Chapter 11: Implementation
Introduction
This chapter engages with the question of practicality,
or generality: will this research lead to new behaviours and
so make the Web of information more accessible to more people?
It includes reports of implementations
of the AccessForAll style metadata.
Implementation of the AccessForAll approach to accessibility can take place at many levels. It is considered a strength of the work that if all that is adopted is a sigle metadata term that can help users find what they need, there will be value in the effort. This is the approach being taken by the DCMI and the AGLS. At the other end of the spectrum, there are instances of implementation where both the description of needs and preferences and of the accessibility features of the resources are used in automated systems to provide appropriate resources for users. Implementation can mean anything in between, as well.
The chapter is presented in four parts: recognition, standards, local utilisation, and global Web-distributed implementations.
Implementation
On November 1, 2008, the following was notified to those interested in the content development system ATutor:
Adaptability has always been a high priority in the development of ATutor. Implementing AccessForAll in ATutor 1.6.2 extends further the system's adaptability to the needs of individual learners. With the addition of quite a number of new user preference settings, learners can now customize the environment to work best for them. They can control the appearance of ATutor; which navigation tools are configured; and how content is adapted to their own abilities and learning styles. AccessForAll adds greatly to a learner centered approach to learning.
Implementing AccessForAll (AFA) in ATutor has been (and still is) a challenge. While we worked, IMS AccessForAll 1.0 was in transition, and the new ISO FDIS 24751 Accessibility standard was on the verge of existence. Before the end of our project, the ISO standard was released. According to sources at IMS, AccessForAll 2.0 will be based largely on ISO FDIS 24751. So we transitioned from AccessForAll 1.0 to ISO FDIS 24751, with the intent of conforming with AccessForAll 2.0 when it's ready. We have used the language and the metadata structure from the ISO standard in our implementation, though the systems for creating and sharing content in ATutor, through each standard, function much the same way. (Gay, 2008)
ATutor is a content authoring system developed by the Adaptive Technology Resource Centre [ATRC] , the organisation that also developed as an AccessForAll prototype, The Inclusive Learning Exchange [TILE]. As Gay (2008) points out, implementation has been difficult while the standards have been in development but, nevertheless, there have been efforts underway to use the standards.
By July 2006, it was clear that the AccessForAll approach
was being adopted in the educational domain (Appendix
4). By October 2007, there were 86 resources listed as
relevant to AccessForAll and a glance through the list shows
the dissemination of this idea throughout the academic world
(Appendix 5). The Accessibility
Guidelines that preceded the AfA work were read 176,505
times between
Sept 2002 and June 2006 and in the same period the IMS AfA
Specifications were downloaded 28,082 times. The United
Kingdom Government included the need for metadata in
its standard for accessible documents in the UK (Appendix
6) and on October 16, 2007 the Australian Government
Locator Standard Committee voted to include an AccessForAll
metadata element for all accessible documents in Australia
(IT-021-08,
2007, p. 14). At the same AGLS meeting, the
National Library of Australia representative reported that
the NLA is starting to write metadata for individual components
such as images and songs (IT-021-08,
2007, p. 14). This is an important, although
independent, action that will contribute towards implementation
of AccessForAll. Concurrently, the ISO/IEC JTC1 SC35 is developing
a user profile for use with the
universal resource console (Chapter
8).
As Matteo Boni and colleagues assert:
Accessible e-learning is becoming a key issue in ensuring
a complete inclusion of people with disabilities within the
knowledge society. Many efforts have been done to include
accessibility information in e-learning metadata and the
major result consists in the IMS AccessForAll Metadata definition.
Unfortunately the complex behavior managed by this standard
could be perceived by authors as a new boring and difficult
activity enforcing the idea that the production of accessible
Learning Objects (LOs) is too complex to be accomplished. (Boni et al, 2006)
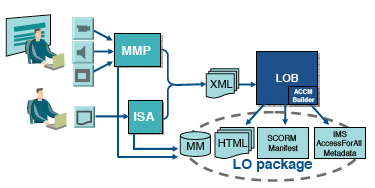
Boni et al, in 2006, described
a novel component of an authoring and
producing software architecture, designed and implemented
to automatically create the IMS AccessForAll Metadata description
of an accessible LO. They integrated the process into the workflow
as shown in Figure ???.
Having described the relevant user needs and resource profiles, Boni et al (2006) continue:
While these metadata represent a truly enabling option,
implementing an ACCMD description of each LO could turn
into a new tiresome and protracted task for authors.
Reducing the distance between users’ needs and authors’ efforts
is
now a crucial aspect to ensure accessibility of e-learning
materials. The solution relies on authoring tools for creating
LO
that have to accomplish two main goals:
1. Offering support to author in creating fully inclusive
materials by suggesting correct behaviors and
sometimes imposing the completion of all additional
information needed to ensure accessibility (e.g. once the
image is inserted, the authoring tool ask for a
description that is required for blind users).
2. Automatically structuring the media alternatives, both
inserting correct markup inside the (X)HTML pages and
describing the whole structure with ACCMD. (Boni et al, 2006)
They say:
Such a tool is now integrated in a complex process used
inside the
University of Bologna to create accessible LOs. Accessibility
of
e-learning materials produced has been widely tested by involving
a group of people with disability in verifying on-line contents
and
services. Universality of materials has been tested by using
different browser running on different platforms (specifically
MS
Internet Explorer 5.0 and later, Mozilla Firefox 1.0 and
later, Netscape Communicator 7.0 and later, Lynx 2.8.4 rel.
1, IBM Home Page Reader 3.0, Apple Safari 1.0). Finally,
LOs produced by our process are compliant to all the constraints
considered by
the Italian Law on Web Accessibility, (Boni et al, 2006)
That tool and its use are described
in more detail in "Automatically
Producing Accessible Learning Objects"
(Di Iorio
et al, 2006). The research has also led to a reported on using
an accessibility evaluation tool that can produce the necessary
metadata (Nevile,
2004).
But Boni et al say:
Unfortunately, the IMS description is ignored by the LCMS
(Learning Content Management System) in use. Generally this
new technology is not fully supported and there are just
few
solutions that use ACCMD and ACCLIP to provide adaptive
accessible contents. We assume that a growing availability
of IMS
ACCMD tagged LOs will drive the development of adaptive
modules for the more diffuse LCMS and will definitively diffuse
the use of the whole IMS specification on accessibility.
The ATutor development team seem to have heeded the suggestion from Cenni et al. Unfortunately, the ATutor development team is closely connected wih the AccessForAll work, so not indicative of what is being done generally towards AccessForAll implementation.
So the problem being considered here is the one of production of metadata. There are many ways this can happen:
- as a direct result of automated classification (of characteristics susceptible to automated evaluation) by authoring systems or accessibility evaluation systems, as exemplified by ATutor, AccMonitor, and others.
- as authored content, contributed within a workflow of authoring content, as proposed by Cenni et al.
- as metadata provided by a third party classification process, such a within a library cataloguing system.
- as third party, independent metadata made available on the Web, or
- as tags, contributed to a metadata pool, as in the case of a system such as delicio.us etc.
So the problem is not how should this be done in a technical sense, but how can the critical quantity of metadata neeed to be useful, be motivated? As already shown in Chapter 7, there are alternative resources available for users with some special needs and there is some metadata, but it is not in the AccessForAll format. In recognition of the problem that metadata is not easy to come by, and reliable metadata is even more scarce, the author has worked with the Dublin Core Metadata Initiative for a decade. The relative simplicity of DC metadata and its generality in domain has made it one of the most popular, and thus prolific metadata standards.With the hope that by implementing the AccessForAll approach within the DC metadata context, the research has focused on this goal.
AccessForAll recognition
Implementation of AfA is not yet simple. While there is a
set of machine-readable resources to help those implementing
it in the educational context where they use IEEE LOM metadata,
this is not yet the case for DC metadata, expected to be a
much larger implementation context. Nevertheless, the signs
are very positive as shown by the emerging evidence of acceptance
of the AccessForAll approach.
In "Beyond the LOM: A New Generation
of Specifications," Michael
J. Halm says:
The importance of the ACCLIP specification may not be immediately
understood, but this specification provides enormous opportunities
to customize and adapt the learning experience based on the
users preference. This powerful capability now can
be used for anyone, not just those with disabilities. These
preferences will be stored in the Learner Information Package
and could travel with the learner from one on-line environment
to another. Since these preferences are created and
maintained by the learner, this gives the individual the
control to change the environment as needed. This also allows
one to consider the learning style of the learner as part
of the environment. Visual learner will be better able
to set preferences that are unique to the type of way they
learn. This preference can translate into the type
of learning objects that are selected and deliver in the
learning environment (Halm,
2003).
W3C recognition of AfA metadata in POWDER
The set of POWDER use cases include the following contributed to by the author:
2.1.6 Web Accessibility B (self labeling, content features,
profile matching)
- Colin is a student at the world university. Colin sometimes
studies at home with special Braille equipment but likes
to listen to course readings when he is on campus, using
a screen reader (profile 1). His sister Mary sometimes likes
to work with him, sharing a computer and describing what's
happening, as they are studying the same subjects (profile
2). When Mary is studying alone she uses no assistive technology
(profile 3). Between them therefore they have three profiles
of needs and preferences and may change between them. The
profiles impose different requirements on the resources that
Colin and Mary can use adequately.
- The university's staff produce teaching materials in alternative
versions to suit different user needs as closely as possible.
Staff are trained to create labels describing the accessibility
features of their materials with AccessForAll Metadata [AFA].
- The university's web site has an application that stores
profiles of user needs also expressed in AccessForAll Metadata.
The system analyses content labels embedded in course materials
and uses rules to discover alternative versions of content
suitable for a user's active profile.
- For Mary studying alone (profile 3) a complex diagram
may be presented as-is, but if she is studying with Colin
they may select profile 2 and the system discovers and delivers
to them the same image of the diagram together with a detailed
text description. If Colin is alone he cannot see the image
and selects profile 1 to read only the text description (Archer,
2007).
Engage
The IMS Tools Interoperability project is part of the Engage project
at the University of Wisconsin (UW-Madison). The Engage program partners
with UW-Madison faculty and academic staff to apply innovative
uses of technology for teaching and learning. In this project,
UW-Madison, WebCT, Blackboard, Sun Microsystems, SAKAI, QuestionMark,
and staff from Stanford, UC Berkeley, MIT, Indiana University,
and the University of Michigan are all involved. A special
server edition of ConceptTutor, and a Moodle LMS were proposed
for 2005 Alt-i-lab [Alt-i-lab
2005] conference in Sheffield, England in June 2005.
The aim is:
To promote accessibility and to demonstrate the use of IMS
ACCLIP and ACCMD standards for accessibility, we have modified
Fedora to implement an RDF binding of ACCLIP and ACCMD. A
student’s accessibility preferences are matched to the accessibility
characteristics of the content at the time of the request.
Thus, a visually impaired student will receive content tuned
to her needs when she requests a ConceptTutor without having
to know how to request the specially tuned content (Engage,
2007).
SAKAI
SAKAI is a university consortium effort to develop a set of
open source tools for tertiary education ref???. On Feb 20, 2007, Anastasia Cheetham wrote:
The TransformAble package is now a part of Sakai. TransformAble is being developed by the Adaptive Technology Resource Centre at the University of Toronto. It is useful for users who want to customize Sakai's appearance to improve the readability and accessibility. TransformAble consists of two parts: StyleAble is a component that generates customized style sheets based on a user's stated preferences, allowing them to control the overall appearance of the site, including the font size, face, foreground colour, background colour, highlight colour, and link appearance. User preferences are created through a tool currently called PreferAble, which (once un-stealthed) can be added to any workspace. (Cheetham, 2007)
Fluid
The Fluid Project [1] is an international community of academic institutions, open source software projects and corporations working together to address the precarious values of usability and accessibility within open software projects.
Fluid is creating a library of accessible, rich Web 2.0 user interface components that can be reused across web applications. These components are built specifically to support flexibility and customization while maintaining a high standard of design quality. The Fluid framework will enable designers and developers to build user interfaces that can more readily accommodate the diverse personal and institutional needs found within open source projects.
Personalization and User Interface Metadata with AccessForAll
The rich user interface customization and flexibility of the Fluid architecture depends on the availability of clearly defined standards for UI component semantics and user preferences. These semantics will provide the basis for conveying the nature and context of UI components to the framework, enabling the transformation and substitution of suitably marked-up components at runtime.
The Fluid community is driving new additions to ISO/IMS AccessForAll [6] specification relating to user interface transformation. This work will be broadly useful for Web 2.0 applications, providing a foundation on which to build accessible mash-ups and user interface components. We are currently in the process of defining a new branch of the AccessForAll standard to describe how user interfaces are controlled and presented to the user, as well as a matching set of user preferences metadata. (Clark & Schwerdtfeger, 2007)
Fluid is thus adopting the work on AccessForAll and has led to the addition of two new draft parts for the ISO/IEC standard, N24751, Parts ??? and ??? (ref???).
Metadata in WCAG 2.0
In late 2007, the WCAG Working Group is finalising Version
2.0 of WCAG. The last remaining problem is what to do about
metadata. It has produced some interesting challenges. The
AccessForAll position, put by the author to the WCAG WG, is
that there should be metadata to describe the content of every
resource, inclusing its accessibility characteristics, on every
Web page that is considered accessible. The Chair of the WCAG
WG, Gregg Vanderheyden, is interested because he sees that
in the case where a page is accessible in the sense that it
is conformant, someone who wants a version of the page that
happens to suit them but is not fully conformant, might want
to find that version. As Jutta Treviranus wrote, (24/10/2007
- email):
I think we are missing the point. An important consideration
is that Metadata does not require and is not about conformance.
It is about labelling and finding accessible resources. You
need to think beyond a single site or a single page. If there
are a number of resources and some are accessible to you and
some are not, Metadata helps you to find the ones that are
accessible to you or alternatively to gather the same information
as the Web resource you want from a number of pieces that are
accessible to you. So is WCAG only about access to a single
site or about access to the Web? If it is about access to the
Web then you need to think about systems and varied resources,
some that are more accessible to a given user and some that
are not.
Sadly, some think, the response to this was:
This is beyond the scope of WCAG 2.0. It sounds like a good
candidate for the next version.
WCAG 2.0 is addressing the accessibility of Web pages, the
unit of conformance. There are a number of other issues related
to the larger view of the web that have also been deferred
to future work. (Loretta, 24/10/2007
- email)
One major constraint for W3C's work is that it needs to result
in technical specifications; nothing can be recommended
that cannot
be tested. Another constraint is that it must be possible in
every case. Vanderheyden posed the problem of the resource
that is to be published but, by law, cannot be altered any
way in the process. An example is an historic digital image,
that has value in being that image. The problem with that image
would be that metadata could not be added to it and nor could
even a link to metadata. Fortunately, on the day this problem
was to be solved, another W3C WG released their first version
of a solution. The Internet Content Ratings Association community
want to be able to add metadata about resources that is very
similar to the AfA metadata in type - they want to describe
the relevant characteristics of resource content that leads
to ratings for nudity, violence, etc. The W3C Protocol
for Web Description Resources (POWDER) Working
Group [POWDER WG]
developed POWDER to enable information to be conveyed via the
http head of a resource and this is just what is needed for
the Vanderheyden problem. The issue is what is to be conveyed,
and the POWDER WG has now modified their examples to include
two use cases that draw upon AfA metadata.
Distributed Accessibility
While the TILE model can be extended within a given context,
it is probably not until it is working across vast numbers
of resources and context that it will really start to pay off
for the individuals. The issue is: if a component is not accessible,
how can an alternative resource, or component or service be
discovered on the Web, if there is such a thing?
There are at least three approaches being considered; FRBR
descriptions, OpenURIs and POWDER.
The author asserts that if it
is easier to find alternatives on the Web, and items of interest
in one mode are also available in other modes because more
items are available and they are discoverable, providing users
with alternatives to inaccessible content will become more
of a community activity and thus more successful. If this hypothesis
is right, the burden on individual content developers can shift
a little from the frustratingly unsuccessful one of requiring
all content to be provided in universally accessible
form, to a requirement to provide accessibility services.
In the rare case where a resouce for
some reason cannot be associated with metadata, for example
when it is a sppecial archive and by law cannot have any chancges,
not even the addition of metadata, it may be possible to use
the POWDER protocol and put metadata in the HTTP header.
FRBR descriptions
rgnwrgnrf
OpenURL
One possibility is to launch a query once, and to develop
a service that can formulate a suitable OpenURL from a user's
content query in combination with their needs and preferences
profile. Wikipedia provides a useful explanation of OpenURI:
An OpenURL consists of a base URL, which addresses the user's
institutional link-server, and a query-string, which contains
contextual data, typically in the form of key-value pairs.
The contextual data is most often bibliographic data, but
in version 1.0 of OpenURL can also include information about
the requester, the resource containing the hyperlink, the
type of service required, and so forth. For example:
http://resolver.example.edu/cgi?genre=book&isbn=0836218310&title=The+Far+Side+Gallery+3
is a version 0.1 OpenURL describing a book. ...
The most common application of OpenURL is to provide appropriate
copy resolution: an OpenURL link points to the copy of the
resource most appropriate to the context of the request.
If a different context is expressed in the query, a different
copy ends up resolved to; but the change in context is predictable,
and does not require the creator of the hyperlink to handcraft
different URLs for different contexts. For instance, changing
either the base URL or a requester parameter in the query
string can mean that the OpenURL resolves to a copy of a
resource in a different library. So the same OpenURL, contained
for instance in an electronic journal, can be adjusted by
either library to provide access to their own copy of the
resource, without completely overwriting the journal's hyperlink.
The journal provider in turn is no longer required to provide
a different version of the journal, with different hyperlinks,
for each subscribing library (Wikipedia,
2007).
In simple terms, an openURI contains a place for customisation
information to be added by a server. It is not difficult to
imagine a versio of OpenURI that adds information not about
the particular location of a copy of a book that is in a number
of places, but about an accessible alternative version of a
content component.
The future
There is a growing community who are
publishing small objects on the Web and even offering some
description of them. Social activities are then taking over
and others are adding ‘tags' to those objects. As, in the end,
such tags may be more plentiful than other metadata, we are
interested in how this activity may serve to increase the effectiveness
of our process.
Increasingly, images are ‘tagged'
by either their creators or others. If an image is tagged,
using such systems as Flickr (FLICKR online at <http://www.flickr.com/>),
the tags could be used to discover a text resource that has
the same intellectual content. We are aware that while it can
be asserted with some confidence that tagging of images and
the number of images on the Web is increasing, it is not yet
clear if the same will be true for resources in other modalities.
Although there is not an obvious rush to place text versions
of sound files on the Web, there is a strong move towards more
atomic resources and, in many cases, those are small ‘chunks'
of text. The drive behind this move is the growing interest
in RSS (Really Simple Syndication or RDF Site Summary) (RSS
Specification online at <http://web.resource.org/rss/1.0/spec>)
feeds, and many people are responding to this use of personal
‘pull' technologies by publishing in ways that support RSS.
There is, then, some hope that there will be small chunks of
text that are tagged and may be useful as alternatives to images.
Chapter summary
In this chapter, ...
Next ->
NOTEs
- CAL has a list of master files that are electronic verison
of print materials for print disabled people (Section V something
of a new provision) but this list is only available to people
who are registered with CAL - if others want the masters,
we need to get CAL to do that but they are protecting the
authors...
- Victorian government requires all depts to tag all documents
stating where alternatives are available or howho they should
contact if they need one. This aims to both help the people
with the needs etc but also to bring awareness of the problem
to the people working in the various depts.... ref is keynote
presentation "Making Government Accessible" by
Hilary Fisher, Department of Premier and Cabinet, Victorian
Government, at Alternate Format Conference, 22/01/2008 at
La Trobe University.
- UTS tags material in special form showing what is useful
to which student and they then watch what is used by students
and use it as a way of monitoring and helping students more
acurately - Madeleine Mann, librarian at UTS presenting at
AFC, 22/01/2008
- The Victorian Charter of Human Rights and Responsibilities
Act 2006 (Vic) requires laws to comply with charter etc....see http://www.equalopportunitycommission.vic.gov.au/human%20rights/the%20victorian%20charter%20of%20human%20rights%20and%20responsibilities/default.asp based
on UK act. This is a preventative charter - raising awareness
and preventing the creation of problems. The Charter came
into effect in 2007 but is extended to public sector in 2008.
- see email from Julie Rae ??? Vison Australia 10/7/2008
about a world wide effort to make a repository of accessible
alternatives....