Chapter 1: Preamble
Introduction
The [United Nations] Convention on the Rights of Persons
with Disabilities and its Optional Protocol were adopted
by the United Nations General Assembly on 13 December 2006,
and opened for signature on 30 March 2007. On 30 March, 81
Member States and the European Community signed the Convention,
the highest number of signatures of any human rights convention
on its opening day. 44 Member States signed the Optional
Protocol, and 1 Member State ratified the Convention. The
Convention was negotiated during eight sessions of an Ad
Hoc Committee of the General Assembly from 2002 to 2006,
making it the fastest negotiated human rights treaty. The
Convention aims to ensure that persons with disabilities
enjoy human rights on an equal basis with others. [UN
Enable, 2008a]
By March 31, 2008, there were 126 signatories to the United
Nations Convention, 71 signatories to the Optional Protocol,
18 ratifications of the Convention and 11 ratifications of
the Optional protocol (not including Australia) (UN
Enable, 2008a). In an information
era, everyone should have, one way or another, an equal right
to information if they are to participate equally in the information
age. The general aim of the new United Nations convention is
to ensure that people with disabilities are treated inclusively
as are other groups of people identified in earlier conventions.
In particular, this convention calls for inclusive access to
information and communications for people with disabilities,
and specifies a number of situations in which these rights
must be enforced, including for work, entertainment, health,
politics and more (UN,
2006).
This thesis has, at its heart, the idea that inclusive treatment
of people eliminates the need for special considerations for
people with disabilities. This is derived from the social
model of disability (Oliver,
1990b). First, it attends to the limits on people's abilities
to participate in society rather than on any medically defined
'defect' they may be considered to have. Secondly, it supports
equally able-bodied people who for one reason or another cannot
participate equally.
The social model of disability spreads responsibility for
inclusion across the community. This research aims to enable
continuous, distributed, community effort to make the World
Wide Web inclusive.
For a decade, efforts to make the Web accessible have focused
on following, or otherwise, a set of guidelines that have come
to be treated as specifications. These guidelines, based on
an accessibility model that assumes a single resource could be made available to everyone (universal design), have proven inadequate to
ensure accessibility for all. Recent estimates of the accessibility
of the Web are as low as 3% (e-Government
Unit, UK Cabinet Office, 2005). The research indicates
that the current level of reliance on the universal accessibility model is flawed.
If a user is blind, eyes-busy or using a small screen, instructions
about how to get from one place to another presented as a map
may be incapable of perception while a text version that can
be read out and heard would be perceptible. Providing a text
description of travel routes is an example of an accessibility
improvement for a map. Managing the map and the new version
so that it is associated with the map, and discoverable at
the same time as the map, is what catalogue records or metadata
can do for digital objects.
The research advocates a process to support ongoing
incremental improvement of accessibility. This depends upon
efficient management and description of distributed resources
and their improvements, and descriptions of them. These can
be matched to individual's needs and preferences. The
research elaborates what is called AccessForAll metadata (Nevile & Treviranus,
2006),
a framework for descriptions of resources and resource
components. AccessForAll metadata provides for a common set
of descriptions so that they can be shared, so they will interoperate
across description protocols, and so they can be used by computers
to automatically match resources to users' needs and preferences.
AccessForAll metadata includes provision for a common way of
describing people's needs and preferences.
Metadata, used in the research as an enabler, is only so in the ways required when it is interoperable, that is, is usable by many systems. Interoperability is an elusive quality. Interoperability does not include something as simple as two systems sharing the same software, as with an office software package, for instance. Interoperability across the vast complex systems of the World Wide Web (the Web) is demonstrated when systems that do not operate the same way, that are not multiple copies of the same software, that have not been purpose built to work together, share common standards of specification, and can share data. Metadata is data about data, and therefore itself data. Interoperabiity enables unprecedented quantities of data to be applied to a single instance and, as has come to be recognised in the context of the Web, 'quantity has a quality all its own' (often attributed to Joseph Stalin).
The research analyses and synthesises the metadata development work of the AccessForAll team and comes to the conclusion that there is a simple methodology for developing interoperable metadata standards, such as the AccessForAll standards. This process was not followed in the case of the first AccessForAll work with the result that all the problems reported in the research were encountered. The steps in the recommended process are:
- develop (or adopt) an interoperable, extensible model for metadata production and make it explicit (e.g. the Dublin Core Abstract Model [DCMI DCAM];
- analyse the needs within the context (e.g. the needs of users of digital resources who might use the chosen range of digital agents);
- determine a set of elements that cover the field with no ambiguity;
- define the elements;
- establish values or value types for each element and provide definitions;
- publish all information in a digital metadata registry (so others and their computers can access it [DCMI Metadata Registry], and
- seek adoption by as many people as possible.
The research distinguishes the context in which earlier
accessibility work took place. It adopts a fiction and describes the development of the Web as happening in phases named Web 1, 2 and 3. In what might be thought
of as a Web 1.0 environment, one-way publishing was the
dominant activity. In the Web 2.0 environment,
interactive user-participation publication happens across the Web in unpredictable
ways, despite authors and publishers who provide well-structured,
cohesive Web sites. In the emergent Web 3.0, data is organising itself. Many users 'Google' and
they approach information from a range of perspectives and directions,
often coming into resources through what is effectively a back
door, and taking from resources what is of interest idiosyncratically to them, disregarding
or discarding the rest.
The research also relies upon the interactivity
and energy available from what is known as social networking
that is well established within the Web 2.0 environment (Flickr, YouTube, LibraryThing, Facebook,
etc). It exploits new technologies to solve an old problem
and to share the responsibility for the problem well beyond
the practices, knowledge, and expertise of the original resource
authors. In this sense, it anticipates an even more active
Web, where users design, create and control the published
content and the content reorganises itself for the users. No longer do users just ‘browse’ a static, manually-published Web.
The research is not limited to classic 'Web pages', but includes
access to all resources, including services, that are digitally
addressed.
AccessForAll metadata already describes digital resources and
is being extended to describe a wider range of objects including
events and places (ISO/IEC
JTCI SC 36, 2008). Descriptions of the accessibility of
those places and events will
be Web addressable, so the necessary access to those descriptions
will be 'on the Web'.
Background
The United Nations publishes a map (Figure 1) that shows
involvement in the United Nations (UN) Convention for the Rights
of People with Disabilities.
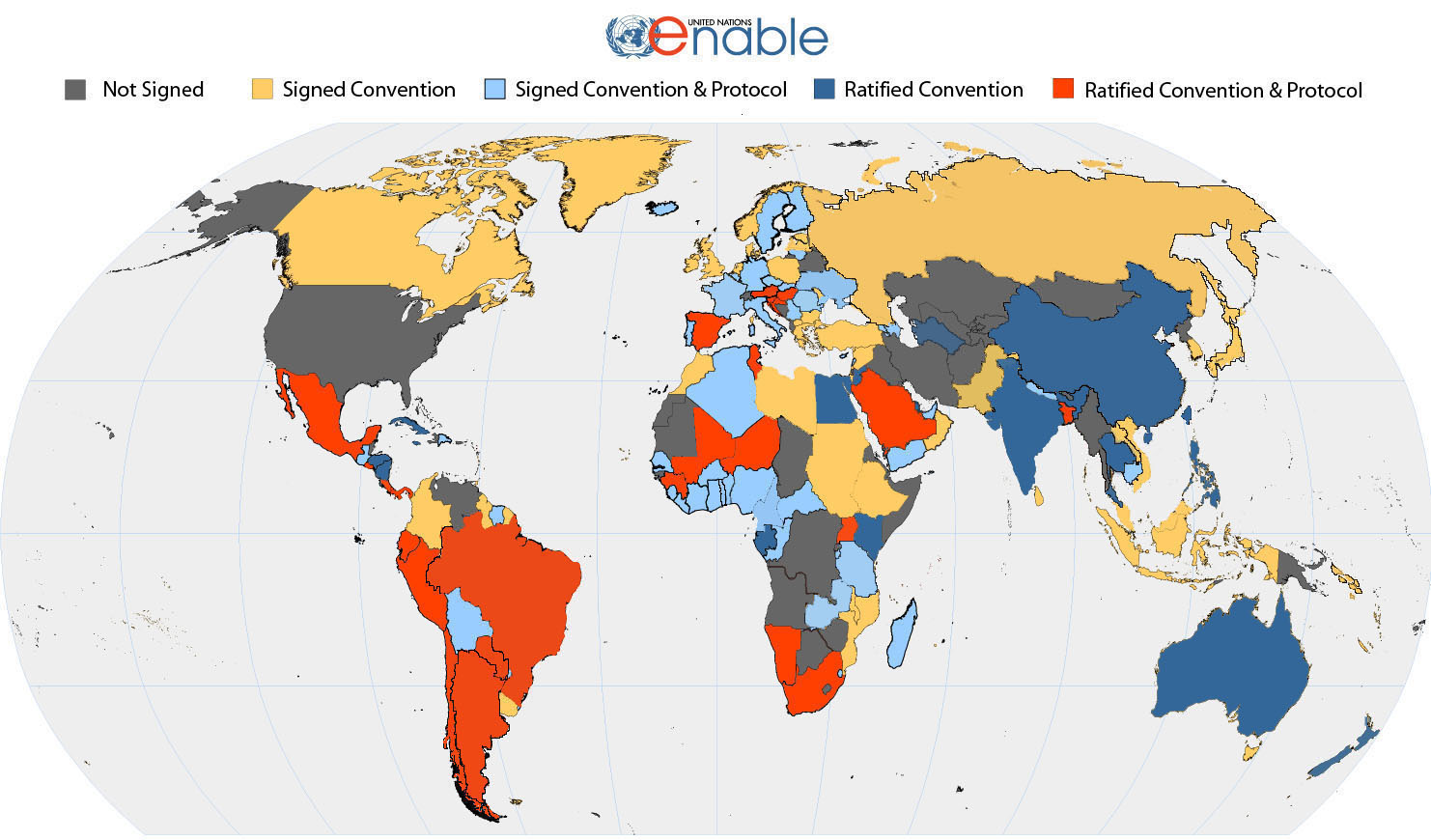
Figure 1: Map showing signatories of UN Convention for the Rights
of People with Disabilities in November, 2008 (UN Enable, 2008c)
Australia signed the Convention in 2007 and ratified it in July 2008, with some declarations and reservations (UN Enable, 2008b), more than eighteen
months after the Convention was adopted by the UN, Australians have been
involved for many years in international efforts with a range of standards organisations (W3C, ISO, IMS
GLC, CEN, and others), to
ensure that information technology and digital resources are
accessible to everyone. They have actively participated
in the work of the World Wide Web Consortium [W3C]
and others to curb the alienating effects of new multimedia
technologies on the Web.
The recent United Nations convention on the rights of people
with disabilities clearly states
that accessibility is a matter of human rights. In the 21st
century, it will be increasingly
difficult to conceive of achieving rights of access to education,
employment health care
and equal opportunities without ensuring accessible technology.
(Roe,
2007)
Making the Web accessible to everyone has proven more difficult
than anticipated. While Roe (2007)
considers the value of accessibility to be far-reaching,
Constantine (2006)
summarises the unfortunate reality; much as one might like
to make the Web accessible, it is not accessible and is
not likely to become so. The attitude of those who could make the difference is too often 'unhelpful'.
At the Museums and the Web 2006 conference,
one word had the power to abruptly silence a lively discussion
among multimedia developers: accessibility. When the topic
was introduced during lunchtime conversation to a table
of museum web designers, the initial silence was followed
by a flurry of defensive complaints. Many pointed out
that the lack of knowledgeable staff and funding resources
prevented their museum from addressing the “special” needs
of the online disabled community beyond alternative-text
descriptions. Others feared that embracing accessibility
in multimedia meant greater restrictions on their creativity.
A few brave designers admitted they do not pay attention
to the guidelines for accessibility because the Web Content
Accessibility Guidelines (WCAG) 1.0 standards are dense
with incomprehensible technical specifications that do not
apply to their media design efforts. Most importantly, only
one institution had an accessibility policy in place that
mandated a minimum level of access for online disabled visitors.
Conversations with developers of multimedia for museums
about accessibility were equally restrained. Developers
frequently blamed the authoring tools for the lack of support
for accessible multimedia development. Other vendors simply
dismissed the subject or admitted their lack of knowledge
of the topic. Only one developer asked for advice on how
to improve the accessibility of their learning applications.
(Constantine,
2006)
The same response has been experienced frequently by the author, who confronted some very influencial metadata experts to be told they just felt like cringing when they heard the word 'accessibility'. Not, they said, because they did not think it was important, but because they just did not know what to do and so felt bad. (The name of the Dublin Core proposed element was actually changed, for a while, to 'adaptability', for the benefit of such people (Nevile, 2004b).
Roe (2007) elaborates
the extent of the problem being avoided:
About 15% of Europeans report
difficulties performing daily life activities due to
some
form of disability. With the demographic change towards an
ageing population, this figure
will significantly increase in the coming years. Older people
are often confronted with
multiple minor disabilities which can prevent them from enjoying
the benefits that
technology offers. As a result, people with disabilities
are one of the largest groups at risk
of exclusion within the Information Society in Europe.
It is estimated that only 10% of persons over 65 years of age
use internet compared with
65% of people aged between 16-24. This restricts their possibilities
of buying cheaper
products, booking trips on line or having access to relevant
information, including social
and health services. Furthermore, accessibility barriers in
products and devices prevents
older people and people with disabilities from fully enjoying
digital TV, using mobile
phones and accessing remote services having a direct impact
in the quality of their daily
lives.
Moreover, the employment rate of people with disabilities
is 20% lower than the average
population. Accessible technologies can play a key role
in improving this situation, making
the difference for individuals with disabilities between
being unemployed and enjoying full
employment between being a tax payer or recipient of social
benefits.
(Roe,
2007)
People with disabilities who are
alienated by inaccessibility are regarded by Australian law
as
discriminated against (HREOC, 2002). They are able to
claim damages from those who discriminate against them if
all relevant conditions are satisfied. This means Australia
recognises a general right. It is incumbent on
a victim to prove, within the legal system, that they have
unreasonably suffered from discrimination. Although this has been done, reported cases are rare, as with
other cases likely to provoke negative publicity. Such cases
would normally be settled out of court where possible, and
so not publicly reported. Such a legal situation does not
operate as a major threat to large organisations, especially
as the damages judicially awarded so far have not been substantial, e.g.
Maguire v Sydney Organising Committee for the Olympic Games.
(HREOC,
1999)
Accessibility efforts in many cases aim to make a single
resource universally accessible to everyone.
Universal accessibility involves providing the same resource
in many forms so that people with disabilities can use the
full range of perceptions to access it across
all platforms, fixed and mobile, standard and adaptive. Universal
accessibility is distinguished from individual accessibility
or accessibility to an individual user. Many resources are
individually accessible while not universally accessible and
many universally accessible resources (as defined by the standards
in use) are not accessible by some individual users (see Chapter
4).
Reinforcing the disinclination to worry about accessibility
is the common belief that it costs a lot to make resources
universally accessible (Steenhout,
2008). Frequently it is left to a semi-technical
person in a relatively insignificant position within an organisation
or operation to champion accessibility as best they can. Anecdotally,
they frequently report that all was going well until the resource
was about to be released. Then the marketing manager or some
other more significant participant chose to add a particular
feature and not be constrained by accessibility concerns.
(In the 1990's, Nevile was responsible for the accessibility
of two major government portals, the Victorian Better
Health Channel and the Victorian Education
Channel. In both cases, late requests for changes threatened
the integrity of the sites but fortunately, in the end, the prior work
made it possible to avoid any ill-effects of the changes).
Economic factors are important in the context
of accessibility. Many assume that accessibility means more
expenses when resources are being developed and more resources
being supplied to the range of users of those resources. It
is true that making an inaccessible resource accessible can
take considerable effort, expertise and expense and, even
then, is not always possible. On the other hand, some publishers
are finding that by making accessibility a priority, they
actually gain financially through cost savings (Jackson,
2004,
Chapter 3).
Practicality is important. It has long been known that it
is not always possible to make an inaccessible resource accessible
without having to compromise some of the characteristics of
the resource, depending on what sort of resource it is. If
designers provide an attractive 'look and feel' for a Web
site, for example, it may not be possible to have exactly
that look and satisfy all the accessibility specifications.
Additionally, those who are experts in accessibility are not
usually designers but more often technical people. In practice,
a designer who understands and works within the accessibility constraints
is able to design creatively and avoid the accessibility pitfalls.
One
common reason that resources are not accessible is that they
are dependent on a software application that does not render
the content, or does not control or display the content in
ways that make it accessible to everyone. Many people with
permanent disabilities use specialised equipment or software to gain
access to content. Many users have mobile phones,
and or use screens with content projected on to them,
or printers, or old computers. Sometimes the content creator
takes the end user into account. Unfortunately,
this often means they arbitrarily anticipate too much, for example,
that it will be printed on local-standard sized paper, in
which case they fix the electronic version of the resource
to match the way they expect it to appear on paper. This does
not always work for the paper version because the local standards
differ. Neither does it work for the digital version because
rarely are screen sizes or windows appropriate as anticipated.
In
cases where users have unusual needs or preferences, such
as a need to change the font size or reverse the colours of
the background and foreground, it is rare that the necessary
changes can be made. It is possible, however, where the digital
version of the fixed-print version is encoded correctly.
The World Wide Web Consortium [W3C]
has developed a technology that allows a single resource to
be presented in a variety of ways, depending on the medium,
and explicitly for the user to use a suitable form of presentation
and override any made available by the publisher of the
resource or the browser software [Cascading
Style Sheets, CSS]. This is achieved by separating the
content from instructions about how it is to be presented.
Many think of the Web as 'homepages' or Web sites. This is
not sufficient. A Web page may contain links to documents
that reside in databases, open or closed, and those 'documents'
might be simply some application-free content,
or they might be complex combinations of multimedia objects,
even dynamically assembled for the individual user, and locked
into specific applications. Even physical and ephemeral objects are included in the Web, such as when a cinema is listed as showing a film or a football match is advertised.
The
Web Accessibility Initiative [WAI]
is the arm of W3C that focuses on accessibility for the Web.
WAI distinguishes between two classes of software used in
this context; authoring tools
and user agents.
The classes include software that does very different
things according to what it is being used to author or
access, which can range from literature to computer code,
images to tactile objects. Authoring tools should both produce
accessible content and be accessible, according to the relevant
WAI guidelines (Authoring
Tools Accessibility Guidelines [ATAG]). User agents are
the software applications used to access the content. They
also should be both accessible and do the right thing
with the content so that it is rendered in an accessible way
(User
Agent Accessibility Guidelines [UAAG]).
(The user agents are often Web browsers
but they can take many forms.)
The original WAI set of guidelines, one each for
authoring tools, users agents and content [WCAG-1, ATAG, UAAG],
have been in constant development or revision for more than
a decade (Chapter 4).
They have been adopted in various ways in many countries and
used by developers all around the world. Despite this incredible
effort, the Web is still far from accessible to everyone (Chapters
3, 4).
The underlying principle for these guidelines has continued
to be universal design, to be achieved by having a
single resource that can be used by everyone.
In recent years, total dependence on the WAI work and its
derivatives (such as s.
508 that was added to the US Disabilities Discrimination
Act [DDA])
has been re-examined and a range of post-production solutions
are being proposed. In particular, methods have been developed
that support increasing the accessibility of a
resource by a third party, unrelated or connected to the original
publisher. ubAccess,
for example, developed a service [SWAP]
that could assist people with dyslexia who were having problems
with resources, without reference to the original creator
of the resource. In a similar way, a service called Access
Monkey operates to assist blind users without reference to
the original author of the resource (Bigham
& Ladner,
2007).
More and more such services
are emerging. What is significant is not simply
their number. It is that they represent a significant
shift in thinking about accessibility. If resources are not
going to be created universally accessible, or found in a
universally accessible form, and it is unlikely there
will be a significant change in this situation, it makes sense
to think more about what can be done post-production.
Post-production techniques were a feature of the 2007
OZeWAI Conference. Pierre
Frederiksen demonstrated how to automatically make a complex
table accessible post-production to users not relying on vision and
Charles McCathieNevile
showed how an established inaccessible technology can become
an accessible technology simply by the adoption of suitable
encoding techniques (OZeWAI
2007). McCathieNevile demonstrated
the techniques for Asynchronous JavaScript and XML [AJAX].
Hudson and Weakley (2007)
argued that now social networks are common on the
Web, collaborative action can be taken quickly. They argued
that the emergence of techniques for developing or repairing
inaccessible technologies, as in the case
of AJAX, is quick when developers and users and others involved
all agree on a goal and the effort is shared throughout
the community. Such adaptations
of not-yet-accessible resources or resource components,
post-production, offer great hope in the field of accessibility
research.
Going a little further, the FLUID project
is developing interchangeable user interface components
that can interpret and present content in ways
that are accessible to individual users
(2007). This depends
on content being made so it is not application or interface
specific,
but free to be adopted and adapted by any standards conformant
applications, interfaces, and thus accessible to all who use
it.
An outdated view of accessibility and
of the Web
The original use of the World Wide Web was to enable a few
people scattered around the world to work together on shared
files located on their own computers. It made the files discoverable
using a Uniform/Universal Resource Identifier [URI] so they could be accessed using the HyperText Transfer Protocol [HTTP].
The goal was collaboration among a few scientists. In the first decade of widespread
use of the Web as an information and communication technology,
the main activity was the publication of
resources. This involved the use of HTML
encoded files that offered embedded links, embedded multimedia
resources and may have had cascading stylesheets [HTML
4.01]. The publishers relied on third party HTTP
or Web servers to deliver the files to users who browsed
the publications. Now, as is recognised by the new name 'Web
2.0' (see below), all sorts of interactive, collaborative
and shared activities are being undertaken using a wide range
of technologies. Already we are seeing extensive publications
that are user-driven, and the publishers are often responsible
for creating an environment in which the users contribute content to be published (e.g. the image publishing site Flickr).
The research establishes that the dominant model of
accessibility work is still grounded in the
early populous Web, a network of static documents that may
be updated but are usually from a single source. In this thesis,
the term Web 1.0 is used to designate this Web as it was
in its first decade, 1995-2005. O'Reilly (2005)
used version terminology to differentiate between the uses
of the Web and to draw attention to more recent developments
in the way people use the Web. Of course, it should be noted
that the Web does not, in fact, have versions (O'Reilly,
2005)
and this terminology is more about how it is used than what
it can do.
Web 1.0 work assumes editorial control over publishing,
even where the authors come from a single organisation and
this task is undertaken by a number of people. In such cases,
in fact, many organisations impose both style guides (or the
equivalent) on the authors and/or provide templates within
which those authors have constrained scope for their content.
In such circumstances, it might be possible to force adherence
to certain style standards, as it was in the earlier days
when documents to be printed were encoded in Standard Generalized
Markup Language [SGML]
(the predecessor of HTML). The model also assumes that users
of Web resources will interact with them as their author intended.
More and more this is proving not to be the case as
people use search engines, dynamic feeds from within Web sites,
etc.
Many people still do not
recognise that they can use standard Web pages and Web authoring
tools in almost exactly the same way as they use non-standard
proprietary office tools. Web authoring tools have many of the same features as word processors, including facilities to format, print, exchange
and manage other documents. Many people are still using proprietary-format office
tools that do not offer the accessibility that
is now possible.
Organisations in which proprietary
office tools are used form sub-cultures around those tools,
and participants develop materials (resources) that
suit the particular local software tools. They are often
not aware that their single resources could be as easily created
and managed but far more flexible and interoperable not only
between software systems, but also across ranges of modalities
(on paper, on individual screens, as presentations on large
screens, read aloud, etc.). Proprietary interests and competition
have encouraged proprietary developers to distinguish their
software by adding features often regardless of the inaccessibility
simultaneously introduced by those features.
At the time of
writing, there is a worldwide concern about the adoption of
the Microsoft specification Office Open XML as
an international
standard for documents. One reason for the concern is the problem of accessibility
that may flow from such a decision (Krempl,
2008).
Portable Document Format [PDF],
another proprietary format, has long proved a problem for
accessibility and continues to do so despite being an ISO
standard (W3C
PDF, 2001) and despite the possibility of using it to produce accessible content.
The research establishes that the historic view of accessibility
is no longer effective.
The complexity of satisfying the original
guidelines is shown to be out of the range of most developers.
There are too many techniques involved; they are not explicit;
they cannot always be tested with certainty; they do not completely
cover even chosen use cases and are not intended to cover
all user requirements; they are contradictory in some cases;
they have not been applied systematically, and
anyway, they do not apply to all potential information and
communications. All of these claims are documented in this
thesis.
In addition, it is not appropriate to be concerned only with
how to give access to Web 1.0 type activities. All users need
to have access to all the facilities of the evolving Web,
including contributing to its evolution.
A new approach to accessibility for
Web 3.0
This thesis
does not claim to be alone in making the claims above: there are many researchers working on similar problems, as shown in the thesis. Their work is considered
in detail in the research.
What
this thesis offers is an argument in favour of an
on-going process approach to accessibility of resources
that supports continuous improvement of any given
resource, not necessarily by the author of the resource,
and not necessarily by design or with knowledge of the original
resource, and often by contributors who may be distributed globally.
In taking this stand, the research anticipates the evolving
Web. It argues that the current dependence on production guidelines
and post-production evaluation of resources as either universally accessible
or otherwise, does not adequately provide for either the accessibility
necessary for individuals or the continuous, evolutionary
approach already possible within what is defined as a Web
2.0 environment. The research assumes a distributed,
social-networking view of the Web as interactive, combined
with a social model of disability, for the management tool
using machine-readable, interoperable AccessForAll metadata.
It goes further and anticipates the ability of data itself
to form relationships and logical connections within the Web.
It argues this can support continuous improvement of the accessibility
of the Web with less dependence on the part of original content
developers and better results for individual users.
As outlined above, there are a number of ways to make resources
accessible. Relying solely on authors to 'do the right thing'
by following the universal accessibility approach has generally
failed to make resources universally accessible (Chapter
4)
but many resources are nevertheless suitable for individual
users, if only they can find them. Similarly, most resources
that are universally accessible are not discoverable as such.
In Europe, there have been moves to apply metadata (labels) to resources,
to catalogue them,
and declare their accessibility in terms of conformance with
various available specifications: the UK government has mandated
certain provisions (BSI,2006; Sloan,
2005; Appendix 6) and
the European Centre for Standards (CEN) supported a project (later
abandoned) led by EuroAccessibility
for an accessibility conformance mark for use in all European
countries (RNIB,
2003).
There have also been reservations expressed about the proposed 'conformity
labeling' approach (Phipps
et al, 2005). The current research also challenges the
wisdom of that practice. As there are often legal implications
for having resources that are not accessible, even if
there is not an economic incentive that might bias evaluations,
it is hard to know which evaluations to trust. It is also
very hard to evaluate accessibility accurately. One reason
for the problem with the evaluation of accessibility is that
only some of the criteria can be tested against absolute standards,
as most depend upon human judgment. This causes problems because
many people can manage to do the technical tests using automatic
evaluators. They do not realise they also have to do the human-based
user testing, and when they do, they lack the knowledge, resources
and expertise to do this properly. In fact, to rectify this
situation, those developing specifications, such as the World
Wide Web Consortium's Web Accessibility Initiative, are endeavouring
to make all specifications testable against absolute values.
Unfortunately, to achieve this, they appear to be compromising
some of the specifications (Hudson & Weakley,
2007)
and end up having to ignore the needs of important communities
of users such as those with cognitive disabilities (Moss,
2006; [WCAG-2]).
Metadata (labels) that merely identify resources that have been
marked as accessible are not particularly reliable
and anyway, as is shown in Chapter
4, conformance
with the best-known guidelines does not necessarily mean a
resource is accessible to the individual who wants it.
Certainly, such metadata does not say if the resource
is optimised for any particular individual user seeking it.
More specific metadata is required if it is to be useful to
the individual user. This has been recognised by the authors
of the WCAG guidelines and there is provision
in the revised version of WCAG [WCAG-2] for metadata as a result
of the AccessForAll work .
If resources are to be made more accessible post-production,
their inadequacies will need to be discoverable prior to
delivery. When found to be inaccessible, any missing
or supplementary components, or services to adapt them,
will also need to be discoverable. Resource descriptions,
like catalogue records, can usefully contain descriptions
of the accessibility characteristics of resources without
any need for declaring if the resource is or is not conformant
to a comprehensive standard. Such characteristics' descriptions
are known as AccessForAll metadata and discussed in detail
in Chapter
7.
AccessForAll metadata has been adopted by four major standards
bodies. First, the IMS Global Learning Consortium [IMS
GLC] for the education sector. Then
the Joint Technical Committee of the International Organisation
for Standardization/International
Electrotechnical Commission. Its,
Sub-Committee 36 [ISO/IEC
JTC1 SC36], endorsed and adopted it again
for the education sector. The Dublin Core Metadata
Initiative [DCMI] is
adopting it for general metadata, for all sectors, and Standards Australia has adopted if for the AGLS
Metadata Standard [AGLS],
for all Australian resources.
In addition to metadata that describes the accessibility
characteristics of resources, it is necessary to define metadata
to describe the functional needs and preferences
of users.
'AccessForAll' metadata is best used to match resources
to users' needs and preferences, automatically where possible.
Determining how such a match might be achieved in a distributed
environment is a continuing interest of the author and especially colleagues
at the Research Center for Knowledge Communities [KCRC] in Japan, in as much as it relates to the use of
the Functional Requirements for Bibliographic Records [FRBR],
OpenURI (Hammond
& Van de Sompel, 2003), and possibly GLIMIRs (Weibel,
2008a).
This highlights the significance of the metadata as defined,
the potential matches, and the ways in which AccessForAll
metadata contributes to the accessibility process.
'Usability' is well established as a criterion for the utility
of a resource (Nielsen, 2008).
A flexible approach including usability in a loose sort of
'tangram' model could significantly improve the Web's accessibility
(Kelly
et al, 2006, Kelly
et al, 2008).
The AccessForAll metadata enables the management of resources
in such a process with adaptability for personal needs
and preferences for a better result.
This thesis describes the background, theories, design and
development of the
metadata framework, as implemented and documented in the various
published or forthcoming standards, and work associated with
its adoption by various stakeholders. In doing so, it exposes the problems of designing metadata frameworks for interoperability and finally focuses on the need for a tightly specified framework for such metadata if it is to achieve the goals set for it by the context. The thesis thus starts with the focus on accessibility and later moves it to metadata. The proposed role for the metadata is the managment of data relating to accessibility, so both are significant in the research.
Understanding and significance of accessibility
Understanding accessibility is not easy given the huge number
of different contexts and requirements possible. In addition,
there are many definitions.
For the purposes of the research, accessibility is defined
as a successful matching of information
and communications to an individual user's needs and preferences
to enable that user to interact with and perceive the intellectual
content of the information or communications. This includes
being able to use whatever assistive technologies or devices
are reasonably involved in the situation and that conform
to suitably chosen standards. Explanations of the more detailed
characteristics of accessibility are considered in Chapter
3.
Throughout this thesis there is reference to literature
that reveals two things: a current common approach to
accessibility that is significantly reliant on universal
accessibility, as promoted
by the World Wide Web Consortium [W3C],
and a
significant failure of that approach to make a sufficient
difference despite the need for accessibility.
Almost one in five Australians has a disability, and the proportion
is growing. The full and independent participation by people
with disabilities in web-based communication and information
delivery makes good business and marketing sense, as well as
being consistent with our society's obligations to remove discrimination
and promote human rights. (HREOC,
2002)
In 2008, despite the introduction of quite stringent
provisions regarding the accessibility of government sites,
SiteMorse (2008)
report that only 11.3% of UK government
websites surveyed passed the WCAG AA test mandated
for such sites (Cabinet
Office, 2008). (The sites were tested only with automated
tests, so the results are only indicative of 'universal accessibility'.)
Those with needs in terms of access in Europe are estimated
to include 10-15% of the population who have permanent
disabilities and the number is increasing as the population
ages (European
Commission, 2007).
Microsoft Corporation commissioned research that suggests
the benefits of accessibility will be enjoyed by 64% of all
Web users (Forrester
Inc., 2004).
In 2004, the United Kingdom's Disability Rights Commission
[DRC]
reported on the accessibility of 1,000 UK Web sites (DRC,
2004). They showed
that 81% of Web sites failed to meet even minimum standards
for Web access for people with disabilities. Later,
at a press conference, the DRC claimed that even sites considered
prima facie to be demonstrating good practice, in fact
failed to satisfy minimum standards when
fully tested by the DRC. These reports have been
endorsed more recently by the United Nations' Global Audit
of Web Accessibility (Nomensa,
2006).
Brian Kelly (2008) commented:
What we can’t say is that the Web sites which fail the automated
tests are necessarily inaccessible to people with disabilities.
And we also can’t say that the Web sites which pass the automated
tests are necessarily accessible to people with disabilities.
AccessForAll philosophy
The more information is mapped and rendered
discoverable, not only by subject but also by accessibility criteria,
the more easily and frequently inaccessible information for
the individual user can be replaced or augmented by information
that is accessible to them. This, in turn, means less damage
when an individual author or publisher of information
fails to make their information accessible. This is important
because, as is shown ( Chapters
2, 5),
making resources universally accessible is burdensome,
unlikely to happen, and does not guarantee that the information
presented will,
in fact, be accessible to a particular individual user. It also
means that distributed resources need to be managed so they
can be augmented or reformed by components that are not originally
a part of them or not intended to be associated with them.
This can be facilitated by suitable metadata.
Widespread-mapping of information depends upon the interoperability
of individual mappings or, in another dimension, the potential
for discovering distributed information maps in a single search. The ancient technique of creating atlases from a collection
of maps is exemplary in this sense (Ashdowne
et al, 2000). Being
able to relate a location on one map to the same location on
another map is achieved easily when latitude and longitude
are represented in a common way, or when the name of one location
is either represented in a common way, such as both in a certain
language, or able to be related via a thesaurus or the equivalent.
Atlases would not be useful if every map
were developed according to different forms of
representation; the standardisation of representations enables
the accumulation of maps to form the global atlas.
In the same way, the widespread mapping of accessible resources
on the Web is achieved by the use of a common form of representation
so that searches can be performed across collections of resources.
Interoperability is typically said to function at three levels:
structure, syntax and semantics (Weibel,
1997). Nevile
& Mason (2005) argue that it does not operate at all unless
there is also system-wide adoption
(see Chapter 11). System-wide
adoption might now be thought of as substantial adoption.
The original AccessForAll team (the AfA team) at the University
of Toronto worked to exploit the use of database classifications
in the discovery and publication of their digital content in
a way that could increase accessibility for their university
users [TILE]. They exploited a common way of describing the resources
and resource components so they could mix and match them to
user’s individual needs and preferences. When this activity
widened in scope, as IMS GLC work [IMS Accessibility], there was a need to think
about how the necessary descriptions could be shared across
institutions. The aim was to develop specifications for the
description of resources so these could be shared. The
hope was to specify a common vocabulary for describing the resources. It
would specify a ‘machine-readable’ form for those descriptions,
defining a set of terms that could be used and how they might
be used by a computer.
Further work led to yet another set of specifications, now an international standard developed by many national bodies and experts [ISO/IEC 24751-1:2008; ISO/IEC 24751-1:2008; ISO/IEC 24751-1:2008]. The aim has not changed. It is that individual users everywhere can find
something that will serve their purposes in a way that is independent
of their choice of device, location, language and representational
form.
The research highlights the need for interoperability of metadata specified in those standards. Unfortunately, it shows that so far this has not been attained as it might be. On the other hand, developments within the relevant standards organisations have also recognised the problems of interoperability, and on-going work to which the author is contributing is engaging with the problems. Specifications for metadata for learning resources have been under development for some time but by late 2008 it has become clear that a number of national bodies and experts are very concerned that metadata is developed only in conformance with a deeply interoperable model, and this seems to mean within a Semantic Web Resource Description Framework (W3C RDF, 2008).
The AfA work takes advantage of the growing number of situations
for which metadata is the management tool for digital objects
and services and information about people's needs and preferences with respect
to them, so that well-described resources that are suitable
can be discovered. AfA philosophy includes, in addition, that
resources should be able to be decomposed and re-formed using
metadata to make them accessible to users with a range of devices,
locations, languages and representation needs and preferences. Chapter
11 expands on some significant if not yet widespread adoption
of this idea. AfA metadata can be used immediately to manage
resources within a shared, closed environment such as the original
one established at the University of Toronto where the AccessForAll
approach was conceived.
This thesis argues that there is greater potential for benefit
from accessibility metadata if it is not only expressed in
a common language but within a common description framework. That is, rather
than just sharing particular ways of describing particular
characteristics of resources, it should be possible to describe
those characteristics in a common way, so that all the descriptive
sets are interoperable. This is considered the essence of good
metadata and now also being advocated by some as the appropriate base for all ISO/IEC JTC1 SC36 metadata work (ISO/IEC CD 19788-1).
A metadata approach
In the case of the AccessForAll projects, and others, Nevile
is a metadata scientist. Her research is about how
a metadata framework should be designed so that metadata developers
can share their metadata and rely on its interoperability at
a machine level. The research is grounded in work operating at a different
level, involving the definition of metadata schemata (herein called schemas).
Using a common term such a ‘dog’ is not problematic when talking
to a child and differentiating between a horse and a dog (or
wolf). It is a serious problem if it is used indiscriminately
when it comes to the classification of species.
As explained in Chapter 6, the value of metadata usually
is in its interoperability, and this depends, like the definition
of ‘dog’, on broad and deep interoperability with other classifications.
Local utility does not make such demands, and much has been
achieved in the past with what is now often called metadata,
the classifications within databases of content (what are known
as fields in database terminology). In the Web 1.0, database-driven
customization of Web content is very useful, especially
where there are fast applications, connections, and even shared
(common) fields so queries can be distributed. The vast library
‘union’ catalogues work this way.
A characteristic of Web 2.0 is that so-called users contribute
to the Web. They do not just consume content but do such things
as contribute content and comment on content, theirs and others,
for example by adding tags to describe it. In many cases, the
users of Web 2.0 are filling in the missing gaps in databases
designed by the content publishers, who now publish but do
not always author content.
Web 3.0 is expected to be upon us very soon. There is speculation
about what it will be but concensus is firming up around what
is known currently as the 'Semantic Web'. Kevin Kelly (2007)
envisions yet later versions of the Web as an environment in which people and objects
have become part of the Web, it has become 'one', with data playing an 'intelligent'
role.
Increasingly, what we might call
Web 3.0 activities are emerging that involve structuring of
content in ways not anticipated by the original authors or
publishers. For example, imagine a site that publishes photos
submitted by users. Imagine a second site that refers to content
on the first site and provides text descriptions of the photographs.
In this case, the second site provides some original content
(perhaps contributed by the general public) and ways of structuring
distributed content without any need for agreement about the
form of the content with the original authors. The second site
developers do not republish the photographs. They might be
using metadata about the original content, however. If the
second site developers want to provide a service for users,
and offer text descriptions of photographs from wherever, they
will want to be able to use metadata from wherever. They will
use the metadata to determine things like the date of the photograph,
the photographer, the camera used and other things that they
will want to be able to use in their management, or include
in their description, of the photograph.
Imagine a site where students who cannot access some multimedia
learning materials provided by their institution about Hamlet
can find other resources that deal with the same topic but
in text. They will want computers to be able to know what
work they are learning about, in this case Hamlet, and to find
other materials about the same work. In addition, they will
want to know in what format the alternative materials are available.
There will be a need for access to information, descriptions
of the resources, if users or their agents are to match the
alternatives to the originals and also, to be made aware of
the existence of the alternatives when they discover the originals.
This is so even if the creator of the originals does not know
the alternatives exist, and especially if they do not point
to them.
The interoperability of metadata depends on more than the
language used, as explained in Chapters 6 and 11.
Metadata research is necessary to determine how metadata
should be specified. It is not about the metadata itself –
that is implementation, and the work of metadata engineers.
The AccessForAll work started at the level of metadata implementation [TILE].
Through work on that implementation, development as it is often
called, research questions have emerged that have led to a
scientific view of metadata.
Metadata research is looking for a means
of fixing semantics within a framework of vocabularies that
are not aligned, using technology that is evolving, and looking
for appropriate means for declaring the semantics in interoperable
ways. Such research is being performed in a number of leading
universities (Metadata
Research Center, University of North Carolina (MRC UNC);
Metadata
Research Project, University of California (Berkeley); Cornell
University Library; etc.).
At the Metadata Research Center,
School of Information and Library Science,
University of North Carolina at Chapel Hill, a number of
projects for developing metadata for specific domains have
been funded and undertaken as research [MRC
UNC]. A typical example is provided by the KEE-MP project:
The goal of the Knowledge Exploration Environment for Motion
Pictures (KEE-MP) project is to design and develop a prototype
web system that will enable aggregation, integration, and exploration
of diverse forms of discourse for film.
The main research components of the project are:
- Identification and categorization of descriptive information
produced by the film discourse community.
- Development of processes and principles for working
with high-level content descriptions (e.g., of form, genre,
theme, style) in metadata frameworks and thesauri (or ontologies).
- Prototyping of a system for user testing and experimentation.
(MRC UNC, 2008)
Such research does not depend upon standard research techniques
(see Chapter 2), but nor
is it development in the usual sense. While the direct output
may be a prototype product, the research is
about metadata, a branch of information science. Some of what is learned is inevitably
what is not supported by metadata as it is used, and how effective
the evolving principles are, and what could improve them. The KEE-MP project involved expertise about films. The current research
is based on the effectiveness of the evolving principles
of technical accessibility development and ways to improve
them.
AccessForAll metadata research and development
In the current research, the basic computer science task of
classification in first normal form (IBM, 2005),
in a functionally unambiguous way as used in databases, is
abstracted into the field of metadata.
At one level, the focus is on how to classify the objects
of concern. At the next level, it is how to define and structure
those classifications, the semantics of those classifications,
what terms are to be used. Neither of these levels guarantee
interoperability, or even depend on it. They are concerned
with establishing what can be thought of as a vocabulary for
describing the objects. Such a vocabulary can be shared, making
it a common vocabulary.
Metadata research is concerned with how to make it an interoperable vocabulary,
and that depends on its syntax and structure being shared.
Implementers and developers work to unambiguously classify
objects building databases and thesauri. The science of metadata,
how to express and make interoperable such classifications,
evolved from the librarian's discipline of cataloguing, inheriting
many principles but explicitly rejecting others or adapting
them, and adding some new ones. The role of technology, and
hence the syntax and structure of the classifications, is significant
in metadata work alongside the semantics that are always in
focus in library work. Metadata research is an evolving field,
given the changing nature of the technology and its use, especially
the technology and use of the Web.
The current research also concerns the effectiveness of the
evolving principles of technical accessibility development
and ways to improve it. It was undertaken within a context of collaborative work on accessibility for a number of organisations involving a number of players over an extended period (Figure 2).
Metadata research projects often involve
a multi-disciplinary team including both developers and researchers.
In as much as the research requires the use of new technologies,
and they need to be built and tested, developers are often
essential to the work. It is also important to have people
to design the system, understanding the requirements for any
metadata to be used. There is finally, of course, a need for
subject experts, who contribute information about the structure
of the knowledge of the domain, and how it is used.
The Assistive Technology Resource Center [ATRC] at the University
of Toronto has a proud record of research and development.
In the field of accessibility, they have significant achievements
and, specifically, were leaders in the use of database technologies
to adapt resources to users’ individual needs, with their product
‘The Inclusive Learning Exchange’ [TILE].
TILE is a database application in which particular inputs
prompt certain responses from a computational system.
In the AccessForAll interdisciplinary development team, there
have been seven major players: Jutta Treviranus, Anastasia
Cheetham and David Weinberg, in particular, from the Assistive
Technology Resource Center [ATRC] at the University of Toronto,
Canada (University of Toronto,
Canada); ; Madeleine Rothberg from WGBH National Center for
Accessible Media in Boston, USA (WGBH/NCAM);
Liddy Nevile from La Trobe University, Australia; and Andy Heath
from the University of Sheffield (now at the Open University)
and Martyn Cooper from the Open University, United Kingdom (Open
University, UK).
All in the team have been involved in accessibility work for
a number of years but from different perspectives. Nevile is
the metadata scientist/researcher in the team, Cheetham
and Weinberg are responsible for the development of the prototype
TILE, Heath is an expert in programming, and Rothberg, Treviranus
and Cooper are responsible for major accessibility projects
in education. Treviranus is the outstanding accessibility expert.
Treviranus is the Director of the ATRC and Chair of the
W3C Authoring Tools Accessibility Guidelines Working Group
[ATAG
WG], among other things.
The AccessForAll work has been undertaken in a number of contexts
(as explained below) but always with the core team leading the
efforts. The group emerged from the work being undertaken by
the IMS Global Learning Consortium [IMS
GLC] when they adopted the ATRC model, and has moved to
other contexts, as explained below. Nevile, the Chair of the
DCMI Accessibility Working Group (now the Accessibility Community),
is responsible for AccessForAll finding its way into the DCMI
world of metadata and has been responsible for developing the
Accessibility Application Profile (or Module) for DCMI and all
the schema and documentation required for an international technical
standard (DCMI
Access).
The local aim of the metadata research is to find a way to
enable the AccessForAll approach in a variety of formats with
the greatest possible potential for interoperability between
those formats. As always, those leading in AccessForAll work
are involved in many overlapping and, at times, conflicting
communities (Figure 3, 4). Consequently, this work has been
undertaken in a socio-technical more than a scientific environment.
This thesis argues that metadata is an enabling technology
for a shift to an AccessForAll approach to accessibility. It
is at the core of the research as is accessibility itself.
From the beginning, Nevile's involvement has been based on
questions that have arisen in the Dublin Core Metadata
Initiative context, motivated by earlier work in both the metadata
and accessibility fields, and focused on the potential role for
metadata in increasing accessibility. The need to distinguish
between compliance and functional metadata is a good example.
It was the subject of discussions at an open meeting in Seattle
in 2003 (Nevile,
2003d).
There is yet another dimension to the research that should be
noted. This is the design dimension.
Discovery of resources always involves some sort of matching,
even for avoidance purposes. The design of the metadata to
be matched depends, usually, on the requirements in the circumstances.
In the case of the original prototype for TILE, for example,
the requirements would have been ascertained and then the metadata
would have been designed to provide the necessary information.
In order to match a resource to a person who cannot use sight,
it is necessary to determine if a resource requires sight as
a perceptive mode. If so, it might need to be avoided. It will
be necessary to have a way of determining if the resource does
need to be seen and recording this information so the resource
sorting process can be applied when it is called upon.
TILE was built to provide users with the best match of digital
resources from a given set of resources, all authored and available
in-house. The AccessForAll approach to accessibility, generalizing
this idea from TILE, aims to operate in a global context.
As soon as the first set of terms were developed, members of
the team felt pressure to work on other types of objects, including
in the mix objects such as people who might be personal assistants
to users with disabilities. Where there is a human assistant,
the functional requirements of the user may not change but
there is a new set of skills to be configured into the matching
process. Similarly, when some of the resources are non-digital,
their characteristics will not be described well by using a
profile for digital resources. For example, digital text is
very different from printed text.
Another way of thinking of the difference between the work
of the original TILE developers and the metadata research is
to think of what is produced by the two groups. As a result
of the work of the TILE developers, resources within the TILE
system could be delivered to users in a chosen way. As a result
of the work of the metadata research, it should be easier to
write metadata to support AccessForAll accessibility in new
circumstances. The metadata framework, alone, does not do anything.
The product of the research is a comprehensive explanation
of how to do something, and why it works or otherwise, not
the doing of it.
As stated above, the metadata researcher’s task is not to
implement or even design a set of terms for use in the circumstances,
but rather to design a framework in which such sets can be
designed by others, with confidence that they will all be interoperable.
In Chapter 10, it is explained
how metadata is mixed and matched, in other words, how it interoperates
in useful ways. Here, suffice to say that this dimension of
the research that is about enabling the design of metadata,
what might be called the meta-design of metadata (Fischer &
Giaccardi, 2006), is central to the research.
In addition, the research is transdisciplinary, and so requires
appropriate competencies. As Derry & Fischer (2007) point
out,
Transdisciplinary competencies refer to knowledge and skills
required to identify, frame and address important scientific
and practical problems that cut across disciplinary boundaries.
Such problems are complex and ill-defined (Simon, 1996) requiring
(a) integration of problem framing and problem solving, (b)
communication and collaboration among people from different
disciplines and educational levels, and (c) intelligent use
of technologies and resources that support collective knowledge
construction and extend human problem-solving capability.
Derry and Fischer (2007) point
to the problem of who owns work developed in a socio-technical
environment. They report that this type of work is a priority
in post-graduate research because it is in the ‘real’ world.
But they also assert that, so far, there is no clear research
about how to evaluate this type of work. It may have been considered
a problem, for this thesis, to make explicit what is the contribution
of the research it reports. Rather than shy away from the collaborative
nature of the work undertaken as part of the whole AccessForAll
endeavour, however, this thesis aims to celebrate that collaboration.
It asserts it is a strength of the work that it is based on
actual practice in a transdisciplinary, socio-technical context.
Research objectives
The focus of the research is how metadata can provide the
infrastructure for AccessForAll practices to make the Web more
accessible.
With respect
to metadata, the research challenges the structure, the
syntax and the semantics of the AccessForAll work. It includes:
- analysis of the problems of interoperability between two
different types of metadata (Learning
Object Model and Dublin Core);
- the creation of a suitable alternative structure for AccessForAll
metadata, based on the Dublin Core Abstract Model (DCAM),
that is interoperable with other Dublin Core (DC) metadata
and thus also the Semantic Web (an significant emergent technology
in the Web environment);
- alternative semantics for AccessForAll metadata that are
compatible (without loss) with the original LOM-based model
but conformant with the DC structure as defined in the DCAM,
and
- a syntactic representation that is interoperable
with LOM, DC and Semantic Web expressions of AccessForAll
metadata.
It considers the following questions among others:
- What constitutes accessibility? in what context? for whom?
- How effective are current accessibility strategies?
- What is wrong with current strategies?
- What is necessary to enable better access?
- What other strategies could be used?
- What are the major components of best accessibility practices?
- How are such practices enabled?
The
AccessForAll standards, and other products of the research,
are published elsewhere and, increasingly, implemented and
further researched.
With respect to accessibility, based on estimates
of the current accessibility of the Web, the research challenges
the theoretical foundations of previous work. It adopts a
new base to support inclusion and the UN Convention for the
Rights of People with Disabilities (UN,
2006). It includes:
- a review and interpretation of available statistics
to determine the need for improved accessibility of the Web;
- a review and interpretation of available standards and
specifications currently in use;
- evaluation and interpretation of reports of the effectiveness
of current accessibility efforts;
- articulation of a new theoretical model for metadata use
to increase the accessibility of the Web;
- face-to-face workshops in Europe, Asia and Australia to
seek consensus for proposals, and
- AccessForAll metadata standards development.
Research method
The first phase of the research involved coming to terms with the requirements of the Web Content Accessibility Guidelines [WCAG-1]. The author had worked with the Authoring Tools Accessibiity Guidelines [ATAG] editors in the hope that by specifying how authoring tools should work, the guidelines would lead to the use of tools that enabled authors to make increasingly accessible resources without having to think about accessibility. The reality was that the major tools developers did not adopt the specifications. The author tried to build a site that would provide a functional approach to accessibility for authors who were trying to achieve it. This site took a different approach from the WCAG but with the aim of implementing it. The goal was to have a quick-lookup menu so that a resource author could look directly for what they needed - how to make symbolic mathematics accessible, for example. The author hoped that the site would become an interactive site, to which others would contribute.
Appendix ??? contains the site as developed. It did not achieve its ultimate goal but was used for several years by La Trobe University as their guidelines for accessibility and significant parts were adopted in the "IMS
Guidelines for Developing Accessible Learning Applications" (Barstow & Rothberg, 2002).
The next phase involved the development of metadata for the Dublin Core Metadata Initiative through its Accessibility Working Group. This work showed that existing DC terms were inadequate for accessibility descriptions and pointed to the need for some special metadata but did not make significant progress until the early AccessForAll ideas were introduced. Meanwhile, the author was working with the INCITS V2 team to understand what metadata would be required for the alternative interface access protocol for the universal remote console (Sheppard et al, 2004).
In 2003 the author brought together the major players from the various accessibility working groups with the aim of making a collaborative effort for the development of accessibiity metadata. Judy Brewer from W3C, Jutta Treviranus from the University of Toronto, and others met and discussed how metadata might be involved in the effort to make the Web more accessible (DC Accessibility Meeting, 2003).
The author was working with the IMS AccessForAll team specifying how the accessibility characteristics of resources and the accessibility needs and preferencs of users, might be described so they could be matched. This work depended enormously on the substantial 'accessibility' input from the University of Toronto experts but the author was conviced its success would also depend upon good metadata principles. There wer many vigorous and some heated discussions about this in weekly teleconference meetings and a number of multiple-day face-to-face working sessions. The author was struggling to articulate the principles, as it happens concurrently with the DCMI's own struggles, and often thought to be infuriatingly pedantic about these principles. The problem was that TILE was an operational system and so, some thought, proof of what was required, while the author was convinced that effectiveness and longevity of the work was dependent on metadata principles.
It was of enormous good fortune that those involved in the work were, in fact, passionate about their work and the result of many hours of debate usually satisfied all concerned and moved the work closer to what the author considered better metadata. It is most likely that this would not have happened had there not been such a competent team and so much engagement with the issues. It is probably not insignificant that most of those involved were used to development within an academic research environment.
The research was not bounded by the AccessForAll context. That work was taking place in the educational metadata milieu while the author was concerned to publish it within the wider DC general metadata world. This meant the author had to work on the DCMI approach to metadata and their principles. As said above, these were still in development, and so there was a need for engagement with that work. At one point the author contributed to the debate about the expression of the DCMI's metadata model, which led to its further refinement (Pulis & Nevile, 2006).
Finally, the ISO JTC1 SC 36 that is concerned with standards for Learning, Education and Training, at the time of writing is developing a standard for metadata. The major standard for educational metadata, Learning Object Metadata [LOM] was developed many years ago, and proved cumbersome and has not been implemented easily. When developing metadata in 2000 for the Victorian Government's Education Channel, the author chose to use modified DC metadata instead of the LOM. This led to new terms for DC metadata and the first DC application profile. The DCMI formed an education community and they are active in developing metadata for education that complies with the Dublin Core Abstract Model [DCMI DCAM]. In 2001, the author initiated a meeting between the DCMI and the LOM communities. This led to what is known as the 'Ottawa Communique', an agreement that these communities would work together to achieve greater interoperability between the two sets of metadata. A joint paper was published in 2002 that explained the similarities and problems (Weibel, 2002). All of this is relevant because the ISO work on a new Metadata for Learning Resources standard is required to match the DCAM and be as compatible as possible with the LOM in doing so (ISO/IEC JTC1 SC36 resolutions, 2007). Not only does this work provide a further challenge for the author and the research but it is also able to draw upon some of the research (particularly the work in Chapter 11).
Chapter Summary
In this Preamble, the scene has been set for the substantive
work that follows. The development of a new way of working
on the problem of accessibility has been introduced as not
just a response to the lack of real success with previous methods,
but also a response to the changing technological context
in which this work takes place. Metadata research has emerged
as a substantial field in the last ten years and metadata development
has led to its adoption for resource management within
digital systems. In addition, earlier understanding of disability
according to a deficit model has been replaced by a social
inclusion model that avoids distinctions between people with
physical or other medical disabilities and the general public,
assuming that everyone, at times, is disabled either by their
circumstances or by temporary or permanent human impairment.
In the next chapter, many of the components considered in
the research are defined in greater detail and the research
is further described.
Next -->
 This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile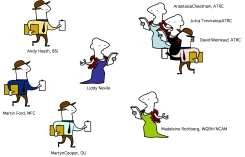

{kind=link}