Chapter
10: Implementation, including Matching
Introduction
AccessForAll anticipates the matching of resources to users' individual accessibility needs and preferences. This can be simplified when all the required components
are available within a single context and similarly described. It is more complicated
when they are either distributed or not yet available. When
automated matching is not possible, it can still be done manually. In this chapter, the matching process as proposed by AccessForAll is considered first. It is then discussed as a strategy for the open Web, using previously unidentified, distributed alternative or adapted resources and resource components. Finally, some implementations of AccessForAll are considered.
Content from this chapter is published in
papers presented at the international conferences AusWeb 2005 in Queensland,
Australia (Nevile,
2005c); DC 2006 in Manzanillo, Mexico
in 2006 (Morozumi et al, 2006), and ASK-IT in 2006 in Nice, France (Nevile, 2006).
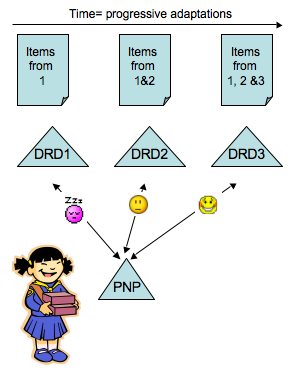
AccessForAll Matching as a Continuous Improvement Strategy
AccessForAll is a strategy for increasing accessibility by
exploiting available technologies to match digital resources
to users' individual accessibility needs and preferences. This
is achieved just in time for the delivery of resources to users
by working with descriptions of an individual user's accessibility
needs and preferences and relating them to descriptions of
a resource's accessibility characteristics. This strategy
supports cumulative and distributed authoring of accessible
components for resources where these are missing, and the reconfiguration
of resources with appropriate components for users (Figure 55).
Compared to resources that are accessible to every potential
user, universally accessible resources, it is hoped that progressively accessible resources
will be less expensive, easier to produce (in terms of skills required),
and developed using practices that are more satisfactoryfor authors
and publishers. Accessible content
can be authored by moderately competent computer
users with no accessibility training using specifications-compliant
accessibility tools [ATAG],
The new AccessForAll approach involves a shift of full responsibility from individual
authors to shared responsibility with technology and a supporting community. Both authoring and delivery software can help. Where components are not universally accessible, for example with all content already available as well-formatted
text that can be rendered in a variety of forms such as auditory,
visual, and tactile, they may need to be re-written either
in a universally accessible form, or with extra components
to replace or supplement the existing components. Suitable authoring tools support this work. The servers
need to check the resources and possibly arrange for services
to manipulate and reassemble them before delivering them. The components that constitute the final resources
may be distributed so the
accessible components may need to be suitably described to enable
their discovery. This means there is a need for metadata
standards that promote interoperability. Finally, there is
a need for descriptions not only of resources but also of user
needs and preferences.
Accessibility is defined by AccessForAll as the matching
of delivery of information and services with users' individual
needs and preferences in terms of intellectual and sensory
engagement with resources containing that information or service,
and their control of it. Accessibility is satisfied when there
is a match regardless of culture, language or disabilities
(Ford & Nevile,
2005).
Howell (2008)
says,
Businesses are now investing a good deal more time and
money into optimising ‘user journeys’ to ensure that the people
using their sites find the route to making a purchase (or finding
the information they are looking for) as quick, easy and enjoyable
as possible.
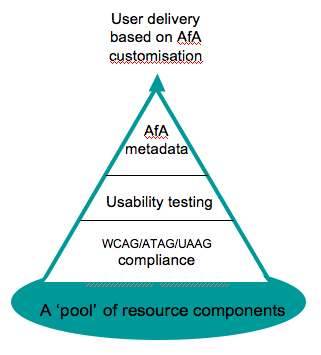
I think of this as a pyramid. Web accessibility is the foundation.
Usability by disabled people is the next layer. And both of
these underpin the ultimate goal: excellent user experiences
by disabled people (and everyone).
A logical extension of Howell's model extends the pyramid (Figure 56):
The Role of Metadata
Metadata is not the resource; it is not necessarily
created by the same author as the resource, and it can always
be added to, authored, by someone else. It can be stored as part of the resource, or with it, or
it can be created by a complete stranger to the resource author
and stored elsewhere (Chapter 6). It can also link two or more resources
that were not initially linked in any way. For increased accessibility
of a resource, a third party may author a new component and
use metadata to link it to the original resource. This can mean an alternative composition of the resource, avoiding components
that cannot be used by the particular user, and delivering
only those that are useful, whatever their source. This can be done post-production and again, by a third party.
An example of the difference between the earlier approach
of depending completely on the production of universally accessible
resources, based on conformant mark-up, and the AccessForAll approach can be imagined in the Australian universities context.
As in many other countries, Australia has anti-discriminatory
legislation that means any student with a permanent disability has the
right to register and be provided with accessible versions of all the resources necessary
for their study. A typical university might interpret this to mean
that they must author all resources in universally accessible
format but typically, will manage at best to do this for only 3% of their resources (Chapter 4). A university using the AccessForAll approach could
provide a student who has recorded their user requirements with what they can use. Alternatively, hey could notify the student that
a resource is not suitable for them and either develop
or find a suitable alternative and link it to the original
by metadata. Then, the next time a student with similar needs and preferences searches for the same resource, there
will be more options available. (It should be noted that it is not always possible to produce an exact equivalent to a resource in a different format. It is perhaps relevant to repeat
here that, without metadata, even a universally accessible resource
that would suit the user is unlikely to be found by someone who
needs it.)
Using metadata, a system can share responsibility for creating the accessible alternative components and making
them available between the content authors
and the repositories or delivery services (the technology). Once there is an alternative for a resource
component, it is a pity if a new one has to be created just
because the existing alternative cannot be found. This means,
of course, that repositories of accessible content should be
online and their collections available and discoverable (see
below). Also, their metadata needs to be online, available, and usable. In the case of communities, such as those sharing a single educational
system, there should be no barriers to the development
of networks of discoverable, distributed, accessible components.
In practice, there is evidence that this approach is being implemented in various ways:
- The Australian Copyright Agency Limited [CAL] has a list of master files that are electronic verisons
of print materials for print disabled people. Unfortunately, this list is only available to people
who are registered with CAL to protect the copyrights but if others could access such a list, thy could also perhaps pay for use of the resource.
- The Victorian Government requires its authors to tag all documents
stating where alternatives are available or who should
be contacted if one is needed. This policy aims to both help the people
with the needs and to bring awareness of the problem
to the people working in the various departments. (Fisher, 2008)
- The University of Technology of Sydney tags materials showing what is useful
to which student and they then watch what is used by students. They use this data
to monitor and help students more
accurately. (Mann, 2008)
- Vision Australia reports that it is engaged in a world-wide effort to make a repository of accessible
alternatives. (Rae, 2008) and IBM has inoduced a new system of tags pointing to accessible altrnativs for pront disabled users (Williams, 2008).
Component reuse
One way Web developers use metadata is to manage the dynamic composition of Web pages. They develop
components and then templates for various different sections
of their Web site and have them populated as they are delivered. This makes maintenance of content
easier and can support accessibility, depending on the templates
and tools being used. In some cases, re-use of single components
can be extensive.
Figure 57, a graphic site map taken from the author's accessibility audit
of some content at La Trobe university several years ago, dramatically demonstrates
component reuse; the La Trobe University logo
is used in every Web page covered by the audit of 48,084 pages
of one of the university sites (Nevile,
2004). This is typical of organisational sites where content is
produced or delivered using templates. Given an inaccessible object, a problem
is transmitted with every page.
Sometimes, a redundant set
of components are transmitted just-in-case. In 2003-4, Fairfax
Digital redeveloped their web site with accessibility in mind
and the result is a saving of an estimated $AUD1,000,000 per
year in transmission costs alone (Jackson,
2004). A bigger publisher would save
even more.
Descriptions of the
accessibility of content of large collections can be done with
tools designed for that purpose, such as AccMonitor [AccMonitor]. Publishers can identify potential
problems and gaps in their resource collections in advance,
as was the case with the La Trobe University Web site when
audited. Evaluation tools of this kind can generate well-formed metadata (Nevile,
2004).
Access For All matching
The Inclusive Learning Exchange (TILE) is both a proof of concept and a model for the matching
of resources to people's needs and preferences. TILE
checks the user's profile and then finds objects from which
to compose a resource that suits their needs. As TILE includes
a tool for creating and editing the user's profile, this can
be done while the user is using the service. TILE uses the
AccessForAll metadata profiles to match resources to users'
needs, with the capability to provide captions, transcripts,
signage, different formats and more to satisfy users' individual needs.
The
TILE prototype has the benefit that within the TILE system,
all the necessary components are available. The resources are
put together dynamically (Figure 58) so it demonstrates the
desired outcomes. It does not offer a model for situations
where the necessary alternative or adapted components are not immediately available or, if they are, have not yet been identified.
Accessibility transformation and repair services
Given that few resources are universally accessible,
one can assume that most resources will need attention if they
are to be rendered accessible for a particular user. As a strong
motivation for accessibility often arises in a community of
users rather than authors, it is not uncommon to find a third
party creating an accessible component for an existing resource
or part of a resource. Usually closed captions for films, for
example, are produced by an organisation specializing in captions.
So are the foreign language versions of the dialogue sound tracks.
A number of organisations offering such resources are listed
in Chapter 7 where the availability of their adapted resource components and descriptions
of them is considered.
Not all adaptation services are performed in advance; some operate instantaneously, using automated
services, while others involve people and take time. Nevertheless,
being able to associate such a service with a resource can
increase its accessibility.
Content management servers
To perform the accessibility match, there is a need for
a service that provides the right combination of content and
services for the user, where and when they need it. This
depends on the user and resource profiles, the context information,
and the pieces that are to be assembled for delivery to the
user as the resource they require.
For a user, or an assistant working with them, it must be
possible to create the necessary profiles and to change them
for the immediate circumstances. In addition, it must be possible
to make formal descriptions of the resources and link all of
these together for the matching process. Technically, this can mean synchronisation and other complex issues arise. It may require higher than usual levels of expertise to employ these technologies.
Publishers who do not have complete sets of components for
all potential users will need to provide or point to services
that can either discover missing components, or create them.
Their servers will need to integrate the new components
without having the original resource 'fall-apart,' so the original
resources should be composed dynamically of components. This calls for
the design of more flexible resources, but can be done. In fact, well designed resources will be transformed reasonably easily. If
good markup is a general practice for a publisher, bringing
in 'foreign' components should be possible without 'destroying'
the original resources. If
the original resource is not well designed, it may become more 'accessible' component
by component but not very usable. This is
sometimes better, however, than if it is not accessible at all.
Where the original publisher does not manage the accessibility,
a third party publisher can upload the original
resource, deconstruct it and test the individual components,
and then find what adaptations are necessary, and so re-construct the resource for delivery
to the user (Kateli, 2007).
The AfA strategy proposed, using technology to augment,
supplement and in some cases replace author expertise, is more
likely to be achieved by a combination of tools and services than the adoption
of a single tool or service. Many of these are not yet available
as one-stop Web services but many are already available as
local system components. The big changes will be possible when they
are made into Web services as this will increase the network
capabilities of the systems, and thus the quantity of sharing
that will be possible.
Such possibilities will only be realised
if there is commitment to them. This is not so difficult to
imagine: the achievements of normal people using word processors,
electronic spreadsheets and presentation tools today are similar
to what could be expected for accessibility in the future with
specially designed accessibility tools and practices as proposed.
Proof of Concept in a Distributed Web
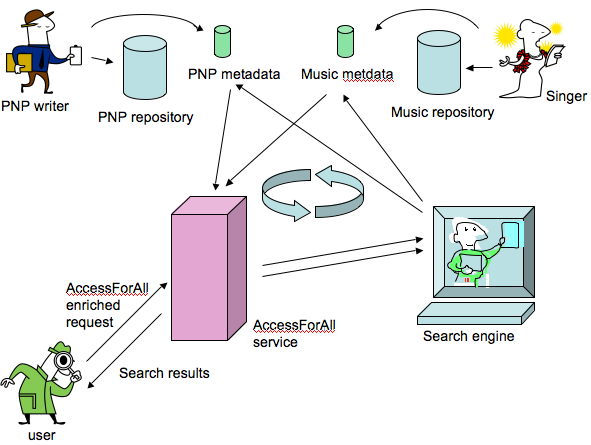
Figure 59: ABC Video on demand wrong picture???
The author experimented with the idea of distributed metadata
'just for fun'. The result was surprising, and pleasing.
A page of the Australian Broadcasting Commission site offering
video on demand [VOD]
was visited. This page had been casually recommended as a well-written
resource. It was hoped that there might be sufficient information
available from the resource for an alternative resource in
a different mode to be found relatively easily using Google.
On the day of testing (26/4/2006), the author took some words
from the 'alt tag' for a video and submitted them to Google
(and Flickr). This led to a blog written in the Solomon Islands [Biukili] that provided text information about the topic – amazing
and satisfying given that the first resource was only several
hours old on the Web, as was the topic. Admittedly news might
be a special case, but the exercise was gratifying. Google
was used but not the special ‘similar resource' features. That
too may have produced a text description of what was in the
video.
Discovery of Unidentified, Distributed, Accessible, Alternative
Components

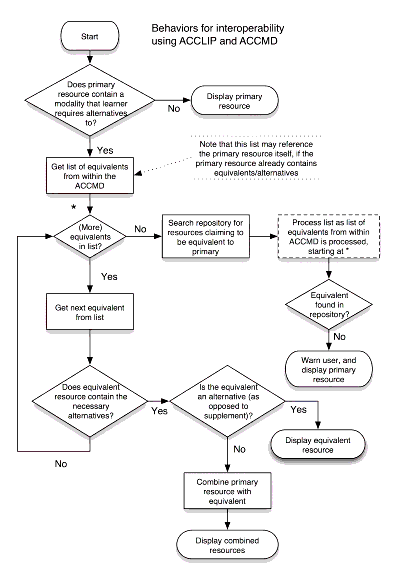
Figure 60: An AccessForAll process diagram
An outstanding issue is then, what metadata is necessary for an accessibility service to
find a suitable resource or component in a distributed environment.
In the usual discovery process, users define the topic of interest
and one or more other properties. In the case of an AccessForAll
search, the user's needs and preferences impose additional
constraints on the suitability of the resource. Initially,
the author and others assumed that this would be easy and
started with a simple model in which the constraints from the user's needs and preferences
profile (PNP) were simply added to a search query (Figure
60).
The problem with this approach is that if no suitable resource
is returned, or if components of a resource are unsuitable,
a new search, with wider search criteria, will be necessary
to find what is needed. This is because the results of the old search
will have already been evaluated, and the original search criteria
already used.
So this is where the use of FRBR becomes relevant (see Chapter 11). If resources are described with their content related to
the intellectual work contained within them, it may be possible
to find other resources or components with similar or even
the same intellectual content.
In order to obtain the metadata that might be needed, it becomes
necessary to not combine the user's needs and preferences with
the other requirements in the primary search, but to use them
to filter the results so that as much metadata about equivalent
resources as possible can be gleaned from the resources found
in the search. For this reason, the original model is
modified as shown in Figure
61.

Figure 61: The modified section of
Figure 60 with a separate filtering service shown
highlighted.
Constructing a new query
There are a number of possibilities,
in fact, for constructing a new query.
Let us assume
a suitable result exists somewhere. (In case there isn't one, we will
have to specify a fail condition.) So let us imagine we are
seeking an alternative for an image that is usually inserted
into a resource. Let that resource be a map, so we are looking
for either a textual version of the content of the map or a
recorded verbal description of it, and for our current purposes,
we assume at least one such component resource exists. In other
words, the problem is not to find a suitable resource so much
as to find a resource with the same intellectual content as
the map we already had in a situation where we did not find
that alternative in the first search. This is not a new problem.
It is a classic problem of how to find
resources like a given one that are not described in a way
that has already found them. There are a number of potentially useful
processes for doing this.
Jeon et al (2005)
have proposed a method for finding similar questions by reference
to the answers to those questions. Another approach is to find
similar words to those used for the original search and then
use the new set of words to search for more resources (Otkidach
et al, 2004). Google offers some simple approaches such
as: press the ‘Similar Pages' button, use the Page-Specific
Search selector on the Advanced Search page,
or use the related search
operator. They even offer a browser button for those who are
doing this frequently [Google]
and provide a detailed explanation of how they find similar
resources (Google
Similar Pages).
Implementation
Implementation of the AccessForAll approach to accessibility can take place at many levels. It is considered a strength of the work that if all that is adopted is a single metadata term, so at best it can still help users find for themselves what they need, there will be value in the effort.
The simplest approach is being taken by the DCMI and the AGLS, standrds that are applied to vast numbers of resources of all kinds in all domains. At the other end of the spectrum, there are instances of implementation where both the description of needs and preferences and of the accessibility features of the resources are used in automated systems to provide appropriate resources for users. Implementation can mean anything in between, as well.
On November 1, 2008, the following was notified to those interested in the content development system ATutor:
Adaptability has always been a high priority in the development of ATutor. Implementing AccessForAll in ATutor 1.6.2 extends further the system's adaptability to the needs of individual learners. With the addition of quite a number of new user preference settings, learners can now customize the environment to work best for them. They can control the appearance of ATutor; which navigation tools are configured; and how content is adapted to their own abilities and learning styles. AccessForAll adds greatly to a learner centered approach to learning.
Implementing AccessForAll (AFA) in ATutor has been (and still is) a challenge. While we worked, IMS AccessForAll 1.0 was in transition, and the new ISO FDIS 24751 Accessibility standard was on the verge of existence. Before the end of our project, the ISO standard was released. According to sources at IMS, AccessForAll 2.0 will be based largely on ISO FDIS 24751. So we transitioned from AccessForAll 1.0 to ISO FDIS 24751, with the intent of conforming with AccessForAll 2.0 when it's ready. We have used the language and the metadata structure from the ISO standard in our implementation, though the systems for creating and sharing content in ATutor, through each standard, function much the same way. (Gay, 2008)
ATutor is a content authoring system developed by the Adaptive Technology Resource Centre [ATRC] , the organisation that also developed as an AccessForAll prototype, The Inclusive Learning Exchange [TILE]. As Gay (2008) points out, implementation has been difficult while the standards have been in development but, nevertheless, there have been efforts underway to use the standards.
By July 2006, it was clear that the AccessForAll approach
was being adopted in the educational domain (Appendix
4). By October 2007, there were 86 resources listed as
relevant to AccessForAll and a glance through the list shows
the dissemination of this idea throughout the academic world
(Appendix 5). The Accessibility
Guidelines that preceded the AfA work were read 176,505
times between
Sept 2002 and June 2006 and in the same period the IMS AfA
Specifications were downloaded 28,082 times. The United
Kingdom Government included the need for metadata in
its standard for accessible documents in the UK (Appendix
6) and on October 16, 2007 the Australian Government
Locator Standard Committee voted to include an AccessForAll
metadata element for all accessible documents in Australia
(Standards Australia IT-021-08,
2007, p. 14). At the same meeting, the
National Library of Australia representative reported that
the NLA is starting to write metadata for individual components
such as images and songs (Standards Australia IT-021-08,
2007, p. 14). This is an important, although
independent, action that will contribute towards implementation
of AccessForAll. Concurrently, the ISO/IEC JTC1 SC35 WG8 is developing
a user profile for use with the
universal resource console (Chapter
8).
As Matteo Boni and colleagues assert:
Accessible e-learning is becoming a key issue in ensuring
a complete inclusion of people with disabilities within the
knowledge society. Many efforts have been done to include
accessibility information in e-learning metadata and the
major result consists in the IMS AccessForAll Metadata definition.
Unfortunately the complex behavior managed by this standard
could be perceived by authors as a new boring and difficult
activity enforcing the idea that the production of accessible
Learning Objects (LOs) is too complex to be accomplished. (Boni et al, 2006)
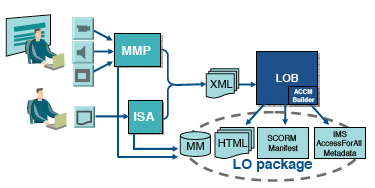
Boni et al, in 2006, described
a novel component of an authoring and
producing software architecture, designed and implemented
to automatically create the IMS AccessForAll Metadata description
of an accessible LO. They integrated the process into the workflow
as shown in Figure 62.
Having described the relevant user needs and resource profiles, Boni et al (2006) continue:
While these metadata represent a truly enabling option,
implementing an ACCMD description of each LO could turn
into a new tiresome and protracted task for authors.
Reducing the distance between users’ needs and authors’ efforts
is
now a crucial aspect to ensure accessibility of e-learning
materials. The solution relies on authoring tools for creating
LO
that have to accomplish two main goals:
1. Offering support to author in creating fully inclusive
materials by suggesting correct behaviors and
sometimes imposing the completion of all additional
information needed to ensure accessibility (e.g. once the
image is inserted, the authoring tool ask for a
description that is required for blind users).
2. Automatically structuring the media alternatives, both
inserting correct markup inside the (X)HTML pages and
describing the whole structure with ACCMD. (Boni et al, 2006)
They say:
Such a tool is now integrated in a complex process used
inside the
University of Bologna to create accessible LOs. Accessibility
of
e-learning materials produced has been widely tested by involving
a group of people with disability in verifying on-line contents
and
services. Universality of materials has been tested by using
different browser running on different platforms (specifically
MS
Internet Explorer 5.0 and later, Mozilla Firefox 1.0 and
later, Netscape Communicator 7.0 and later, Lynx 2.8.4 rel.
1, IBM Home Page Reader 3.0, Apple Safari 1.0). Finally,
LOs produced by our process are compliant to all the constraints
considered by
the Italian Law on Web Accessibility, (Boni et al, 2006)
That tool and its use are described
in more detail in "Automatically
Producing Accessible Learning Objects"
(Di Iorio
et al, 2006). Similarly, the research has reported using
an accessibility evaluation tool that can produce the necessary
metadata (Nevile,
2004).
But Boni et al say:
Unfortunately, the IMS description is ignored by the LCMS
(Learning Content Management System) in use. Generally this
new technology is not fully supported and there are just
few
solutions that use ACCMD and ACCLIP to provide adaptive
accessible contents. We assume that a growing availability
of IMS
ACCMD tagged LOs will drive the development of adaptive
modules for the more diffuse LCMS and will definitively diffuse
the use of the whole IMS specification on accessibility.
The ATutor development team seem to have heeded the suggestion from Boni et al. Unfortunately, the ATutor development team is closely connected wih the AccessForAll work, so not indicative of what is being done generally towards AccessForAll implementation.
So the problem being considered here is the one of production of metadata. There are many ways this can happen:
- as a direct result of automated classification (of characteristics susceptible to automated evaluation) by authoring systems or accessibility evaluation systems, as exemplified by ATutor, AccMonitor, and others.
- as authored content, contributed within a workflow of authoring content, as proposed by Boni et al.
- as metadata provided by a third party classification process, such a within a library cataloguing system.
- as third party, independent metadata made available on the Web, or
- as tags, contributed to a metadata pool, as in the case of a system such as del.icio.us.
So the problem is not how should this be done in a technical sense, but how can the critical quantity of metadata needed to be useful, be motivated. As already shown in Chapter 7, there are alternative resources available for users with some special needs and there is some metadata, but it is not in the AccessForAll format. In recognition of the problem that metadata is not easy to come by, and reliable metadata is even more scarce, the author has worked with the Dublin Core Metadata Initiative for a decade. The relative simplicity of DC metadata and its generality in domain has made it one of the most popular, and thus prolific metadata standards.With the hope that by implementing the AccessForAll approach within the DC metadata context, the research has focused on this goal.
DC AccessForAll Proposal
A proposal for two DC terms has been submitted to the DCMI Usage Board by the DC Accessibility editor as a result of the research (Nevile, 2008).
from table:
Accessibility Requirements Table
Name http://purl.org/dc/terms/accessibility
Label Accessibility
Definition A characteristic of a resource that relates to the human capacity to perceive, operate, understand or otherwise engage with the resource.
Comment An Accessibility statement might be used to match a (digital or physical) resource to a description of user or user agent needs and preferences.
For this to be likely to succeeed, the author had to find a way of defining terms that would be likely to be used as tags and so two terms and their potential values have been submitted to the DCMI Usage Board for approval (ref???). The first is a 'positive' tag and the second a more 'negative' tag. For the first, one imagines a user finding a resource that works well for them, or that the authored, and adding a tag to the resource indicating that it is, say, video, which means it does not do anything more, does not have alternatives, This is a fairly positive and useful thing to do, as it will alert those looking for a video version of content that this is one. As well, once it is known that the resource is video, others can identify it as such and make an alternative version for it, if they so choose, and even tag the alternative too. On the other hand, if a person is having problems with a resource, and cannot access it because it is, say, video without any associated alternative, they might tag the resource as videoOnly. If such tags, or metadata, are freely available and plentiful, they will make the task of discovery easier for a user with a special requirement and for the task described above, where the author was looking for an alternative, making its discovery ever so much easier.
AccessForAll recognition
Implementation of AfA is not yet simple. While there is a
set of machine-readable resources to help those implementing
it in the educational context where they use IEEE LOM metadata,
this is not yet the case for DC metadata, expected to be a
much larger implementation context. Nevertheless, the signs
are very positive as shown by the emerging evidence of acceptance
of the AccessForAll approach.
Michael
J. Halm says:
The importance of the ACCLIP specification may not be immediately
understood, but this specification provides enormous opportunities
to customize and adapt the learning experience based on the
users preference. This powerful capability now can
be used for anyone, not just those with disabilities. These
preferences will be stored in the Learner Information Package
and could travel with the learner from one on-line environment
to another. Since these preferences are created and
maintained by the learner, this gives the individual the
control to change the environment as needed. This also allows
one to consider the learning style of the learner as part
of the environment. Visual learner will be better able
to set preferences that are unique to the type of way they
learn. This preference can translate into the type
of learning objects that are selected and deliver in the
learning environment. (Halm,
2003)
W3C recognition of AfA metadata in POWDER
The World Wide Web Consortium [W3C] endorsed the AccessForAll approach in the set of POWDER use cases that include the following, contributed to by the author,:
2.1.6 Web Accessibility B (self labeling, content features,
profile matching)
- Colin is a student at the world university. Colin sometimes
studies at home with special Braille equipment but likes
to listen to course readings when he is on campus, using
a screen reader (profile 1). His sister Mary sometimes likes
to work with him, sharing a computer and describing what's
happening, as they are studying the same subjects (profile
2). When Mary is studying alone she uses no assistive technology
(profile 3). Between them therefore they have three profiles
of needs and preferences and may change between them. The
profiles impose different requirements on the resources that
Colin and Mary can use adequately.
- The university's staff produce teaching materials in alternative
versions to suit different user needs as closely as possible.
Staff are trained to create labels describing the accessibility
features of their materials with AccessForAll Metadata [AFA].
- The university's web site has an application that stores
profiles of user needs also expressed in AccessForAll Metadata.
The system analyses content labels embedded in course materials
and uses rules to discover alternative versions of content
suitable for a user's active profile.
- For Mary studying alone (profile 3) a complex diagram
may be presented as-is, but if she is studying with Colin
they may select profile 2 and the system discovers and delivers
to them the same image of the diagram together with a detailed
text description. If Colin is alone he cannot see the image
and selects profile 1 to read only the text description. (Archer,
2007)
Engage
The IMS Tools Interoperability project is part of the Engage project
at the University of Wisconsin (UW-Madison). The Engage program partners
with UW-Madison faculty and academic staff to apply innovative
uses of technology for teaching and learning. In this project,
UW-Madison, WebCT, Blackboard, Sun Microsystems, SAKAI, QuestionMark,
and staff from Stanford, UC Berkeley, MIT, Indiana University,
and the University of Michigan are all involved. A special
server edition of ConceptTutor, and a Moodle LMS were proposed
for 2005 Alt-i-lab [Alt-i-lab
2005] conference in Sheffield, England in June 2005.
The aim is:
To promote accessibility and to demonstrate the use of IMS
ACCLIP and ACCMD standards for accessibility, we have modified
Fedora to implement an RDF binding of ACCLIP and ACCMD. A
student’s accessibility preferences are matched to the accessibility
characteristics of the content at the time of the request.
Thus, a visually impaired student will receive content tuned
to her needs when she requests a ConceptTutor without having
to know how to request the specially tuned content. (Engage,
2007)
SAKAI
SAKAI Collaboration and Learning Environment for
Education [SAKAI] is a university consortium effort to develop a set of
open source tools for tertiary education. On Feb 20, 2007, Anastasia Cheetham announced:
The TransformAble package is now a part of Sakai. TransformAble is being developed by the Adaptive Technology Resource Centre at the University of Toronto. It is useful for users who want to customize Sakai's appearance to improve the readability and accessibility. TransformAble consists of two parts: StyleAble is a component that generates customized style sheets based on a user's stated preferences, allowing them to control the overall appearance of the site, including the font size, face, foreground colour, background colour, highlight colour, and link appearance. User preferences are created through a tool currently called PreferAble, which (once un-stealthed) can be added to any workspace. (Cheetham, 2007)
Fluid
The Fluid Project [1] is an international community of academic institutions, open source software projects and corporations working together to address the precarious values of usability and accessibility within open software projects.
Fluid is creating a library of accessible, rich Web 2.0 user interface components that can be reused across web applications. These components are built specifically to support flexibility and customization while maintaining a high standard of design quality. The Fluid framework will enable designers and developers to build user interfaces that can more readily accommodate the diverse personal and institutional needs found within open source projects.
Personalization and User Interface Metadata with AccessForAll
The rich user interface customization and flexibility of the Fluid architecture depends on the availability of clearly defined standards for UI component semantics and user preferences. These semantics will provide the basis for conveying the nature and context of UI components to the framework, enabling the transformation and substitution of suitably marked-up components at runtime.
The Fluid community is driving new additions to ISO/IMS AccessForAll [6] specification relating to user interface transformation. This work will be broadly useful for Web 2.0 applications, providing a foundation on which to build accessible mash-ups and user interface components. We are currently in the process of defining a new branch of the AccessForAll standard to describe how user interfaces are controlled and presented to the user, as well as a matching set of user preferences metadata. (Clark & Schwerdtfeger, 2007)
Fluid is thus adopting the work on AccessForAll. In addition, the Fluid work has led to the addition of two new draft parts for the ISO/IEC standard, N24751, Parts 9 and 10 (ref???).
Metadata in WCAG 2.0
In late 2007, the WCAG Working Group is finalising Version
2.0 of WCAG. The editors were not sure what to do about
metadata. It produced some interesting challenges. The
AccessForAll position, put by the author to the WCAG WG, is
that there should be metadata to describe the content of every
resource, including its accessibility characteristics, on every
Web page that is considered accessible. The Chair of the WCAG
WG, Gregg Vanderheyden considers that
in the case where a page is accessible in the sense that it
is conformant, someone who wants a version of the page that
happens to suit them but is not fully conformant, might want
to find that alternative version. As Jutta Treviranus wrote, :
I think we are missing the point. An important consideration
is that Metadata does not require and is not about conformance.
It is about labelling and finding accessible resources. You
need to think beyond a single site or a single page. If there
are a number of resources and some are accessible to you and
some are not, Metadata helps you to find the ones that are
accessible to you or alternatively to gather the same information
as the Web resource you want from a number of pieces that are
accessible to you. So is WCAG only about access to a single
site or about access to the Web? If it is about access to the
Web then you need to think about systems and varied resources,
some that are more accessible to a given user and some that
are not. (Treviranus, 2007)
Sadly, some think, the response to this was:
This is beyond the scope of WCAG 2.0. It sounds like a good
candidate for the next version.
WCAG 2.0 is addressing the accessibility of Web pages, the
unit of conformance. There are a number of other issues related
to the larger view of the web that have also been deferred
to future work. (Reid, 2007)
A major constraint for W3C's work is that it needs to result
in technical specifications; nothing can be recommended
that cannot
be tested. Another constraint is that it must be possible in
every case. Vanderheyden posed the problem of the resource
that is to be published but, by law, cannot be altered any
way in the process. An example is an historic digital image,
that has value in being that image. This means that metadata could not be added to it and nor could
even a link to metadata. Fortunately, on the day this problem
was to be solved, another W3C WG released their first version
of a solution. The Internet Content Ratings Association community
[ICRA] want to be able to add metadata about resources that is very
similar to the AfA metadata in type - they want to describe
the relevant characteristics of resource content that leads
to ratings for nudity, violence, etc. The W3C Protocol
for Web Description Resources (POWDER) Working
Group [POWDER WG]
developed POWDER to enable information to be conveyed via the
HTTP head of a resource and this is just what is needed for
the Vanderheyden problem. The issue is what is to be conveyed,
and the POWDER WG has now modified their examples to include
two use cases that draw upon AfA metadata.
Distributed Accessibility
While the TILE model can be extended within a given context,
it is probably not until the AccessForAll approach is working across vast numbers
of resources and contexts that it will really start to pay off
for the individuals. The issue is: if a component is not accessible,
how can an alternative resource, or component or service be
discovered on the Web, if there is such a thing?
There are at least three approaches being considered; FRBR
descriptions, OpenURIs and POWDER. GLIMIRS????
The author asserts that if it
is easier to find alternatives on the Web, and items of interest
in one mode are also available in other modes because more
items are available and they are discoverable, providing users
with alternatives to inaccessible content will become more
of a community activity and thus more successful. If this hypothesis
is right, the burden on individual content developers can shift
a little from the frustratingly unsuccessful one of requiring
all content to be provided in universally accessible
form, to a requirement to provide accessibility services.
In the rare case where a resouce for
some reason cannot be associated with metadata, for example
when it is a special archive and by law cannot have any changes,
not even the addition of metadata, it may be possible to use
the POWDER protocol and put metadata in the HTTP header.
The future
There is a growing community who are
publishing small objects on the Web and even offering some
description of them. Social activities are then taking over
and others are adding ‘tags' to those objects. As, in the end,
such tags may be more plentiful than other metadata, we are
interested in how this activity may serve to increase the effectiveness
of our process.
Increasingly, images are ‘tagged'
by either their creators or others. If an image is tagged,
using such online systems as Flickr,
the tags could be used to discover a text resource that has
the same intellectual content. We are aware that while it can
be asserted with some confidence that tagging of images and
the number of images on the Web is increasing, it is not yet
clear if the same will be true for resources in other modalities.
Although there is not an obvious rush to place text versions
of sound files on the Web, there is a strong move towards more
atomic resources and, in many cases, those are small ‘chunks'
of text. The drive behind this move is the growing interest
in Really Simple Syndication (or RDF Site Summary) [RSS]
feeds, and many people are responding to this use of personal
‘pull' technologies by publishing in ways that support RSS.
There is, then, some hope that there will be small chunks of
text that are tagged and may be useful as alternatives to images.
The Dublin Core approach to AccessForAll provides an opportunity to take advantage of tagging. The author has proposed to a software developer that they provide a widget that will work like the usual tags, eg de.licio.us.org tags.
Chapter Summary
In this chapter, the proposal for matching of resources to users' individual needs and preferences based on a user needs and preferences profile is considered. The matching can be done by the user themselves, in the discovery process, but it is suggested it will be far more useful if it can be automated at least to some extent. In the case of people with severe permanent disabilities, it may be essential that the process is automated. It is also very important that the profiles remain alive as the user engages with the resources, so they can be changed, if necessary.
In the next chapter, the importance to these requirements of interoperability is considered.
Next -->
 This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile