Chapter
7: Accessibility Metadata
Introduction
Given the Dublin Core as a huge base for international, cross-domain
metadata, it seemed obvious when the research started
with accessibility and metadata
that the two should be combined. Given the number of Web services that adapt
resources for users, it was assumed that they would be described by some sort of metadata that could be transformed for use as AccessForAll metadata. The first section of this chapter, therefore, reports on some available alternative resources and the liklihood that they could yield the necessary metadata. The next exercise
was to find out if there are Web services that adapt or
transform content, if there is a way to choose to have this
done. Some typical services were considered. Finally, there is some discussion of why the
Dublin Core metadata communities, who are responsible for much
of the interoperable metadata in the Web world, have an interest
in accessibility metadata, and that interest itself.
The aim of this chapter is to provide the final pieces to complete the context in which the development of AccessForAll accessibility metadata is explained.
Existing accessibility metadata
There is always, in the mind of metadata experts, experience
that shows that metadata is expensive to produce and that it
is very often inaccurate. For this reason, it is important
when proposing a new use or context for metadata, to be sure
that it is necessary, not overly-complicated; that it will, in fact, be created and used. This section locates the current
research in a world that is already partially prepared for
it. Showing that there is a substantial amount of discoverable
material in a range of formats suitable for people with varied
needs and preferences is important if there is to be more work
in finding a way to describe the necessary needs and preferences
and the resources that might satisfy them. Thus, the quantity
of discoverable material is indicated within this section.
In addition, unless the new descriptions can be used alongside
those already in use, that is, unless there are existing descriptions
that are interoperable with the new ones, there is not much
point in undertaking the research. What follows shows that
there is sufficient material and it provides
a base with which the new metadata should be interoperable.
Sources of accessible resources and their descriptions
The Royal National Institute for the Blind (RNIB)
In the United Kingdom, the Royal National Institute for the Blind (RNIB)
has developed and maintained the National Union Catalogue of
Alternative Formats.
Ann Chapman
(2000),
says that 5% of the 100,000 new British titles published
each year are converted into alternative formats. She points
out that these formats are created by a range of individuals
and organisations and made available in a number of different
ways and places. Her interest is in an interoperable library catalogue of such alternative formats. In 1989, the Royal National Institute for the Blind (UK) R.N.I.B. began the process of
computerising its card catalogues, thereby creating the National
Union Catalogue of Alternative Formats.
As part of the Department for Culture, Media and Sport funded
programme to improve library and information services to
visually impaired people, the role of NUCAF was reviewed
in 1999 (Chapman, 1999). The review concluded that a national
database of resources in alternative formats was an essential
tool in service provision and that while NUCAF in its present
form had limitations, particularly in respect of access,
it did provide a good basis for a more comprehensive database
of resources." ...
It further recommended that the new database should primarily
cover the output and holdings of the specialist non-commercial
sector, and that collaborative agreements with existing databases
and union catalogues should be developed to cover the commercial
sector publications." The review pointed out that, "In
addition to libraries, a range of agencies (doctors, dentists
and health professionals, banks, advice centres, electricity,
gas and water companies, tourist offices, schools and academic
institutions, government departments, and service providers
of various kinds) would either use the database or refer
people to it. Currently visually impaired people and those
working to support them are restricted to a few narrow avenues
of access to NUCAF. The new database will be designed to
be far more widely accessible to end users and library staff.
To achieve this it was recommended that the national database
should be held on a web-based system, supported by CD Rom
and electronic file versions. (Chapman, 1999)
Eventually, as a result of various funding opportunities and
projects carried out in a number of places, NUCAF was merged
into a new service called REVEAL. In "Project One part
A: The future role of NUCAF and a technical specification of
the metadata requirements", Chapman (1999)
reported "The national database should where possible
use national and international standards. It should use the
UKMARC format and conform to AACR2. Current RNIB subject indexing
should be used for subject indexing, and LCSH entries retained
where they exist in the records for the original items. A single
set of headings for fiction genre/form should replace the existing
ones. A full set of the data elements required has been identified."
These were found to be:
- Basic Bibliographical details (Title, author(s), publisher,
date of publication, edition, series, and subject.)
Search Support (Subject indexing, fiction genre and form
indexing, target audience, format type.)
Decision Support (Annotation or content summary, target audience,
series and character information, serial frequency, abridgement
notes, narrator or cast notes for audio materials, format
type and level, number of units comprising the title, serial
holdings information.) Also desirable: sample passages, serials
article indexing.
- Support for inter-library lending and Loans (Holdings,
locations, loan status)
- Support for sale and hire (Availability status and charge,
producer/hirer/retailer
- Support for production selection (Statement of intention
to produce, format, producer, copyright permission details.)
- Record format
- Subject indexing
- Genre indexing
While NUCAF had catalogue records for many items, they were
only items converted for the benefit of users with vision disabilities
and they did not include representations in all formats or
modes of access. Initially, they did not include commercially
produced formats and they were expected to be catalogued only
so they could be discovered, as was typical of the understanding
of the use of metadata at the time (Chapman, 1999).
The MARC21 007 fields provide for quite specific information
about the form of tactile representation of information such
as that it is contracted Literary Braille or 'spanner short
form scoring' of music.
Chapman (op. cit, Section 2.4) points out that the existing NUFAC's "only
clearly defined objectives are those that relate to stock management
and production management at the RNIB. It is therefore difficult
for it to satisfactorily address functions outside the RNIB".
She asserted that given the difficulties associated with copyright
with respect to the transformation of information into alternative
formats, the new data base would need to do more. She did not
think of computers at that time as being able to automatically
decompose information resources and recompose them to suit
the needs and preferences of users. Her final recommendations
included that, "The database must provide data rich bibliographic
records".
At the time, the Library was UK’s most comprehensive collection
of material on the subject of visual impairment. The resultant
REVEALWEB, at the beginning of 2006, boasted 100,000 resources
in accessible formats (2006).
This is indicative of the quantity of material that could be
made available for use by people with vision disabilities,
and therefore all others who are for one reason or another
not using their eyes as they might to view content.
REVEALWEB's formats are:
- Braille
- Braille Music (based on the same six dots as traditional
Braille letters but in addition there are separate symbols
for each note, key, tempo and duration)
- Moon (a line-based tactile code in which many of the letters
are simplified versions of the printed alphabet that is easier
to learn than Braille and helps many older people continue
to enjoy reading for themselves)
- Braille with Print
- Moon and Print
- Tactile maps and diagrams (produced by either photocopying
or printing onto heat sensitive 'swell' paper)
- Audio cassettes 2 track (often produced with the author
or an actor reading the printed word)
- Audio cassettes 4 track (that need special equipment for
playback)
- Talking Books 8 track (digital audio files on CD)
- CD-ROMs spoken word
- DAISY (DTB) format (Digital Accessible Information System
that enables navigation)
- Electronic text files
- Electronic Braille music files
- Electronic Braille files
- Large Print
- Audio described videos. (RevealWeb,
2006)
Given the size of this collection of well-described, discoverable
materials, it is important that any new metadata descriptions
are interoperable with this list. There is every indication
that these resource are described with standard metadata and
therefore could be used by an AccessForAll service.
National Library Service for the Blind and Physically Handicapped
(NLS), Library of Congress
The USA also has a union catalogue maintained by the Library
of Congress National Library Service for the Blind and Physically
Handicapped [NLS]. The Union Catalogue (BPHP) and the file
of In-Process Publications (BPHI) can both be searched via
the NLS Web site [NLS].
Indicative statistics for the NLS (according to those posted
on 2005-01-11) are:
Each year it distributes 23 million books and magazines
to a readership of more than 759,000 individuals who cannot
read regular print for visual or physical reasons. NLS functions
as the largest and frequently only source of recreational
and information reading materials and services for a segment
of the population who cannot readily use the print materials
of public libraries. The NLS International Union Catalog
contains 382,000 titles in 22 million copies. (NLS,
2002)
The formats available appear to be press Braille, digital
Braille (Web-Braille), audio cassettes, large print text, digital
text, maps (tactile), electronic resource, music (Braille),
music (large print), and sound recordings (NLS,
2006).
In a fact sheet, NLS explains: "Currently, this service
includes the acquisition, production, and distribution of Braille
and recorded books and magazines, necessary playback equipment,
catalogs and other publications, and publicity and marketing
materials" and that, "One of the primary reasons
for instituting a national program was to obviate the inevitable
difficulty and high cost for individual libraries to acquire
books in special formats" (NLS
About, 2006). In a sense, this is the same motivation
as is being suggested in this thesis for the development of
a metadata standard for AccessForAll materials.
The Library of Congress uses standard metadata for this
collection of resources. There is therefore, evidence that there are
alternatives available for immediate use by people with disabilities
and that they are already described by suitable metadata. They
could be used by an AccessForAll service.
Other services
The American Printing House for the Blind [APH]
currently hosts the Louis Database of Accessible Materials
for People who are Blind or Visually Impaired. The Louis
Database contains over 145,000 titles of accessible materials,
in Braille, large print, sound recordings and computer files,
from over 200 agencies throughout the United States. The
database can be searched via the database Web site and there
is a link to the NLS Web site and union catalogue database.
The Canadian National Institute for the Blind operate a
number of services including online access to their library
collection via VISUCAT.
The library collection contains over 45,000 titles with materials
in braille, print braille, audio, electronic text and descriptive
video. Access to the catalogue is via a telnet connection.
Library clients can search VISUCAT, check on titles currently
on loan to them and reserve titles.
Vision Australia has a number of services including a database that points to organisations that provide alternative formats. Universities around Australia have in-house units that work on alternative formats for their students.
The relevant organisations clearly have a lot of resources
to offer and many of these already have standard metadata describing
them. It can be assumed that if such resources can be used
more frequently and discovered more generally, their beneficial value will increase and more of them will be made
available.
Dynamic Content Adaptation Services
There are two kinds of content adaptation services: those
that adapt the components of a resource to fit a given specification
and those that in some way adapt the components, such as converting
text into Braille. As well as static, or held content, there
are services for creating accessible content - some of which
work on-the-fly and others which can be used asynchronously.
There are any number of such services in the world, but only
a few major ones need to be considered here to establish the
possibilities.
Component adaptation services
The Speech-to-Text Services
Network
For some time the Speech-to-Text Services Network [STSN]
has been making accessible content alternatives
for content that cannot be used by people with hearing disabilities.
They describe their three real-time speech-to-text services
according to the technology used to process incoming speech:
- Steno machine-based systems, commonly called CART (Communication
Access Realtime Translation),
- Laptop-based speed typing software systems (C-Print and
TypeWell),
- Laptop-based Automatic Speech Recognition software systems
(e.g., CaptionMic, iCommunicator).
The STSN has a table that shows differences and similarities
among their services. This table also makes clear the sort
of services that are valued by people with hearing disabilities.
Some of these are relevant in the current context because they
represent services that some people will use when they cannot
access auditory information.
As is apparent from Table 4, human services are provided
to render the content accessible to those who are not able
to hear it in its original form. Such services exist alongside
new ones being developed like those offered and proposed by ubAccess,
particularly SWAP that
will utilise computers to perform 'intelligent actions' on
inaccessible content (Chapter 5).
ubAccess
ubAccess (mentioned in Chapter 5) is an example of an organisation that has developed
an adaptation service. The wizard called the Semantic Web Accessibility Platform [SWAP],
can transform a given Web page to have characteristics
that will suit users with special needs. As this service depends
upon knowing the users' needs, it is appropriate for it to
be considered as an example of the type of service that will
be supported by the AccessForAll approach to accessibility.
Component selection services
There are many services that are built into content servers
that could be described as adapting content, or components
of aggregate content, into suitable composites for users. In
general, these are driven by the device and software requirements.
The materials delivered to a telephone by a standards compliant
browser will at least attempt to adapt the resource for that
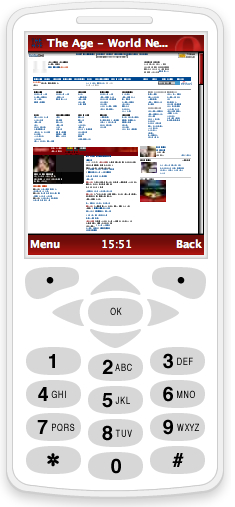
device. For example, the Opera browser can present the user
with a newspaper page in a way that makes sense to someone
with a very small screen, as shown in Figure 45. Opera has
recently released a browser for general use that contains a
screen reader (ref???).
Dublin Core accessibility metadata
The early Dublin Core accessibility work is relevant because it cleared
the way for the AccessForAll approach that has become the main
work of that group.
The Dublin Core Accessibility Working Group
was founded in 2001 to investigate the use of metadata
in accessibility work (DC
Accessibility Working Group, 2001). There was a follow-up
joint Meeting of the W3C/WAI Interest Group and the IMS Accessibility
Working Group in Melbourne, Australia, in November 2001 (WAI-IG,
2001). The aim, at the time, was to be proactive in
setting an accessibility agenda for content developers by bringing
to their attention the need for accessibility, as much as to
provide functional metadata. Some time later, as a Director
of DCMI, Eric Miller strongly defended this position at a
meeting of the DCMI Advisory Committee (as it was then), where there
was general support for the work.
AccessForAll and DC metadata
The early work on the AccessForAll approach has been described.
Now the special requirements for Dublin Core metadata are considered.
The
'rules' for DC metadata have always been that the metadata
terms must comply with the Dublin Core information (abstract) model [DCMI DCAM]. That
the model has not, until late in 2007, been expressed in an
unambiguous way (see further details in Chapter 6). This problem made it very difficult to know how, exactly, to develop conformant Dublin Core metadata. Once the
accessibility work left the narrow confines of the DC community and was led elsewhere
based on another type of metadata, the best that coulld be
done was to ensure that the new metadata matched as closely
as possible the DC model, and that it was at least possible
to cross-walk without loss from one system to another.
Given the changing nature of the DC model, there were many
iterations of the AfA metadata in an attempt to match the
DC model but they always seemed to fail to do this. Once the
model became stable, it was possible to determine the requirements
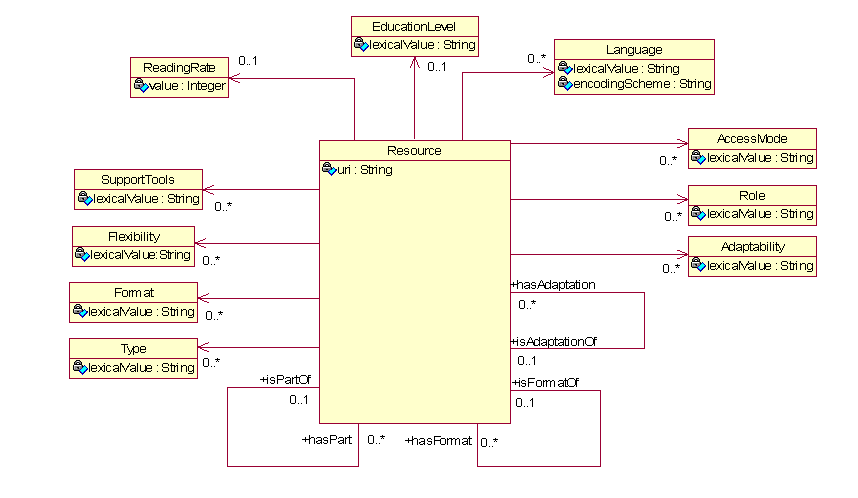
once and for all and the most recent version of the abstract
model of the DC AfA metadata (Figure 46) is conformant to the official DC Abstract Model.
This
model and the associated vocabularies have not been formally
adopted by DC, which requires the approval of the DC Usage
Board, but it has been informally accepted as now matching
the rules. Achieving this status required input to the DC process
of definition of that abstract model, as well as the development
of this one to match it (Chapter 6; Pulis & Nevile,
2006 now online?).
Ensuring metadata is not too complicated to be useful
In 2007, Andy Powell had the following to say in the context
of educational metadata:
so what does history teach us? Why are we where we are now?
I would argue that the "effort aimed at distilling semantics & simplifying
them through delivering sufficient consensus across a significant
community of practice" essentially failed. It failed
because the approaches reached thru that consensus cost more
to implement than the benefits they realise in the context
of the original use-case (resource discovery on the Web).
When was the last time you found something because it had
been described using DC?
What history tells us is that DC is too complex for the
'simple' resource discovery scenarios envisaged when the
initiative started. Those scenarios now tend to be catered
for by full-text indexing and social tagging of one form
or another. At the same time DC is not complex enough for
the scenarios typically found in digital libraries, scholarly
communication, elearning, commerce and the like.
Yes, the DCMI Abstract Model tends to move us more towards
the latter. Yes, explicitly modelling the entities in the
world that we want to describe is more complex than not doing
so.
Complex but necessary. All IMHO of course.(Powell,
2007)
In a sense, the metadata being proposed for accessibility
is very complex but it is meant to be used differently in different
circumstances. The typical use of it is with a single term
(Dublin Core or other) where
the values identify limitations to the perception mode for
the content. The adoption of a new Dubin Core term 'accessibility' is in progress [DCMI Access]. This information alone
will make a huge difference to discoverability for a user by warning them of inappropriate material, as well as by pointing to appropriate material.
With such metadata, when a resource is made or catalogued by experts and
designed to satisfy an accessibility problem, those who have
developed it can use their expertise to give maximum value,
and exposure, to the resource.
Accessibility Metadata and WCAG 2.0
The final development stages of the WCAG 2.0 specifications
[WCAG-2] have been contemporaneous with the finalisation of AfA
as an ISO standard. Convincing the W3C Working Group responsible
for WCAG 2.0 to include a requirement for AfA metadata would
have made all WCAG 2.0 conformant resources suitable
for adaptation according to AfA principles. For a number of
reasons this was not possible, not the least being that the
WCAG authors were not prepared to simultaneously allow
that a resource might be less than conformant to the rest of
WCAG and yet 'legitimately' be described by metadata as specified
by WCAG. They did consider it important to allow for the use
of metadata, however, especially to identify an alternative
resource that could be used when that alternative
had special features to make it more useful than a standard,
conformant resource, and the original was already WCAG conformant.
Given the inclusion of this as a technique, there is, of course,
no reason why a developer should not provide full AfA metadata
and if there are tools that make this easy, it might happen.
The proposed DC accessibility term [DCMI Access]is defined according to the WCAG 2.0 specification of accessibilty in that it recognises and adopts the WCAG 2.0 definition of accessibility [WCAG-2].
Chapter Summary
In this chapter, the availability of resources
that will already have metadata is investigated for two reasons:
if there are, in fact, no significant sources of alternative components that are accessible
to people with disabilities, there will be nothing to find,
and secondly, because if such accessible components do exist,
it is important that they are organised and described with electronic
catalogues that are capable of providing AfA metadata, even if it
needs to be transformed to comply with the interoperable standards. It is critical to have established that the research is not undertaken in a vacuum, but rather in an environment where it can have immediate application.
Dublin Core metadata is central to the research, so the expectations of the Dublin Core community are critical, and understanding their involvement is therefore essential.
In the next two chapters, the metadata profiles developed as the first pair of AccessForAll modules are described.
Next ->
 This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile