way of
exchanging information using that language - it is not possible
to send the same query, as is, to all repositories, because
their metadata schema are not interoperable.
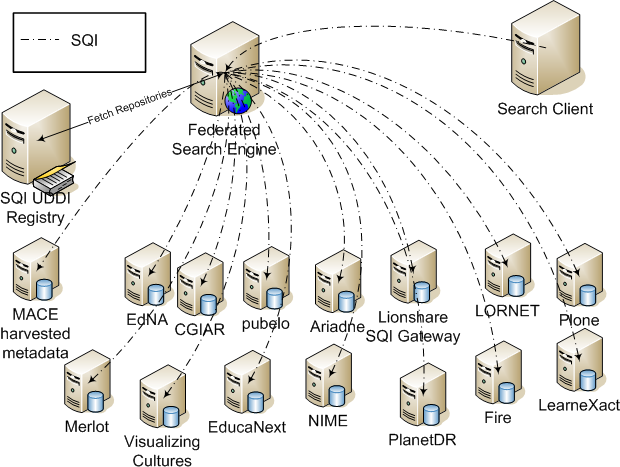
Figure
???: The Globe federated search model using ProLearn
Query Language. (
Ternier
et al, 2008)
(insert the image of how DC and LOM
cannot support a round-trip transformation....) etc - esp
to quote from paper for ISO about why MLR is not right...
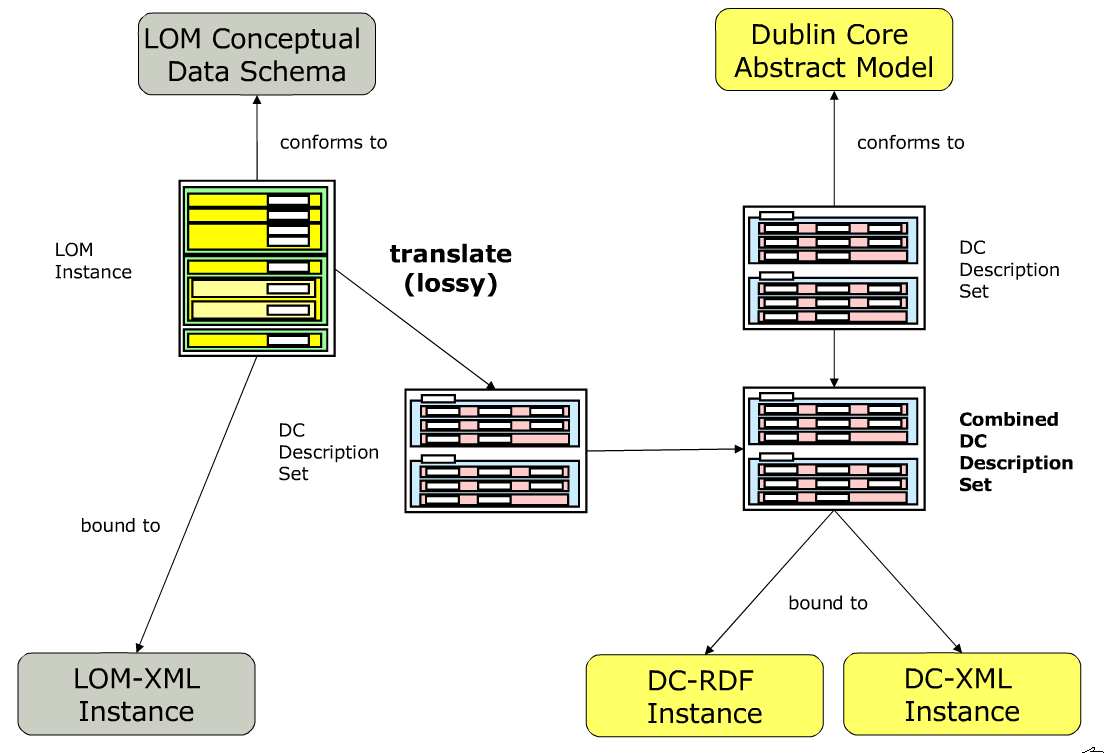
Figure ???: The point of loss of information in the LOM ->
DC translation process (Johnston
et al, 2007)
There have been several attempts to find good ways of moving
metadata back and forth from one system to the other without
loss. In late 2005 there was what appeared to be a useful
model developed for this. Early work focused on moving information
expressed as metadata from one system to the other but recently
was decided that it is more effective to relate the elements
that contain that information and then express the metadata
in whatever syntax is chosen. Mikael Nilsson explains this
in his model:
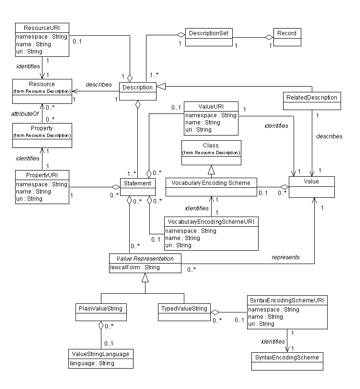
Figure
???: A possible structure of a future metadata standardization
framework.from Mikael Nilsson,
From
“The Future of Learning Object Metadata Interoperability Towards
a Framework for Metadata Standards“ publisher etc?]
Nilsson concludes:
We have demonstrated that true metadata interoperability
is still, to a large extent, only a vision, and that metadata
standards still live in relative isolation from each other.
The modularity envisioned in application profiles is severely
hampered by the differences in abstract models used by
the different standards, and efforts to produce vocabularies
often end up in the dead end of a single framework. In
order to enable automated processing of metadata, including
extensions and application profiles, the metadata will
need to conform to a formal metadata semantics.
To achieve this, there is a need for a radical restructuring
of metadata standards, modularization of metadata vocabularies,
and formalization of abstract frameworks. RDF and the Semantic
Web provide an inspiringly fresh approach to metadata modelling:
it remains to be seen whether that framework will be reusable
for learning object metadata standards.
This suggested that is may not be until there is a shared,
single IEEE/LOM/DC abstract model for education that there
will be perfect interoperability between DC and IEEE/LOM
resource descriptions but it may, on the other hand, be possible
in the particular case of AccessForAll metadata because it
is based on a more interoperable abstract model.
More recently, Nilsson, Baker &
Johnston have proposed a four-level model for interoperability
(2008).
Pete Johnston (2008)
summarises the document as follows:
The document presents a "layered" approach,
describing four distinct "interoperability levels",
each building on the previous one, and attempting to specify
clearly the assumptions and constraints which apply at
each of those levels, and the expectations which a consumer
can have for metadata provided "at" a specified
level.
Level 1: "Informal interoperability", based
essentially on the natural-language definitions of metadata
terms;
Level 2: "Semantic interoperability", based on
the RDF model;
Level 3: "DCAM-based syntactic interoperability",
introducing the notions of descriptions and description
sets, as defined by the DCMI Abstract Model;
Level 4: "Singapore Framework interoperability",
in which an application is supported by the complete set
of components specified by the Singapore
Framework for Dublin Core Application Profiles.
Interoperability of personal needs
and preferences
Keenoy (2003,
p.7) points to a set of standards that are used to
describe, in one way or another, learners for the purposes
of learning management systems. DC is conspicuously missing
from the list (as is to be expected according to Chapter
8). This is primarily because the DC profile has not
yet been developed, but also because the AccessForAll proposal
does not attempt to describe permanent characteristics
of people, as does most learner profile metadata.
The Benefits of Interoperability
A key challenge in accessibility is the diversity of need;
different people require different accommodations. Established
approaches towards addressing this are to allow customization
by the end user (e.g. text size and color) and to offer alternative
presentations of the same content where automatic customization
is not possible (e.g. text description of diagrams or audio
descriptions of video content).
Integrated systems potentially offer an efficient way of
managing and even extending this. They can personalize the
way the interface and the content are presented to the user
and further, which content is presented to them can be determined
by the system on the basis of stored information about them
and their preferences.
Such systems offer organisations the opportunity to efficiently
manage their requirement to meet the needs of their users
with disabilities. If they implement user profiles and adopt
the AccessForAll approach, the system will “know” how best
to present content and interfaces to each individual user.
If they implement the approach for the metadata of the content
stored in their repositories, then the system can automatically
offer their content, and other information, in the most appropriate
format to meet individual user needs.
The Semantic Web offers one obvious technology that will
be enabled by the AccessForAll approach. Already the AccessForAll
specifications recommend using EARL so that the metadata
will be as flexible and rich as possible. The range of other
extensions includes opportunities for valuable cross-lingual
exchanges to suit learner needs as well as cross-disciplinary
changes of emphasis. Applications and Web services that transform
resources or resource components to suit the needs of users
with cognitive disabilities is a huge area that has hitherto
not received the attention it deserves.
Metadata lessons
In the ISO/IEC context, another metadata activity has been underway
in parallel with this research. National bodies and experts
have been defining how metadata should be written for the educational
context in what is known as the Metadata for Learning Resources
standard (JTC1 SC36 19788-1 ref???). This standard is supposed to assure that, in
the future, educational metadata is consistent so that it will
be more interoperable and useful.
The introduction to this standard (at the CD2 stage) states:
The primary purpose of this standard and its parts is to
facilitate search, acquisition, evaluation, and use of learning
resources, for instance by learners, instructors or automated
software processes. The interoperability of these functions
can be achieved through harvesting or federated search processes,
among other technologies and solutions.
… It also has been developed with a view to achieve compatibility
with both IEEE 1484.12.1-2002 LOM and Dublin Core ISO 15836,
while also addressing user-driven requirements and uses not
explicitly addressed in those two standards. (ISO/IEC
CD2 19788-1, as at July 15, 2008, page 1, confidential document)
In an international collaborative effort to ensure this standard
really does achieve its goals, the author produced the following
diagrams (Figures ??? to ???) to illuminate the issues of incompatibility:
The diagrams show that the first proposed model of metadata
included many problems in terms of interoperability, which,
to a large extent, depends on modularity and what is known
in the Dublin Core community as the one-to-one rule: any metadata
record should refer to only one resource (ref???). As explained
earlier, hierarchical metadata models are not compatible with
flat models, and for this reason, the proposed metadata model
could not be assured of compatibility with the DC model. In
addition, the mix of metadata about the resource, the contributor,
the metadata record would break the necessary modularity rules
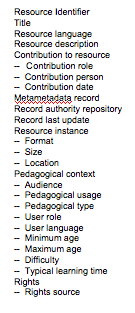
and the first-class nature of good metadata.
Metadata is described as first-class when it can itself be
treated as data. In such a case, a metadata record is itself
treated as data for any metadata about it. So the meta-metadata
record proposed by the draft proposal would break this rule.
The Web’s inventor Tim Berners-Lee (1997), postulated the rule
early in the life of the Web, and it was adopted early by the
Dublin Core community.
Essentially, Berners-Lee explained that if metadata was not
carefully defined and ‘first-class’, it would not be useful
for logical inferences to be made by machines. That is, in
lay terms, if a statement about an object is not also an object,
it is not possible for a machine to perform the only sort of
reliable functions we yet know to engage machines with, logical
functions such as, AND, OR, NOT. As these functions are essential
to search and control of metadata by machines, they are very
important in the metadata world. If metadata is first-class,
we can imagine something like this:
PRINT <metadata records> of <all objects> containing <title> includes
“Fred” AND “Jones” but NOT “Freda”.
The work for the MLR is on-going but it is important to note
that it is experiences such as those had by the ISO/IEC SC
36 Working Group responsible for AccessForAll metadata (Working
Group 7) that has led to the international effort to control
the metadata model (ref is posting to WG7 by LN ???).
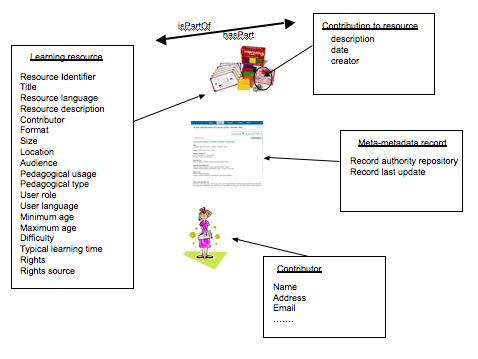
In Novermber 2008, a special meeting was convened in Paris (ref???) for National Bodies to deal with the approximately 500 comments made on the CD2 version of the draft MLR standard. The author was one of the seven people who disposed of those comments by developing a new model for learning resources metadata. The model is new, not in its form, but for learning resources, abandoning the earlier hierarchical model that has caused such difficulties as the LOM ref??? and adopting a model that is very similar to the DC model.
An interesting question that has not been settled (at the time of writing), is just how closely the interoperability for the new MLR should be to the DC Abstract Model. The possibilities are:
- exactly the same as general DC metadata, in which case it would be an Application Profile of the DCMT, in fact, but not maximally compatible with the existing LOM and thus legacy metadata;
- exactly the same as the constrained Application Profile of DC metadata that is proposed by Nilssen and is maximally compatible with the LOM, in which case it would still be an AP of DC metadata;
- like the DC so that it could be matched exactly with a cross-walk, but would not necessarily be an Application profile of DC metadata, or
- simple similar with some interoperability.
The MLR is required to match the ISO version of DC simple ...so what are the differences???
Functional Requirements for Bibliographic
Records
The close relationship between the FRBR model and accessibility
metadata is slowly being recognised in the AccessForAll context
as it is being realised simultaneously in emerging general
metadata standards such as the Metadata Encoding and Transmission
Standard [METS].
For accessibility, this is important because while those working
in accessibility have for a long time been considered to be
technical experts in encoding languages, due to the prominance
of WCAG in the context, it may become more an issue for
information managers with library skills.
The library community is faced by the problem that a single work,
such as a Shakespeare play, can be published in many forms,
by many publishers, and usually with multiple copies of any
particular publication. This means that a librarian offering
a single copy needs to be fitted into a community of providers
and, from another perspective, a user has a complex set of
potential providers and locations for a single work.
To simplify matters, the International Federation of Library
Associations developed a framework for the functional requirements
for the catalgoue records they have for works [FRBR]. In fact, they
defined four levels of development of a book starting with
the intellectual endeavour, the work, which is expressed in
some form, say a play, then manifested in some form, perhaps
a publication by XYZ company, of a set of items, books. The
four entities are therefore: work, expression, manifestation
and item.
In the context of accessibility, while the FRBR authors did
not explicitly take it into account because it was not relevant
to them at the time, FRBR's entities can be very useful. The
FRBR model assumes four user tasks: find, identify, select and obtain (Figure
62). These are not just for those seeking books but also relevant
to users of digital resources. Just as book searchers may need
to use information about the expression of the work they
seek, so may the user who wants an alternative manifestation or item.
In the case of items, of course in the digital context, an
item may be displayed in many ways. Similar book items
can be distinguished too, for example, the difference might
be who owns them, where they are located, or what condition
they are in. Such qualities are similar
in kind to those of interest to the digital resource user,
and they need to be described for users for whom they make a
difference, in this case, users of heritage books.
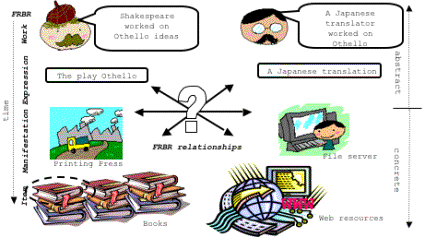
Figure 62: 4 FRBR entities associated with two resources and
their possible relationships (Morozumi et al, 2006).
(Translation into a foreign language, as shown in Figure 62, is equivalent to transformation
into a different form, and conversion of a graphic of symbolic
mathematics into a MathML version suitable for automatic transformation
into Braille, for instance.)
FRBR entity attributes
FRBR is not a
metadata schema and is not intended to be one. It is not
implemented as metadata anywhere. It is a model for use by
those who are working on metadata for user requirements.
The author and colleagues (Sugimoto & Morozumi) analysed
FRBR as a way of testing the AccessForAll metadata (Morozumi
et al, 2006). They compared the FRBR relationships and attributes
of entities with Dublin Core Metadata Terms [DCMT
Terms] and the ISO/IEC JTC1
Digital Resource Description (DRD) terms.
In other words, the aim was to find out if the FRBR model
proposed metadata that would be useful in an AccessForAll
context with respect to accessibility characteristics of
a resource. Similar work had been done previously with respect
to the Dublin Core model when the Dublin Core accessibility
work first commenced (Chapter 7).
DCMT (properties)
describe what FRBR calls attributes of entities with the
exception of the relation element. dc:relation is useful
for describing relationships that can be of interest in the
accessibility context, as demonstrated in the emerging DC
Application Profile for AccessForAll (<http://dublincore.org/accessibilitywiki/>).
The relationship between the attributes of dc:format and
dc:type would be of interest but this depends on implementations,
and is not in the metadata per se. dc:description and dc:audience
may also be useful, depending on their use.
Not surprisingly, there was little in common between
the elements of the DRD and the FRBR model; the DRD was
designed to complement existing metadata schemas, not to
duplicate them. These results led to the observation
that the DCMT terms are limited in respect of accessibility
adaptability in the same way as is the FRBR model. It was
asserted then, that as the DRD represents the information
as metadata that is required in the description of a resource
to indicate its adaptability for accessibility, neither the
FRBR model, nor examples of metadata such as the DCMT and
MODS that are closely related to it, provide the metadata
necessary for accessibility adaptability (Morozumi et al,
2006).
OpenURL
One possibility is to launch a query once, and to develop
a service that can formulate a suitable OpenURL from a user's
content query in combination with their needs and preferences
profile. Wikipedia provides a useful explanation of OpenURI:
An OpenURL consists of a base URL, which addresses the user's
institutional link-server, and a query-string, which contains
contextual data, typically in the form of key-value pairs.
The contextual data is most often bibliographic data, but
in version 1.0 of OpenURL can also include information about
the requester, the resource containing the hyperlink, the
type of service required, and so forth. For example:
http://resolver.example.edu/cgi?genre=book&isbn=0836218310&title=The+Far+Side+Gallery+3
is a version 0.1 OpenURL describing a book. ...
The most common application of OpenURL is to provide appropriate
copy resolution: an OpenURL link points to the copy of the
resource most appropriate to the context of the request.
If a different context is expressed in the query, a different
copy ends up resolved to; but the change in context is predictable,
and does not require the creator of the hyperlink to handcraft
different URLs for different contexts. For instance, changing
either the base URL or a requester parameter in the query
string can mean that the OpenURL resolves to a copy of a
resource in a different library. So the same OpenURL, contained
for instance in an electronic journal, can be adjusted by
either library to provide access to their own copy of the
resource, without completely overwriting the journal's hyperlink.
The journal provider in turn is no longer required to provide
a different version of the journal, with different hyperlinks,
for each subscribing library. (Wikipedia,
2007)
In simple terms, an openURI contains a place for customisation
information to be added by a server. It is not difficult to
imagine a versio of OpenURI that adds information not about
the particular location of a copy of a book that is in a number
of places, but about an accessible alternative version of a
content component.
------------------???
Chapter Summary
In this chapter, ...
Next ->
 This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
{kind=link}
{kind=link}