Chapter
9: Resource Profiles
Introduction
The AccessForAll specifications are
intended to address mismatches between resources and user
needs caused by any number of circumstances including requirements
related to client devices, environments, language proficiency
or abilities. They support the matching of users and resources
despite [some universal accessibility] short-comings
in resources. These profiles allow for finer than usual detail
with respect to embedded objects and for the replacement
of objects where the originals are not suitable on a case-by-case
basis. The AccessForAll specifications are not judgmental
but informative; their purpose is not to point out flaws
in content objects but to facilitate the discovery and use
of the most appropriate content for each user. (Jackl,
2004)
The AccessForAll
specifications are part of the AccessForAll Framework.
They do not specify what does or does not qualify as an accessible
Web page but are designed
to enable a matching process that, at best, can get functional
specifications from an individual user and compose and deliver
a version of a requested resource that meets those specifications.
It depends upon other specifications (such as WCAC) for the
accessible design of the components and services it uses.
Having a common language to describe the user's needs and
preferences and a resource's accessibility characteristics
is essential to this process. That is why the resource
descriptions proposed below so closely match the descriptions
of the needs and preferences of individual users, as discussed in Chapter 8. It is not
essential, however, for there to be a matching process for
there to be value in having a good description of the accessibility
characteristics of a resource. In the discovery and selection
processes, a user can take advantage of such a description
and at least be forewarned about potentil access problems with the resource.
It should be clear that, as AccessForAll does not specify
the functional characteristics of Web content, but rather the
specifications for the description of those characteristics,
it is not intended to support any claims of conformance of
resources to other standards and specifically, not conformance
to the WCAG specifications. On the other hand, the WCAG specifications
might well be used to determine the characteristics of the
resource, such as if the text is well-constructed, or if images
have correct alternatives. AccessForAll specifications are
only concerned with metadata.
(A significant amount of the content in this chapter has
been contributed to papers now published or other documents (Nevile,
2005a; Barstow
& Rothberg, 2002; Jackl,
2004; Chapman
et al, 2006).
In this chapter, the possibility of user interface adaptation
is considered as an extension of the AccessForAll model. First,
a project being undertaken simultaneously with the AccessForAll
work is discussed, and then some new work that has been started
only since the emergence of the AFA model. The chapter contains writing that was part of a paper about
universal remote control devices that was co-written by the
author (Sheppard
et al, 2004).
Primary and equivalent alternative
resources
(or components)
The AccessForAll (AfA) way of organising metadata has to take
into account that most resources are thought of as having a
set form with modifications for accessibility purposes. This
is not an inclusive way of thinking of resources, and it is
not what is emerging as the model on the Web. Given the technology,
resources are being formed at the time of delivery, according
to the delivery mechanisms available and the point of delivery,
but often resulting in many very different manifestations.
AfA is designed to contribute to, in fact take advantage of,
that process.
Matching users and resources involves not only the user's
needs and preferences from a personal perspective, but also
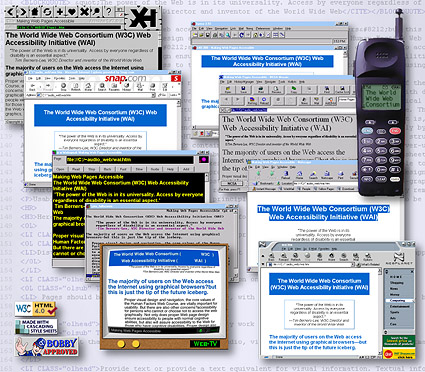
accommodations for their access devices. Figure 51
shows a single Web page rendered by 10 different access
devices, not including any that don't produce visual displays
of any kind:
AfA metadata is designed to facilitate the just-in-time
adaptation of resources to make them accessible for individuals.
This process depends on metadata being available so it can
be used to manage the substitution, complementing or adaptation
of a resource or some of its components.
Given that most resource publishers do not know much about
accessibility, and have been shown to not do much about it,
it is assumed they will not be very careful about what metadata
they contribute to resources, if any. For this reason, there
has been an effort to find the minimum that makes a difference
and is easy to write, with the hope that those who do more
about accessibility, either by making better resources or fixing
others, are more inclined and better informed about what metadata
to use. In cases where a resource contains or
is intimately linked to alternatives, such as where there is
an equivalent resource like a text caption for an image, the
metadata for the resource should indicate this and provide
metadata for both versions of that component. It is sometimes handy
for one component to be referred to as the 'primary' component
and for the other as the 'equivalent alternative'.
Equivalent alternative
resources are of two types: supplementary and non-supplementary.
A supplementary alternative resource is meant to augment
or supplement the primary resource, while a non-supplementary
alternative resource is meant to substitute for the primary
resource. Although in most cases the primary and equivalent
alternative resources will be separate, a primary resource
may contain a supplementary alternative resource. For example,
a primary video could have text captions included. In this
case the resource would be classified as primary containing
an equivalent supplement. A primary resource can never contain,
within itself, a non-supplementary resource. (Jackl,
2004, Sec. 3.2.1)
The AfA metadata is tightly specified and very detailed. This
is not done in ignorance of the practicalities of metadata
that suggest it should be very light-weight and easy to create. It is this way because people with disabilities have
special needs. They use technologies that are built specially
for them and that means for a small market given the range
of different devices they need. This does not mean that the
market for standardised accessibility metadata is small -
it can be shared across all the different adaptive technologies
and beyond them to great benefit. It means rather that it is
very important to be very precise about the metadata and to
maintain its stability, very carefully, so that adaptive technology
device and software developers can be assured of the stability
of the functional requirements for metadata and thus reliable
availability of that metadata. There is not the usual room
for tolerance when not having something means having no access
to information for someone. Thus, the threshold for interoperability
is higher than usual in this context.
The personal access systems used by people with disabilities
can be seen as unique external systems that need to interoperate
with the system delivering the resource. These personal access
systems must interoperate with many different delivery systems.
The personal access systems must also adjust frequently to
updates or modifications in an array of delivery systems.
For these reasons it is important that the delivery systems
tightly adhere to a common set of specifications with information
relevant to accessibility. To promote interoperability this
information should be found in a known consistent place,
stated using a consistent vocabulary and structured in a
consistent way. To support this critical interoperability
the AccessForAll specifications offer less flexibility in
implementation than other specifications. (Jackl,
2004, Sec. 3.2.4)
The WCAG architecture treats resources as single entities
despite the fact that it may take a number of files to form
a Web page. This is not how resources are understood in
AfA architecture:
Content can be considered either
atomic or aggregate. An atomic resource is a stand-alone
resource with no dependencies on other content. For example,
a JPEG image would be considered an atomic resource. An
aggregate resource, however, is dependent on other content
in that it consists not only of its own content but also
embeds other pieces of content within itself via a reference
or meta-data. For example, an HTML document referencing
one or more JPEG images would be considered an aggregate
resource. The use and behavior of AccessForAll Meta-data
for atomic content is straightforward. .... For aggregate
content, the required system behavior is slightly more
complex but it still involves matching. In other words,
if the primary resource is an aggregate resource, then
the system will have to determine whether or not the primary
resource contains atomic content that will not pass the matching
test. If so, it will examine the inaccessible atomic resources
to determine which resources require equivalents. This means
a primary resource must define its modalities as inclusive
of those of its content dependencies. (Barstow
& Rothberg, 2002)
Creation of reliable metadata
As the required metadata is
quite detailed, there may be some concern about who will produce
it. Even where the metadata is created by a well-intentioned
party, there may be a question about how reliable it is. Fortunately
there are a number of applications available that help with
the description process and even do some of it automatically.
There are a number
of tools for the authoring of metadata but in the accessibility
context, there are tools for assessing accessibility that
also produce metadata. Many of these
produce their reports in a language called Evaluation and Report
Language [EARL].
EARL provides a way to encode metadata such as AfA metadata.
EARL requires all statements to be identified with a time
and the person or agent making them. This makes it easier to
identify the source of the description for trust purposes.
EARL statements are generally intended to convey information
about compliance to some stated standard or specification.
This information is typical of what is needed for accessibility.
An example is an EARL statement that includes information about
the transformability of text determined by reference to the
relevant Web Content Accessibiliy Guidelines [WCAG-1] provisions.
The AccessForAll metadata specifications
The original IMS AccessForAll specifications were very closely
based on the specifications developed by the Adaptive Technology Resource Center [ATRC] for The Inclusive Learning Exchange [TILE].
These were subjected to rigorous scrutiny because of the need
to satisfy the other stakeholders involved but the attributes
of interest were assumed to have been well-identified by the
ATRC. As those specifications were advanced through the ISO/IEC
process, they were subjected to scrutiny and some modifications
were made. These are not important in the sense that they are
details about attributes that can be adapted and adopted within
the framework. What is important here is how the framework
operates and how the specifications work.
Just as the user will want to define three classes of attributes
of personal needs and preferences, there are three classes
of attributes of digital resources to be described using AfA
metadata. They are the control, display and content characteristics.
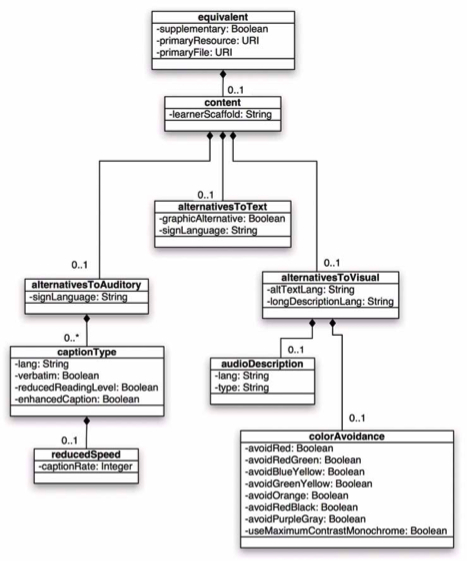
As can be seen in Figure 52,
the original structure of this metadata was deeply hierarchical.
Somehow, it needed also to be represented as 'flat' Dublin
Core metadata. This was achieved by using the DC structures
but only interoperable with the assistance of cross walks.
'Depth', in Dublin Core metadata, is achieved by having qualifications
of elements that comply with DC rules for such qualifiers.
DC qualifiers constrain either the element itself or the potential
values of those elements, by providing such as an encoding
scheme or a controlled vocabulary. To achieve this in Dublin
Core form, it was necessary to reconsider some of the elements
so the final DC version is not merely a flattened version
of the hierarchical IMS model.
This is most easily shown by a sample mapping from
one form to the other. In the case of the LOM version, to indicate
that a resource is a text alternative to an image, the following
encoding would be used:
alternative >> alternative resource content
description >> altToVisual >> textDescription >> French, caption
while the same information would be conveyed using the DC version,
by:
accessMode: textual
isTextDescriptionFor: URI of the original component being made
accessible; caption
language: French
While both systems can provide the same information, it can
be seen that the DC model leaves the language independent of
the type of resource (caption) and these properties need to
be allied while both these pieces of information are specific
to the textDescription of the altToVisual of the alternative
resource content description of the alternative.
The research involved finding a way to do this
for all the information, satisfying both the requirements for
IMS GLC and the ISO/IEC metadata definition, and for the
DCMI community. Based on the hierarchical model of the IMS
version, an equivalent version was developed according to the
DC model. This meant ensuring that none of the deeply embedded
information in one model was not available in the shallow format
of the other. The two hierarchies (Appendix
7)
allow for all the information that is available for an IMS
profile to also be available in a DC profile.
So long as this is done correctly, that is, so long as the
DC rules for elements and application profiles are observed,
the metadata can be encoded in a number of ways, particularly
in HTML, XML and RDF(XML).
The DC rules state:
At the time of the ratification of this document, the DCMI
recognizes two broad classes of qualifiers:
Element Refinement. These qualifiers make the meaning of
an element narrower or more specific. A refined element shares
the meaning of the unqualified element, but with a more restricted
scope. A client that does not understand a specific element
refinement term should be able to ignore the qualifier and
treat the metadata value as if it were an unqualified (broader)
element. The definitions of element refinement terms for
qualifiers must be publicly available.
Encoding Scheme. These qualifiers identify schemes
that aid in the interpretation of an element value. These
schemes include controlled vocabularies and formal notations
or parsing rules. A value expressed using an encoding
scheme will thus be a token selected from a controlled
vocabulary (e.g., a term from a classification system
or set of subject headings) or a string formatted in
accordance with a formal notation (e.g., "2000-01-01" as
the standard expression of a date). If an encoding scheme
is not understood by a client or agent, the value may
still be useful to a human reader. The definitive description
of an encoding scheme for qualifiers must be clearly
identified and available for public use. (DCMI,
2000)
Originally, qualifiers of elements were explicitly declared
with a syntax of the type DC:<term>:<qualifier> but now they
are just used as terms as in DC.<Qualifier>. This does not
mean they do not follow the rules, but once this is established,
they are used alone. That a term is a qualification of another
is of significance when the metadata is being transformed
for some purpose: a qualified term's value must make sense
as the term's value, according to what is called the dumb-down
rule. This often introduces some loss of specificity, but
at least means that the information can be transferred without
loss. It also accommodates what might otherwise be hierarchically
structured information.
DC metadata is used for many kinds of resources, not just those clearly destined for use in education. This means that having a DC form of the AfA metadata can provide a way for all resources
to be classified and made available with accessibility metadata.
DC metadata is used in many countries to describe government
information, in libraries and museums around the world, within
software applications such as Photoshop and MS Word, widely
in education, and by international agencies such as the Food
and Agriculture Organisation [FAO]. There is
an inordinate amount of DC metadata in existence. If that
can be both harvested for use in accessibility, and interwoven
with accessibility metadata, the hope is that the vast quantities
will make the difference that only quantity can make - the
network effect will become a possibility. This can be achieved
by using the correct form. The example above shows the alternative
captions in French. If the captions are, in fact, from a
collection of resources for French speaking people, and the
collection is described as using the French language, this
would imply the captions are French. This information might
not be available otherwise when the language of the captions
is being questioned. (This is an example of how the use of
the Semantic Web and Topic Maps can help with accessibility,
as shown in Chapter 6).
Facilitating discovery
of alternatives
One of the significant outstanding challenges for the metadata
work is how to use these new specifications when it is not clear
what the alternatives are and so a search is required to locate
suitable alternatives. It is envisaged that the specification
of display and control characteristics will not be a problem
beyond the existence or otherwise of the necessary metadata but
finding suitable alternative content may be a challenge. The Inclusive Learning Exchange [TILE]
model has so far only worked with content developed with
accessibility in mind and so the closed system can guarantee the availability
of the necessary combinations of components.
Typical problems for the discovery of suitable content distributed across the Web are
exemplified by two scenarios:
- There is a film of the play Hamlet with XXX and YYY as
the lead actors. Those who cannot see the film but can hear
it will require a description of the action but those who
cannot hear it will need a description of the sound effects
and the dialogue.
- The dialogue has been documented in the past (by Shakespeare)
so a text copy with the appropriate control and display qualities
will satisfy their needs but it may need to be synchronised
with the action in the film, so there will be a need for
a synchronisation file (a Synchronised Multimedia Integration
Language (SMIL) file,
for instance). If this is not available, at least having
access to the dialogue should satisfy many users’ needs but
if the user is trying to work on the relationship between
actions and dialogue in the play, they will need the synchronisation
file. If the film does not follow the Shakespearean script,
then there may be an issue with finding a text version of
the film’s dialogue. Again, depending on the immediate user’s
purpose, this may or may not matter.
- It has been suggested that the work defining the functional
requirements for bibliographic records [FRBR]
provides some guidance as to how the appropriate alternative
content might be located. (Morozumi et al, 2006)
and
- There is a Web site that contains resources for students
working on economic modeling. The Web site contains a number
of diagrams that are integral to the text available and yet
cannot be viewed by a blind student undertaking the course.
Her university has a policy that requires all materials to
be accessible to all students and in cases where this is
not immediately true, allows the university staff to create
the necessary alternative content within 24 hours of receiving
a request for it. It so happens that the diagrams in the
course materials were taken from another source where they
were used differently from in the course: in the former case
they were used to demonstrate economic trends and in the
latter to show how certain economic models are diagrammed.
As the blind student has never seen graphs and does not have
any facility with them, they are not suitable for her as
illustrative unless they are accompanied by significant other
descriptive information. As the graphs were generated from
databases, however, there is material that would be suitable
for her in the form of database material.
- This example shows the use of content in a quite different
form and format from that originally made available but where,
again, it needs to be discoverable. It is not obvious that it
is available and so the only way of finding it would be to
search for material with the same content as the originally
offered diagrams, taking no notice of the purpose of those
diagrams in the original teaching resource, and then substitute
the database content for the diagram. This means looking
for content that is described differently from the content
to be replaced but which serves the same purpose for the
user.
In order to make it possible to discover alternatives, it
may be necessary for descriptions of the content of resources
to be mulitply-layered, as in the case of a 'FRBR-type' description.
Such descriptions are not yet common on the Web, but it is
apparent from work in some quarters that this may be the case
in the future (Denton,
2007).
Discovery and use of accessible user interfaces
A universal remote control
At the time when the early AccessforAll work was being undertaken,
Gregg Vanderheiden and a number of people from the National
Institute of Standards and Technology [NIST] and
elsewhere were working on a universal remote control (URC)
in a technical committee working on standards for the InterNational
Committee for Information Technology Standards [INCITS/V2/]
in the area of Information Technology Access Interfaces. The
aim of the URC was to be able to give a person with disabilities
a single remote control device that would be able to talk to
a range of devices. For example, they might use the URC to
control their front door, garage door, car locks, office doors,
office elevator, home air conditioner, microwave oven, etc. The idea was that the remote control device would interact
with the main device, say an oven, to obtain information about
the controls available on that device, and then construct an
interface setup that would allow the user to talk to the main
device using the URC and the new 'skin'.
The URC work typically involved
interesting problems such as those associated with a lift.
If a person goes into a lift well in a modern building, they
usually have to press a button to hail the lift, then another
to indicate where they want the lift to stop, and then another
to shut the door, if it is not already shut, and then maybe
one to hold the door open for a bit linger while they exit
the lift. All this button pressing is very difficult for some
people with disabilities, and very confusing for a person with
a vision disability. The URC was designed to enable them, in
this situation, to simply press a button to indicate where
they wanted the lift to stop. The URC should be able to transmit
information to attract the lift, take it out of the usual pattern
synchronising it with other lifts in the same location, hold
the doors open for longer than usual, or as long as is required,
and then to close the doors, go to the destination, and open
the doors again for longer than usual before merging back in
to the common pattern.
The author was involved in this work at an early stage to
advise on the possibilities for the descriptions necessary
for the URC and the devices it would interact with. By 2006,
it was also being considered as an international standard by ISO/IEC
JTC1 SC35 and has since become a standard as ISO/IEC N24752:2008???.
The URC specifications
As with other AfA specifications, the goal is to use a
common description language so that computers can interchange
descriptive information and make use of it.
An URC is capable of being used with a range of devices,
in a range of languages, and with a variety of accessibility
features. It is, in fact, no more than a platform on which
intelligence is loaded in real time for the benefit of users
confronted by other devices. The type or brand of device
is not important if the URC protocol is observed as each
device can have skins and information specific to its needs
and comply with the generic URC specifications for that type
of device.
So URC compliance is about metadata standards: the description
of device and user needs and commands in URC specified ways
makes for a common language that can be used any time by
an URC, in any context for a user.
Wireless communication technologies make it feasible to
control devices and services from virtually any mobile or
stationary device. A Universal Remote Console (URC) is a
combination of hardware and software that allows a user to
control and view displays of any (compatible) electronic
and information technology device or service (which we call
a “target”) in a way that is accessible and convenient to
the user. We expect users to have a variety of controller
technologies, such as phones, Personal Digital Assistants
(PDAs), and computers. Manufacturers will need to
define abstracted user interfaces for their products so that
product functionality can be instantiated and presented in
different ways and modalities. There is, however, no standard
available today that supports this in an interoperable way. Such
a standard will also facilitate usability, natural language
agents, internationalization, and accessibility. (Sheppard
et al, 2004)
Disabled people are obvious beneficiaries of this technology
(Figure 53) but others, too, will want a more convenient way to control
things in their environment.
The definition of a stable URC standard enables a target
manufacturer to author a single user interface (UI) that is
compatible with all existing and forthcoming URC platforms. Similarly,
a URC provider needs to develop only one product that will
interact with all existing and forthcoming targets that implement
the URC standard. Users are thus free to choose any
URC that fits their preferences, abilities, and use-contexts
to control any URC-compliant targets in their environment, simplifying access to services, for example banking facilities (Figure 54).
We are using the Dublin Core Metadata Element Set (DCMES)
to describe and find the additional resources that may be
needed by a URC using the [Alternative Interface Access Protocol] AIAP. The metadata for the
AIAP defines a set of attributes for specifying resources.
Text labels, translation services, and help items are examples
of such resources. The metadata also defines the content
model needed to interface with suppliers of such resource
services.
The AIAP metadata
is being defined in multiple phases, two of which have been
identified. The first phase deals with the identification
of resources so that they can be found and used. Phase 2
involves establishing metadata for identifying targets (devices
or services), classes of interfaces and user preferences.
Taxonomies will be identified or developed for classifying
values for each of these major areas. (Sheppard
et al, 2004)
Fluid
Fluid is a new project
that also aims to provide choice of suitable interfaces to
people with disabilities, this time for interaction with digital
resources.
Fluid is a worldwide collaborative project to help improve
the usability and accessibility of community open source
projects with a focus on academic software for universities.
We are developing and will freely distribute a library of
sharable customizable user interfaces designed to improve
the user experience of web applications. [Fluid]
Fluid expects to develop an architecture that will make it
possible for users to swap interface components according to
users' needs and preferences, following the AccessForAll model.
This project at the time of writing had started with a demonstration
of a drag-and-drop interface alternative for people with disabilities
(Fluid
Drag-and-Drop).
As with other AfA projects, it is essential that there is
a common language for describing user needs and preferences
and similarly, a matching set of descriptors for interface
components.
Chapter Summary
In this chapter, resource description metadata is considered.
Primarily, the research has been about the use of metadata
to manage digital resources with which users are presented
but, as shown, this process could be used for a wider range
of resources and in a wider range of contexts. indeed, there
are subsequent parts to the original metadata already being
developed by ISO/IEC JTC1 SC
36 and other projects are already
underway elsewhere. In the next chapter, the process of matching
a resource to a user's needs and preferences is considered.
Next -->
 This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile