NOTES:
In this printing of the thesis, there are no images. Allimages for the thesis will be provided with ‘long descriptions’ foraccessibility reasons and these will be incorporated into the text.
The appendices are also not included.
The images and appendices are all available online in themaster version of the thesis at
TO DO:
Table of contents, figures and tables (complete labels etc)
Glossary (definitions of terms from thesis)
Summary of thesis (1000 words)
Timeline of author’s contributions
AccessForAll: Metadata forUser-centred, Inclusive Access to Digital Resources
ElizabethAylward Nevile
BJuris/LLB (Monash) MEd (RMIT)
School of Mathematical and GeospatialSciences,
Science, Engineering and Technology Portfolio, RMIT University.
month and year when the thesis is submittedfor the degree.
Except where due acknowledgement has beenmade, the work is that of the candidate alone. The work has not been submittedpreviously, in whole or in part, to qualify for any other academic award. Thecontent of the thesis is the result of work that has been carried out since theofficial commencement date of the approved research program. No editorial workhas been carried out by a third party and ethics procedures and guidelines havebeen followed.
for ref guides see
Acknowledgements
This research has had special assistance from a number ofsources. In combination, they have made it possible for work to be undertakenin an integrated and supportive environment. The early analysis of accessibleWeb Content Development (Appendix 8) was supported financially by a number ofAustralian and international agencies. The research has been supported duringtwo periods at University of Tsukuba in Japan where the author was a verygrateful Visiting Research Scientist.
Some documents based on the research were co-authored incollaboration with members of the IMS Global Learning Consortium, the DublinCore DC Accessibility Working Group, ISO/IEC JTC1 SC36, and members of theINCITS V2 Working Group and MMI-DC Accessibility and Multilingual Workshops(see Appendices 1 and 2). The author was a working member of all these workinggroups and is grateful for the environment they created.
| Supportive bodies | Description of assistance |
| IMS Australia, participating in the IMS Web Content Accessibility work was supported by DEST. | |
| IMS Global Learning Consortium Accessibility Working Group - in particular, Jutta Treviranus, Madeleine Rothberg, Cathleen Barstow, Andy Heath, Hazel Kennedy Anastasia Cheetham, David Weinkauf, Mark Norton, Alex Jackl and Martyn Cooper. | |
| http://www.linguistics.unimelb.edu.au/ | Paul Gruba |
| MELB-WAG | |
| Martin Ford, Martin Ford Consultancy, with whom the author undertook accessibility and metadata standards work in Europe. | |
| University of Melbourne, Department of Information Systems, for a grant to work on WebCT's accessibility, accommodation and a friendly environment in which to work. All were essential and appreciated. | |
| Oregon State University... | Particular thanks to John Gardner and others for their help with the difficult topics of haptic representations, mathematics, science etc. |
| | Very special thanks to Charles McCathieNevile for his encouragement, sharp critique, friendship and, of course, his expert advice. |
| La Trobe University, Department of Computing and Mathematical Sciences, for a position as an Adjunct Associate Professor and making it easy to do research. | |
| University of Tsukuba for wonderful times to work and learn about the Japanese way of life and an interest in further research to do with distributed resources. | |
| | Behzad Kateli, Sophie Lissonnet, James Munro and Sarah Pulis, former students who have been very helpful throughout the research and offered useful technical advice and personal support. |
| and | my very wonderful, tolerant and supportive family. |
Table 1 - Table of acknowledgements
Table of Contents
AccessForAll:Metadata for User-centred, Inclusive Access to Digital Resources
Acknowledgements
Table of Contents
Images and Tables– incomplete???............................................................................... 8
Table of tables
Thesis Summary (1000words - still drafty)................................................................ 11
Abbreviations and Websites................................................................................... 12
Glossary of terms17
Relevant AccessibilityOrganisations.................................................................... 19
Relevant AccessibilityStandards Organisations................................................... 21
Chapter 1: Preamble24
Introduction24
Background25
An outdated view ofaccessibility and the Web....................................................... 30
A new approach toaccessibility for an updated Web............................................... 31
Understanding andsignificance of accessibility..................................................... 33
AccessForAll philosophy35
A metadata approach36
AccessForAll metadatadevelopment..................................................................... 37
AccessForAll metadataresearch........................................................................... 38
Research objectives39
Summary40
Chapter 2: Introduction42
Preliminary, practicaldefinitions......................................................................... 43
Research scopelimitations..................................................................................... 51
Research methodology52
Research activities58
Chapter Summaries62
Chapter 3:Accessibility and Disability...................................................... 64
Introduction64
Understandingaccessibility................................................................................... 64
Models of disability66
Inaccessibility andusers......................................................................................... 68
Disability asfunctional requirements.................................................................... 70
Accessible resources76
Quantifying theaccessibility context.................................................................... 80
Chapter 4: Universaldesign............................................................................ 87
Introduction87
The early-history ofaccessibility.......................................................................... 87
Separation of Structureand Presentation............................................................. 92
The WAI Requirements94
WAI Compliance andConformance......................................................................... 95
Special resources forpeople with disabilities.......................................................... 96
Universal design97
Universal Accessibility- the W3C Approach.......................................................... 98
The UK DisabilitiesRights Commission Report....................................................... 98
Chapter summary108
Chapter 5: Other routesto Accessibility............................................. 110
Introduction110
Beyond 'universal'accessibility......................................................................... 110
Accessible code andaccessible services............................................................... 111
Responsible foraccessibility............................................................................... 112
EuroAccessibility116
A Practical Approach119
Relevantpost-production services and libraries................................................. 120
Chapter summary120
Chapter 6: Metadata122
Introduction122
Definitions of metadata122
Formal Definition of DCMetadata..................................................................... 127
Graphical (andinteractive) metadata................................................................ 133
Chapter summary140
Chapter 7:Accessibility Metadata........................................................... 141
Introduction141
Existing accessibilitymetadata.......................................................................... 141
Dynamic ContentAdaptation Services................................................................ 146
Dublin Coreaccessibility metadata.................................................................... 147
Accessibility metadataand WCAG 2.0................................................................. 149
Chapter summary150
Chapter 8: User needsand preferences................................................... 151
Introduction151
Individual differences151
RelationshipDescriptions.................................................................................... 154
Profiles of user needsand preferences................................................................. 158
User needs as aresource...................................................................................... 161
AccessibilityVocabularies.................................................................................. 161
Chapter summary162
Chapter 9: ResourceProfiles...................................................................... 163
Primary and equivalentalternative resources (or components)......................... 164
The AccessForAllmetadata specifications.......................................................... 166
Facilitating discoveryof alternatives............................................................... 169
User Interfaces171
A universal remotecontrol................................................................................ 171
The URC specifications172
FLUID173
Chapter summary174
Chapter 10: Match andinteroperate........................................................ 175
Introduction175
Matching175
The value of metadata177
Functional Requirementsfor Bibliographic Records.......................................... 182
Interoperability185
Background185
Chapter summary193
Chapter 11:Implementation......................................................................... 194
Introduction194
Implementation194
heading??196
Proof of concept196
Implementationactivities................................................................................... 197
Distributed Accessibility200
The future202
Chapter summary202
NOTEs202
Chapter 12: Conclusion204
Introduction204
Final discussion205
Future work206
References207
Citations - odd?233
Images and Tables –incomplete???
Figure???: Map of Signatures and Ratifications of UN Convention A/RES/61/106 as of 10December 2007 [UN Enable]25
Figure ???:...36
Figure ???: ...37
Figure ???: ...37
Figure ???: Australian Prime Minister's Website (42
Figure ??? The metadataas viewed in a Safari browser (Pandora,2007).__________________ 43
Figure ??? The metadataas viewed in a Safari browser (Pandora,2007).__________________ 43
Figure ???: Diagram ofWeb 2.0 (O'Reilly, 2005)44
Figure ???: The simpleAccessForAll model that provides individual users with resources that matchtheir accessibility needs and preferences. why this??? explain it49
Figure ??? Burstein,System development (Burstein, 2002, p. 153)_________________________ 56
Figure ???: New YorkTimes Online (2005)75
Figure ???: accessibilitypages http://www.humanfactors.com/downloads/markup.aspaccessed 15/1/2005 75
Figure 76
Figure ???: UK GovernmentAccounting Web Page_____________________________________ 76
Figure ???: Demo of twopages - sight vs sound differences (HFI-chocolate,2005).___________ 77
Figure 79
Figure 80
Figure ???: Likelihood ofdifficulties by population (Microsoft, 2003b)80
Figure ???: Difficultiesby severity (Microsoft, 2003c)81
Figure 81
Figure 81
Figure ???: WCAG97
Figure 12: ATAG-WCAG-UUAG97
Figure ???: The widercontext for accessibility (Kellyet al, 2005, p. 8)___________________ 107
Figure ???: a tangram (111
Figure ???: A progressiveset of images showing how (RDF or other) tagging of content can be used toseparate content from tags and then the tags themselves can be tagged, orsorted in multiple ways.______________________ 122
Figure ???:simple/complex; global/local___________________________________________ 125
Figure ???: DC metadataas grammar (1) (Baker, 2000)128
Figure ???: DC metadataas grammar (2) (Baker, 2000)128
Figure ???: DCMI ResourceModel (Powell et al, 2007)130
Figure ???: DCMIDescription Set Model (Powell et al, 2007)130
Figure ???: DCMIVocabulary Model (Powell et al, 2007)130
Figure ???: The SingaporeFramework (Nilsson, 2007)131
Figure ???: A tag cloud (134
Figure ???: Topic maps???_____________________________________________________ 135
Figure ???: Topics mapsas an ontology framework__________________________________ 137
and138
Figure ???: Front page ofthe Age newspaper on 9/11/2007 in Safari and Opera Mini showing headlines sophone users can easily select what to read or look at.____________________________________________________ 147
Figure ???: AccessibilityAbstract model (Pulis, 2008)148
Figure ???: AccessForAllstructure and vocabulary (image from AccessForAll Specifications, [154
Figure ???: AccessExtensibility Statement (Jackl, 2003).157
Figure ???: Diagramshowing cycle of searches and role of AccessForAll server158
Figure ???: A typical setof user needs and preferences showing the default and the user's individualchoices. 159
Figure ???: What do weneed to know about an object for accessibility?__________________ 162
Figure ???: Multipleinstantiations of a single Web page (HFI-testing).163
Figure ???: IMS structurefor accessibility metadata from 2.3, Page 7, AccMD Norton, 2004_ 166
Figure ???: A user with a voice-controlled URC and a seated useremploying a touch-controlled URC (GottfriedZimmermann).____________________________________________________________________________ 171
Figure ???: A wheel-chairuser struggling to reach an ATM (HREOC (withpermission).____ 172
Figure ???: As the itemsare adjusted for matching to the user's PNP, their DRD more closely matches thePNP. 174
Figure ??? A pyramidbased on the Howel model of accessibility ????___________________ 176
Figure ???: The reuse ofcomponents in the 48,084 pages on the tested section of the La Trobe Web site.from La Trobe Website audit (Nevile, 2004)177
Figure ???: Thebehaviours for interoperability using AccLIP and AccMD in TILE (178
Figure ???: AnAccessForAll process diagram_______________________________________ 180
Figure ???: The modifiedsection of the original diagram with a separate filtering service shownhighlighted. 180
Figure ???: 4 FRBRentities associated with two resources and their possible relationships(Morozumi et al, 2006). 182
Figure ???: The Globefederated search model using ProLearn Query Language. (Ternier et al, 2008)190
Figure ???: The point ofloss of information in the LOM -> DC translation process (Johnston et al,2007) 191
Figure ???: A possiblestructure of a future metadata standardization framework. from Mikael Nilsson,
Figure ???195
Figure ???: ABC Video ondemand________________________________________________ 196
Figure ???: Thesisstructure_____________________________________________________ 205
Table of tables
| Chapter | Tables |
| title |
table of acknowledgements table of contents table of images and tables |
| post-production | the plan to make WCAG testable |
| acc-metadata | table of services |
| user profiles | AccessForAll structure and vocabulary 6.2.1 Display Preference Set 6.2.2 Screen reader Preference Set 6.2.9 Screen Enhancement Generic Preference Set A typical set of user needs and preferences showing the default and the user's individual choices. |
| resource profiles | IMS structure for accessibility metadata
|
| matching | The behaviours for interoperability using ACCLIP and ACCMD in TILE.
|
| Table ???: Tables | |
ThesisSummary (1000 words - still drafty)
The first decade of internationaleffort to make the Web accessible has not achieved its goal and a differentapproach is needed. In order to be more inclusive, the Web needs publishedresources to be described to enable their tailoring to the needs and preferencesof individual users, and resources need to be continuously improvable accordingto a wide range of needs and preferences, and thus there is a need formanagement of resources that can be achieved with metadata. The specificationof metadata to achieve such a goal is complex given the requirements,themselves not previously determined.
Accessibility is a term often used todescribe property rights and or other aspects of availability of such resourcesor services. In this thesis, the term is used to mean the capability ofindividuals to access digital resources in perceptual modes that areappropriate for them at the time.
Ensuring accessibility of the Web has beena major concern of the World Wide Web Consortium (W3C) for a decade: thoseresponsible for inventing the Web recognised early that the features such asthe graphical user interface that attracted so many to the Web wassimultaneously alienating many from it, because they could not perceive contentin the form in which most of it is provided. For nearly a decade, the Web hasacted as a publishing medium, and efforts to make the publications accessiblehave been based on a set of guidelines developed by international committees ofexperts led by the W3C. The guidelines have acted as specifications fordevelopers.
More recently, the Web has become less ofa one-way publications medium and, now known as Web 2.0, it is an interactivespace in which resources become ‘live’ objects capable of reformation andreforming other resources.
What this thesis offers is an argument infavour of an on-going process approach to accessibility of resources thatsupports continuous improvement of any given resource, not necessarily by theauthor of the resource, and not necessarily by design or with knowledge of theoriginal resource, by contributors who may be distributed globally. It arguesthat the current dependence on production guidelines and post-productionevaluation of resources as either universally accessible or otherwise, does notadequately provide for either the accessibility necessary for individuals orthe continuous or evolutionary approach possible within what is defined as aWeb 2.0 environment. It argues that a distributed, social-networking view ofthe Web as interactive, combined with a social model of disability, given themanagement tools of machine-readable, interoperable AccessForAll metadata, asdeveloped, can support continuous improvement of the accessibility of the Webwith less effort on the part of individual developers and better results forindividual users.
This thesis argues that metadata isessential and integral to any shift to an on-going process approach toaccessibility. It is at the core of the research in as much as it providesessential infrastructure for a new approach to accessibility. (500 words)
Abbreviations and Web sites
Flickr,
ABCVideo On Demand http://www.abc.net.au/vod/news/
AbilityNethttp://www.abilitynet.co.uk/content/news.htm
AccLIPBPG, IMS Learner Information Package Accessibility for LIP Best Practice Guide-
AccLIPBinding, IMS Learner Information Package Accessibility for LIP XML Binding -
AccLIPIM, IMS Learner Information Package Accessibility for LIP Information Model -
AccLIPConf, IMS Learner Information Package Accessibility for LIP ConformanceSpecification -
AccLIPUC, IMS Learner Information Package Accessibility for LIP Use Cases -
AccMDOverview, IMS AccessForAll Meta-data Overview
AccMDIM, IMS AccessForAll Meta-data Information Model
AccMDBinding, IMS AccessForAll Meta-data XML Binding
AccMDBPG, IMS AccessForAll Meta-data Best Practice Guide
AGLS,AGLS Metadata Standard, Standards Australia 5044
AJAX,Asynchronous JavaScript and XML http://www.ajax.org/
Alt-i-lab2005 http://www.imsglobal.org/altilab
APH,American Printing House for the Blind http://www.aph.org/louis.htm
APLR,CEN APLR, http://www.cen-aplr.org
ATAG,Jutta Treviranus, J., McCathieNevile, C., Jacobs, I., & Richards, J.,(Eds), (2000). Authoring Tool Accessibility Guidelines 1.0
ATAGWG http://www.w3.org/TR/WAI-AUTOOLS/
ATRC,Adaptive Technology Resource Center http://atrc.utoronto.ca/
AVCCThe Australian Vice-Chancellors' Committee http://www.avcc.edu.au/
Babelfishhttp://www.babelfish.org/
BrowseAloudhttp://www.browsealoud.com/
CanCorehttp://www.cancore.ca/
CC/PP,World Wide Web Consortium's Composite Capabilities and Personal Preferencesspecifications http://www.w3.org/Mobile/CCPP/
CEN/ISSSLearning Technologies Workshop
CNIB,Canadian National Institute for the Blind
Cornelluniversity Library
CSS,Cascading Style Sheets http://www.w3.org/TR/REC-CSS2/
CWISInternet Scout http://scout.wisc.edu/Projects/CWIS/
DCMI,Dublin Core Metadata Initiative http://dublincore.org/
DCMIAccess, Dublin Core Metadata Initiative Accessibility Working Group
DCMITerms, Dublin Core Metadata Initiative Terms
DCMIDCAM, Dublin Core Abstract Model,
DDS,Dewey Decimal Classification System, http://www.oclc.org/dewey/
del.icio.ushttp://del.icio.us/
digghttp://digg.com
DRC,Disability Rights Commission (UK) http://www.drc-gb.org/
DRD,ISO standard for Digital Resource Description (FCD 24751-3, IndividualizedAdaptability and Accessibility in E-learning, Education and Training Part 3:Access For All Digital Resource Description online at
EARLhttp://www.w3.org/TR/EARL10-Schema/
EdNA,Educational Network of Australia http://www.edna.edu.au/
EduSpecshttp://eduspecs.ic.gc.ca/
FLICKRhttp://www.flickr.com/
FluidDrag-and-Drop
FRBRFunctional Requirements for Bibliographic Records Final Report.
GEMGateway to Educational Materials
Googlehttp://www.Google.com
GoogleDesktop http://desktop.google.com/
GoogleSimilar Pages http://www.googleguide.com/similar_pages.html
HFI,Human Factors International http://www.humanfactors.com/
HREOC,Human Resources Equal Opportunity Commission of the Australian FederalGovernment http://www.hreoc.gov.au/
HTML4.01, HyperText Markup Language. Raggett, D., Le Hors, & A., Jacobs, I.,(Eds), (1999). HTML 4.01 Specification http://www.w3.org/TR/html4/
HTTP,Hypertext Transfer Protocol -- HTTP/1.1. R. Fielding, R., Gettys, J., Mogul,J., Frystyk, H., Masinter, L., Leach, P., & Berners-Lee, T., (Eds), (1999).http://tools.ietf.org/html/rfc2616
Hyperlecture
IEEE14.84.12.1 - 2002 Standard for Learning Object Metadata:
IEEE/LOM,IEEE Learning Technology Standards Committee .
IMSAccessibility http://www.imsglobal.org/accessibility/
IMSAccLIP, IMS Learner Information Package Accessibility for LIP
IMSAccMD, IMS AccessForAll Meta-data Specification
IMSAG, IMS Accessibility Guidelines for Education
IMSGLC, IMS Global Learning Consortium http://www.imsglobal.org/
INCITSV2 community http://v2.incits.org/
InclusionUK http://inclusion.uwe.ac.uk/
InternationalAcademy of Digital Arts and Sciences http://www.iadas.net/
ISOcoordinate ref system see http://www.isotc211.org/
ISO2788 standard (
ISO/IECJTC1 SC36 http://jtc1sc36.org/
ISO/IECJTC1 SC35 WG8 User Interfaces for Remote Interaction
LMSAngel http://www.angellearning.com/
MMI-DC,European Committee for Standardization Meta-Data (Dublin Core) Workshop
Macromediaoriginally http://www.macromedia.com/software/now Adobe and at http://www.adobe.com/products/
MathML,Mathematics Markup Language http://www.w3.org/Math/
METS,Metadata Encoding and Transmission Standard,
MRCUNC, Metadata Research Center, University of North Carolina at Chapel Hill
MRPUCB, Metadata Research Program (formerly OASIS), University of California,Berkeley http://metadata.sims.berkeley.edu/index.html
NCD,US National Council on Disability http://www.ncd.gov/
NLS,National Library Service for the Blind and Physically Handicapped, Library ofCongress http://lcweb.loc.gov/nls/
NIST,National Institute of Standards and Technology http://www.nist.gov/
OAI,Open Archives Initiative http://www.openarchives.org/
OCLC,Online Computer Library Center http://www.oclc.org
Ontopiahttp://www.ontopia.net/omnigator/models/index.jsp
OpenUniversity, UK, http://www.open.ac.uk/
OZeWAI2004 Conference http://www.OZeWAI.org/2004/
OZeWAI2004 Conference http://www.OZeWAI.org/2007/
PDF,Portable Document Format
PNP,ISO standard text of FCD 24751-2, Individualized Adaptability and Accessibilityin E-learning,
Education and Training Part 2: Access For All Personal Needs and PreferencesStatement http://jtc1sc36.org/doc/36N1140.pdf
POWDER,http://www.w3.org/2007/powder/
RDF,Resource Description Framework. http://www.w3.org/RDF/
RNIB,Royal national Institute for the Blind. http://www.rnib.org.uk/
RSS,Really Simple Syndication or RDF Site Summary,
s.508Rehab Act .....
SAKAI,SAKAI Collaboration and Learning Environment for Education
SALT,Specifications for Accessible Learning Technologies
SC36,ISO JTC1 SC36, Learning, Education and Training standards
SGMLStandard Generalized Markup Language ISO 8879
SMILSynchronised Multimedia Integration Language
STEVEMuseum http://www.steve.museum/
STSNSpeech-to-Text Services Network http://www.stsn.org/
SVG,World Wide Web Consortium's Scalar Vector Graphics
SVGCapability
SWAP,Smart Web Accessibility Platform http://www.ubaccess.com/swap.html
SWG-A,ISO/IEC JTC1 SWG-A http://www.jtc1access.org/
TBPTalboks-och Punktskrift Biblioteket, Sweden http://www.tpb.se/
testlabis a european http://www.svb.nl/project/testlab/testlab.htm
TextHelpSystems Inc. http://www.texthelp.com/
TheLibrary of Congress National Library Service for the Blind and PhysicallyHandicapped (NLS). The Union Catalogue (BPHP) and the file of In-ProcessPublications (BPHI) can both be searched via the NLS website (see
TILE,The Inclusive Learning Exchange http://www.barrierfree.ca/tile/
TopicMaps http://www.topicmaps.org/
TRACEhttp://www.trace.wisc.edu
UAAG,World Wide Web Consortium WAI's User Agent Accessibility Guidelines
ubAccesshttp://www.ubaccess.com/
UML,Unified Modeling Language http://www.uml.org/
UNEnable http://www.un.org/disabilities/
Universityof Toronto, http://www.utoronto.ca/
URI,Universal Resource Identifier http://labs.apache.org/webarch/uri/
VISUCAThttp://www.cnib.ca/library/visunet/
W3C,World Wide Web Consortium, http://www.w3c.org/
WAI,World Wide Web Consortium's Web Accessibility Initiative
WAI-AGEhttp://www.w3.org/WAI/WAI-AGE/
WGAC,Chisholm, W., Vanderheiden, G. and Jacobs, I. (1999). Web Content AccessibilityGuidelines Version 1.0 http://www.w3.org/TR/WAI-WEBCONTENT/
WCAG-2Web Content Accessibility Guidelines Version 2.0 Caldwell, B., Chisholm, W.,Vanderheiden, G. and White, J. (2004). http://www.w3.org/TR/WCAG20/
WCAGWG http://www.w3.org/WAI/GL/
Web-4-Allhttp://web4all.ca/
WGBH/NCAM,The Carl and Ruth Shapiro Family National Center for Accessible Media
Webbyaward winners http://www.webbyawards.com/
WG7,Working Group 7 of ISO JTC1 SC36, Learning, Education and Training
WSG,Web Standards Group http://webstandardsgroup.org/
WSISWorld Summit on the Information Society http://www.itu.int/wsis/
XML,World Wide Web Consortium's Extensible Markup Language (
Glossary of terms
accessibility
a successful matching of information and communications toa user's needs and preferences to enable the user to interact with and perceivethe intellectual content of the information or communications. This includesbeing able to use whatever assistive technologies or devices that arereasonably involved in the situation and that conform to suitably chosenstandards.
disabilities
people with ...
inclusive
doing what is reasonably required to ensure accessibilityfor the maximum number of people individually
'metadata' from ... 1.3 of AGLS Metadata revision ofusage guide....(check email from SA and Agnes)
“Metadata is just a new term for something that has beenaround for as long as humans have been writing. It is the Internet-age term forinformation that librarians traditionally have put into catalogues andarchivists into archival control systems. The term ‘meta’ comes from a Greekword that denotes ‘alongside, with, after, next’. More recent Latin and Englishusage would employ ‘meta’ to denote something transcendental, or beyond nature.Metadata, then, can be thought of as data about other data. Although there aremany varied uses for metadata, the term is commonly used to refer todescriptive information about online resources, generally called ‘resourcediscovery metadata’.
Resource discovery metadata is information in a structuredformat that describes a resource or a collection of resources. A metadatarecord, then, consists of a set of properties, or elements, which characteriseresources and which are used to describe a resource. For example, a metadatasystem common in libraries – the library catalogue – contains a setof metadata records with elements that describe a book or other library item:author, title, date of creation or publication, subject coverage, and the callnumber specifying location of the item on the shelf.”
resources
things that incl services and objects,
the Web
digital information and communication - includinginformation that points or provides pointers to non-digital information
United Nations Convention for People withDisabilities, Article 2 Definitions
“For the purposes of the present Convention:
"Communication" includes languages, display oftext, Braille, tactile communication, large print, accessible multimedia aswell as written, audio, plain-language, human-reader and augmentative andalternative modes, means and formats of communication, including accessibleinformation and communication technology;
"Language" includes spoken and signed languagesand other forms of non spoken languages;
"Discrimination on the basis of disability" meansany distinction, exclusion or restriction on the basis of disability which hasthe purpose or effect of impairing or nullifying the recognition, enjoyment orexercise, on an equal basis with others, of all human rights and fundamentalfreedoms in the political, economic, social, cultural, civil or any otherfield. It includes all forms of discrimination, including denial of reasonableaccommodation;
"Reasonable accommodation" means necessary andappropriate modification and adjustments not imposing a disproportionate orundue burden, where needed in a particular case, to ensure to persons withdisabilities the enjoyment or exercise on an equal basis with others of allhuman rights and fundamental freedoms;
"Universal design" means the design of products,environments, programmes and services to be usable by all people, to thegreatest extent possible, without the need for adaptation or specializeddesign. "Universal design" shall not exclude assistive devices forparticular groups of persons with disabilities where this is needed.” (
RelevantAccessibility Organisations
While there are many organisations related to accessibility,too many to even name, there are some organisations that have played asignificant role in shaping the Web since its inception. Some of these will beidentified here as they usually also provide many online resources and anyunderstanding of the 'literature' of accessibility of the Web or metadatarelating to it necessarily relies on familiarity with the work of theseorganisations.
WAI
W3C's approach has evolved over time but it is currentlyunderstood as promoting 'universal design'. This idea was fundamentalto WCAG 1.0 and is maintained for the forthcoming (WCAG 2.0) guidelines for thecreation of content for the Web. WCAG is complemented by guidelines forauthoring tools that reinforce the principles in the content guidelines and W3Calso offers guidelines for browser developers. Significantly, the guidelinesare also implemented by W3C in its own work via the Protocols and FormatsWorking Group who monitor all W3C developments from an accessibilityperspective.
W3C entered the accessibility field at the instigation ofits director and especially the W3C lead for Society and Technology at thetime, Professor James Miller, shortly after the Web started to take asignificant place in the information world. W3C established a new activityknown as the Web Accessibility Initiative with funding from internationalsources. From the beginning, although W3C is essentially a members' consortium,in the case of the WAI, all activities are undertaken openly (all mailing listsetc are open to the public all the time) and experts depend upon input frommany sources for their work.
The W3C/WAI activity has done more than develop standardsover the years through its fairly aggressive outreach program. It publishes arange of materials that aim to help those concerned with accessibility to workon accessibility in their context.
TRACE
The TraceResearch & Development Center is a part of the College of Engineering,University of Wisconsin-Madison. Founded in 1971, Trace has been a pioneer inthe field of technology and disability.
Trace CenterMission Statement:
To preventthe barriers and capitalize on the opportunities presented by current andemerging information and telecommunication technologies, in order to create aworld that is as accessible and usable as possible for as many people aspossible. ...
Tracedeveloped the first set of accessibility guidelines for Web content, as well asthe Unified Web Access Guidelines, which became the basis for the World WideWeb Consortium's Web Content Accessibility Guidelines 1.0 [
Wendy Chisholm, who originally worked at TRACE was aleading staff member of WAI for many years and author of a number of theaccessibility guidelines and other documents.
ATRC
The Adaptive Technology Resource Centre is at theUniversity of Toronto. It advances information technology that is accessible toall through research, development, education, proactive design consultation anddirect service. The Director of ATRC, Professor Jutta Treviranus, has beensignificant in the standards work in many fora and the group has contributedthe main work on the ATAG. They are also largely responsible for initiating thework for the AccessForAll approach to accessibility and the technicaldevelopment associated with it.
WGBH/NCAM
The Carl and Ruth Shapiro Family National Center for AccessibleMedia is part of the WGBH, one of the bigger public broadcast media companiesin the USA. Henry Becton, Jr., President of WGBH, is quoted on the WGBH Website as saying that:
WGBHproductions are seen and heard across the United States and Canada. In fact, weproduce more of the PBS prime-time and Web lineup than any other station. Homevideo and podcasts, teaching tools for schools and home-schooling, services forpeople with hearing or vision impairments ... we're always looking for new waysto serve you! (WGBH About,2007)
With respect to people with disabilities, the site offersthe following:
People whoare deaf, hard-of-hearing, blind, or visually impaired like to watch televisionas much as anyone else. It just wasn't all that useful for them ... until WGBHinvented TV captioning and video descriptions.
Public television was first to open these doors. WGBH is working to bring mediaaccess to all of television, as well as to the Web, movie theaters, and more (
NCAM is a major vehicle for these activities within themedia context and its Research Director, Madeleine Rothberg, has been asignificant researcher and author in the work that supports AccessForAll in arange of such contexts.
Relevant Accessibility StandardsOrganisations
In addition to organisations that have been involved in theresearch and development that have led to the AccessForAll approach and standards,there have been the standards bodies themselves that have not only publishedstandards but also initiated work that has made the standards' developmentpossible. In many cases, standards are determined by 'standards' bodies thatare, as in the case of the International Organisation for Standardization [
W3C's role in the standards world is often described as differentfrom, say, the role of ISO because of the structure of the organisation andalso the processes used to develop specifications for recommendation (de factostandards). W3C membership is open to any organisation and tiered so thatlarger more financial organisations contribute a lot more funding than smalleror not-for-profit ones. The work processes are defined by the W3C so thatworking groups are open and consult widely and prepare documents which arevoted on by members and then recommended, or otherwise, by the Director of theW3C, Sir Tim Berners-Lee. They are published as recommendations but usuallyreferred to as standards and certainly, in the case of the accessibilityguidelines, are de facto standards. In many countries, including Australia,they have been adopted into local laws in one way or another.
ISO
ISO collaborates with its partners, the InternationalElectrotechnical Commission [IEC] and theInternational Telecommunication Union [ITU-T],particularly in the field of information and communication technologyinternational standardization.
ISO makes clear on their Web site, that it is
a globalnetwork that identifies what International Standards are required by business,government and society, develops them in partnership with the sectors that willput them to use, adopts them by transparent procedures based on national inputand delivers them to be implemented worldwide (
ISO federates 157 national standards bodies from around theworld. ISO members appoint national delegations to standards committees. In all,there are some 50,000 experts contributing annually to the work of theOrganization. When ISO International Standards are published, they areavailable to be adopted as national standards by ISO members and translatedinto a range of languages.
The Joint Technical Committee 1 of ISO/IEC is forstandardization in the field of information technology. At the beginning ofApril 2007, it had 2068 published ISO standards related to the TechnicalCommittee and its Sub-Committees; 2068; 538 published ISO standards under itsdirect responsibility; 31 participating countries; 44 observer countries; atleast 14 other ISO and IEC committees and at least 22 internationalorganizations in liaison (
JTC1 SC36 WG7 is the working group for Culture, Languageand Human-functioning Activities within the Sub-Committee 36 for IT forLearning Education and Training. It is this working group that has developedthe AccessForAll standards for ISO. Co-editors for these standards come fromAustralia (Liddy Nevile), Canada (Jutta Treviranus) and the United Kingdom(Andy Heath), but there have been major contributions from others in the form ofreviews, suggestions, and discussion and support.
IMS
The IMS Global Learning Consortium [
A joint project between WGBH/NCAM and IMS initiated thework on AccessForAll with a Specifications for Accessible Learning Technologies(SALT) Grant in December 2000. Anastasia Cheetham, Andy Heath, JuttaTreviranus, Liddy Nevile, Madeleine Rothberg, Martyn Cooper and David Wienkaufwere particularly prominent in this work.
DCMI
The Web site describes the Dublin Core Metadata Initiativeas
an openorganization engaged in the development of interoperable online metadatastandards that support a broad range of purposes and business models. DCMI'sactivities include work on architecture and modeling, discussions andcollaborative work in DCMI Communities and DCMI Task Groups, annual conferencesand workshops, standards liaison, and educational efforts to promote widespreadacceptance of metadata standards and practices (DCMI,2007).
The DCMI Accessibility Community has been working formallyon Dublin Core metadata for accessibility purposes since 2001. While the earlywork focused on how metadata might be used to make explicit the characteristicsof resources as they related to the W3C WCAG, this goal has been realised inthe AccessForAll work. The DCMI Accessibility Community has been working inclose collaboration with the IMS and ISO efforts but it has engaged themetadata community, and therefore those working primarily in a wider contextthan education, especially including government and libraries. The author hasbeen chairperson of the DCMI Accessibility community since its inception.
CEN
The European Committee for Standardization, was founded in1961 by the national standards bodies in the European Economic Community andEuropean Free Trade Association countries. CEN is a forum for the developmentof voluntary technical standards to promote free trade, the safety of workersand consumers, interoperability of networks, environmental protection,exploitation of research and development programmes, and public procurement (
A number of CEN committees have been involved in thedevelopment of AccessForAll, either in the form of contributed funding as forthe MMI-DC, or in their independent review of the development of AccessForAlland how it will work in their context if it is adopted by the other standardsbodies. Significant in this work have been Martyn Cooper, Martin Ford, AndyHeath, and Liddy Nevile who have all worked on CEN projects in recent years.The context for this work has included but not been limited to education.
Cancore, CETIS,AGLS, etc
There are a number of other standards bodies or regionalassociations that have considered the work in depth and contributed in someway. In fact, in early 2007, IMS versions of the specifications had beendownloaded 28,082 times and the related guidelines more than 176,505 times.(Rothberg, 2007) CanCore has published the CanCore Guidelines for the"Access for All" Digital Resource Description Metadata Elements (
The Centre for Educational Technology and InteroperabilityStandards [CETIS] in the UK provides anational research and development service to UK Higher and Post-16 Educationsectors, funded by the Joint Information Systems Committee. CETIS has publishedsome summary documents about the
Chapter 1: Preamble
Introduction
The [UnitedNations] Convention on the Rights of Persons with Disabilities and its OptionalProtocol were adopted by the United Nations General Assembly on 13 December2006, and opened for signature on 30 March 2007. On 30 March, 81 Member Statesand the European Community signed the Convention, the highest number ofsignatures of any human rights convention on its opening day. 44 Member Statessigned the Optional Protocol, and 1 Member State ratified the Convention. TheConvention was negotiated during eight sessions of an Ad Hoc Committee of theGeneral Assembly from 2002 to 2006, making it the fastest negotiated humanrights treaty. The Convention aims to ensure that persons with disabilitiesenjoy human rights on an equal basis with others [
By March 31, 2008, there were 126 signatories to the UnitedNations Convention, 71 signatories to the Optional Protocol, 18 ratificationsof the Convention and 11 ratifications of the Optional protocol. Australiasigned the Convention but has not ratified it (
The idea that inclusive treatment of people eliminates theneed for special considerations for people with disabilities is at the heart ofthe research reported in this thesis. It is derived from what has been definedas the social model of disability (
The social model of disability spreads responsibility forinclusion across the community. This research aims to enable continuous,distributed, community effort to make the World Wide Web inclusive.
For a decade, effort to make the Web accessible has focusedon following, or otherwise, a set of guidelines that have come to be treated asspecifications. These guidelines have been proven inadequate to ensureaccessibility for all, because the universal accessibility model on which theydepend is flawed. Recent estimates of the accessibility of the Web are as lowas 3% (
If a user is blind, eyes-busy or using a small screen,instructions about how to get from one place to another presented as a map maybe incapable of perception while a text version that can be read out and heardwould be perceptible. Providing a text description of travel routes is anexample of an accessibility improvement for a map. Managing the map and the newversion so that it is associated with the map, and discoverable at the sametime as the map, is what catalogue records or metadata can do for digitalobjects.
The research advocates a process to support ongoingincremental improvement of accessibility. This depends upon efficientmanagement and description of distributed resources and their improvements, anddescriptions of them, so they can be matched to people's individual needs andpreferences. The research elaborates what is called AccessForAll metadata (
The research distinguishes the context in which earlieraccessibility work took place. In what might be thought of as a ‘Web 1.0’environment, one-way publishing was the dominant activity. In the current ‘Web2.0’ environment, interactive publication happens across the Web inunpredictable ways, despite authors and publishers who provide well-structured,cohesive Web sites. Most people are learning to 'Google' and approachinformation from a range of perspectives and directions, often coming intoresources through what is effectively a back door, and taking from resourceswhat is of interest but disregarding or discarding the rest. The research alsorelies upon the interactivity and energy available from what is known as socialnetworking that is occurring within the Web 2.0 environment (
The research is not limited to classic 'Web pages', butincludes access to all resources, including services, that are digitallyaddressed. AccessForAll metadata already describes digital resources and isbeing extended to describe a wider range of objects including events and places(ISO/IEC JTCISC 36, 2008). Descriptions of the accessibility of those physical placesand events will be Web addressable, so the access to those places will be 'onthe Web'.
Background
The United Nations publishes a map (Figure 1) that showsinvolvement in the United Nations (UN) Convention for the Rights of People withDisabilities. As of June 2008, more than eighteen months after the Conventionwas adopted by the UN, Australia had only signed the convention but notratified it. Unless it is ratified by the Australian government, it has nolegal status in Australia. On the other hand, Australians have been involvedfor many years in international efforts with W3C,ISO, IMSGLC, CEN, and others to ensure thatinformation technology and digital resources are accessible to everyone. Theyhave actively participated in the work of the World Wide Web Consortium [
The recentUnited Nations convention on the rights of people with disabilities clearlystates that accessibility is a matter of human rights. In the 21st century, itwill be increasingly difficult to conceive of achieving rights of access toeducation, employment health care and equal opportunities without ensuringaccessible technology (
Making the Web accessible to everyone has proven moredifficult than anticipated. While Roe (
At theMuseums and the Web 2006 conference, one word had the power to abruptly silencea lively discussion among multimedia developers: accessibility. When the topicwas introduced during lunchtime conversation to a table of museum webdesigners, the initial silence was followed by a flurry of defensivecomplaints. Many pointed out that the lack of knowledgeable staff and fundingresources prevented their museum from addressing the “special” needs of theonline disabled community beyond alternative-text descriptions. Others fearedthat embracing accessibility in multimedia meant greater restrictions on theircreativity. A few brave designers admitted they do not pay attention to theguidelines for accessibility because the Web Content Accessibility Guidelines(WCAG) 1.0 standards are dense with incomprehensible technical specificationsthat do not apply to their media design efforts. Most importantly, only oneinstitution had an accessibility policy in place that mandated a minimum levelof access for online disabled visitors. Conversations with developers ofmultimedia for museums about accessibility were equally restrained. Developersfrequently blamed the authoring tools for the lack of support for accessiblemultimedia development. Other vendors simply dismissed the subject or admittedtheir lack of knowledge of the topic. Only one developer asked for advice onhow to improve the accessibility of their learning applications (
Roe (
About 15% ofEuropeans report difficulties performing daily life activities due to some formof disability. With the demographic change towards an ageing population, thisfigure will significantly increase in the coming years. Older people are oftenconfronted with multiple minor disabilities which can prevent them fromenjoying the benefits that technology offers. As a result, people withdisabilities are one of the largest groups at risk of exclusion within theInformation Society in Europe.
It isestimated that only 10% of persons over 65 years of age use internet comparedwith 65% of people aged between 16-24. This restricts their possibilities ofbuying cheaper products, booking trips on line or having access to relevantinformation, including social and health services. Furthermore, accessibilitybarriers in products and devices prevents older people and people withdisabilities from fully enjoying digital TV, using mobile phones and accessingremote services having a direct impact in the quality of their daily lives.
Moreover,the employment rate of people with disabilities is 20% lower than the averagepopulation. Accessible technologies can play a key role in improving thissituation, making the difference for individuals with disabilities betweenbeing unemployed and enjoying full employment between being a tax payer orrecipient of social benefits (
People with disabilities who are alienated byinaccessibility are regarded by Australian law (HREOC, 2002) as discriminatedagainst. They are able to claim damages from those who discriminate againstthem if all relevant conditions are satisfied. This means Australia recognizesa general right. It is, therefore, incumbent on a victim to prove, within thelegal system, that they have unreasonably suffered from discrimination.Although such a course has been used, reported cases are rare and, as withother cases likely to provoke negative publicity. Such cases would normally besettled out of court where possible, and so not publicly reported. Such a legalsituation does not operate as a major threat to large organisations, especiallyas so far the damages awarded so far have not been substantial, e.g. Maguire vSydney Organising Committee for the Olympic Games (
Accessibility efforts in many cases aim to make a singleresource universally accessible to everyone.Universal accessibility involves providing the same resource in many forms sothat people with disabilities can use the full range of perceptions to accessit across all platforms, fixed and mobile, standard and adaptive. Universalaccessibility is distinguished from individual accessibility or accessibilityto an individual user. Many resources are individually accessible while notuniversally accessible and many universally accessible resources (as defined bythe standards in use) are not accessible by some individual users (
Reinforcing the disinclination to worry about accessibilityis the common belief that it costs a lot to make resources universallyaccessible (Steenhout,2008). Frequently, it is left to a semi-technical person in a relativelyinsignificant position within an organisation or operation to championaccessibility as best they can. Anecdotally, they frequently report that allwas going well until the resource was about to be released. Then, the marketingmanager or some other more significant participant chose to add a particularfeature and not be constrained by accessibility concerns. (In the 1990's,Nevile was responsible for the accessibility of original design of two majorgovernment portals, the Victorian BetterHealth Channel and the Victorian
Economic factors are, therefore, important in the contextof accessibility. Many believe that accessibility means more expenses whenresources are being developed and more resources being supplied to the range ofusers of those resources. It is true that making an inaccessible resource accessiblecan take considerable effort, expertise and expense and, even then, is notalways possible. On the other hand, some publishers are finding that by makingaccessibility a priority, they actually gain financially through cost savings (
Practicality is important. It has long been known that itis not always possible to make an inaccessible resource accessible withouthaving to compromise some of the characteristics of the resource, depending onwhat sort of resource it is. If designers provide an attractive 'look and feel'for a Web site, for example, it may not be possible to have exactly that lookand satisfy all the accessibility specifications. Additionally, those who areexperts in accessibility are not usually designers but more often technicalpeople. In practice, a designer who works within the accessibility constraints isable to design creatively and avoid the accessibility pitfalls.
One common reason that resources are not accessible is thatthey are dependent on a software application that does not render the content,or does not control or display the content in ways that make it accessible toeveryone. Many people with disabilities use specialised equipment or softwareto gain access to content. Many people use mobile phones, and others usescreens with content projected on to them, or printers, or old computers. Sometimesthe content creator takes the end user into account. Unfortunately, this oftenmeans they arbitrarily anticipate, for example, that it will be printed onlocal-standard sized paper, in which case they fix the electronic version ofthe resource to match the way they expect it to appear on paper. This does notalways work for the paper version because the local standards differ. Neitherdoes it work for the digital version of the resource because rarely are screensizes or windows appropriate for this. In cases where users have unusual needsor preferences, such as a need to change the font size or reverse the coloursof the background and foreground. it is unlikely the necessary changes can bemade. It is possible, however, where the digital version of the fixed printversion is very well encoded for accessibility,. The World Wide Web Consortium[W3C] has developed a technology that allowsa single resource to be presented in a variety of ways, depending on the medium,and explicitly for the user to have one form of presentation that overrides anymade available by the publisher of the resource or the browser software [
Many think of the Web as 'homepages' or Web sites. This isnot sufficient. A Web page may contain links to documents that reside indatabases, open or closed, and those 'documents' might be simply someapplication-free content, or they might be complex combinations of multimediaobjects, even dynamically assembled for the individual user, locked intospecific applications. The Web Accessibility Initiative [
The WAI set of guidelines, originally three for authoringtools, users agents and content [WebContent Accessibility Guidelines, WCAG], have been in constant developmentor revision for more than a decade (Chapter 4).They have been adopted in many countries and used by developers all around theworld. Despite this incredible effort, the Web is far from accessible toeveryone (Chapters 3,
In recent years, total dependence on the WAI work and itsderivatives (such as s. 508 that wasadded to the US Disabilities Discrimination Act [
In 2008, more and more such services are emerging. What issignificant is not simply their number. It is that they represent a significantshift in thinking about accessibility. If resources are not going to be createduniversally accessible, or found in a universally accessible form, and it isunlikely there will be a significant change in this situation, it makes senseto think more about what can be done post-production.
Post-production techniques were a feature of the
Going a little further, the
An outdated view of accessibilityand the Web
The original use of the World Wide Web was to enable a fewpeople scattered around the world to work together on shared files located ontheir own computers, to make them discoverable using a Uniform/UniversalResource Identifier [URI],and to access them using the HyperText Transfer Protocol [
The research establishes that the dominant model ofaccessibility work is still grounded in the early Web, a network of staticdocuments that may be updated but are usually from a single source. In thisthesis, the term Web 1.0 is used to designate the Web as it was commonly usedin its first decade (1995-2005). O'Reilly (
Web 1.0 work assumes editorial control over publishing,even where the authors come from a single organisation and this task isundertaken by a number of people. In such cases, in fact, many organisationsimpose both style guides (or the equivalent) on the authors and/or providetemplates within which those authors have constrained scope for their content.In such circumstances, it might be possible to force adherence to certain stylestandards, as it was in the earlier days when documents to be printed wereencoded in Standard Generalized Markup Language [
A side-effect of Web 1.0 work is that many people still donot recognise that they can use standard Web pages and Web authoring tools, inalmost exactly the same way as they use non-standardised proprietary officetools, including to format, print, exchange and manage other documents. Manypeople are still using office tools that do not take advantage of theaccessibility possible with available technologies. Organisations in whichproprietary office tools are used form sub-cultures around those tools, andparticipants develop materials (resources) that suit the particular softwaretools. They are often not aware that their single resources could be as easilycreated and managed but far more flexible and interoperable not only betweensoftware systems, but also across ranges of modalities (on paper, on individualscreens, as presentations on large screens, read aloud, etc.). Proprietaryinterests and competition have encouraged proprietary developers to distinguishtheir software by adding features often regardless of the inaccessibilitysimultaneously introduced by those features (Nevile, personal observations).
At the time of writing, there is a worldwide debate on thewisdom of adopting the Microsoft specification Office Open XML as anInternational Standards Organisation [ISO]standard for documents. One reason is the problem of accessibility that mayflow from that decision (
The research establishes that the historic view ofaccessibility is no longer effective. The complexity of satisfying the originalguidelines is shown to be out of the range of most developers. There are toomany techniques involved; they are not explicit; they cannot always be testedwith certainty; they do not completely cover even chosen use cases and are notintended to cover all user requirements; they are contradictory in some cases;they have not been applied systematically, and anyway, they do not apply to allpotential information and communications. All of these claims are documented inthis thesis.
A new approach to accessibility foran updated Web
This thesis is not alone in making the claims above: thereare many authors and developers both writing and acting; some people havestarted work on post-production and even post-delivery reparation of resourceslacking in accessibility, and others are proposing new ways of thinking aboutaccessibility. Their work is considered in detail in the research.
What this thesis offers is an argument in favour of anon-going process approach to accessibility of resources that supportscontinuous improvement of any given resource, not necessarily by the author ofthe resource, and not necessarily by design or with knowledge of the originalresource, or by contributors who may be distributed globally. It argues thatthe current dependence on production guidelines and post-production evaluationof resources as either universally accessible or otherwise, does notadequately provide for either the accessibility necessary for individuals orthe continuous or evolutionary approach possible within what is defined as aWeb 2.0 environment. It argues that a distributed, social-networking view ofthe Web as interactive, combined with a social model of disability, given themanagement tools of machine-readable, interoperable AccessForAll metadata, asdeveloped, can support continuous improvement of the accessibility of the Webwith less effort on the part of individual developers and better results forindividual users.
As outlined above, there are a number of ways to makeresources accessible. Relying solely on authors to 'do the right thing' byfollowing the universal accessibility approach has generally failed to makeresources universally accessible (Chapter 4)but many resources are nevertheless suitable for individual users, if only theycan find them. Similarly, most resources that are universally accessible arenot discoverable as such.
In Europe, there have been moves to apply metadata toresources (to catalogue them) that declare their accessibility in terms ofconformance with various available specifications: the UK government hasmandated certain provisions (
Metadata that merely identifies resources that have beenmarked as accessible is not particularly reliable and anyway, as is shown below(Chapter 4), conformance with thebest-known guidelines does not necessarily mean a resource is universallyaccessible. Certainly, such metadata does not say if the resource is optimisedfor any particular individual user seeking it. More specific metadata isrequired if it is to be useful to the individual user. This has been recognisedby the authors of the WCAG guidelines and there is provision in the forthcomingversion of WCAG for metadata as a result of the AccessForAll work (
If resources are to be made more accessiblepost-production, they will need to be discoverable prior to being delivered andfound to be inaccessible and any missing or supplementary components, orservices to adapt them, will also need to be discovered. Resource descriptions,like catalogue records, can usefully contin descriptions of the accessibilitycharacteristics of resources without any need for declaring if the resource isor is not universally accessible. Such a description is known as AccessForAllmetadata and discussed in detail below (Chapter7). AccessForAll metadata has been adopted by four major standards bodies.First, the IMS Global Learning Consortium [IMSGLC] for the education sector. Then the Joint Technical Committee of theInternational Organisation for Standardization/International ElectrotechnicalCommission. Its, Sub-Committee 36, [ISO/IEC JTC1SC36], adopted it again for the education sector. The Dublin Core MetadataInitiative [DCMI] is adopting it forgeneral metadata, for all sectors, and most recently, Standards Australia hasadopted if for the AGLS Metadata Standard [AGLS],for all Australian resources.
This thesis describes the background, theories, design anddevelopment of the metadata, as documented in the various published orforthcoming standards, and work associated with its adoption by variousstakeholders.
In addition to metadata that describes the accessibilitycharacteristics of resources, it is necessary to define metadata to describethe accessibility needs and preferences of users. 'AccessForAll' metadata isbest used to match resources to users' needs and preferences, automaticallywhere possible. Determining how such a match might be achieved in a distributedenvironment is a continuing interest of the author and colleagues in Japan,especially in as much as it relates to the use of the Functional Requirementsfor Bibliographic Records [FRBR],OpenURI (
Usability is well established as a criterion for theutility of a resource (Nielsen, 2008). Aflexible approach including usability in a loose sort of 'tangram' model couldsignificantly improve the Web's accessibility (
Jakob Nielsen useit.com: Jakob Nielsen'sWebsite “Understanding and significance of accessibility”
Understanding accessibility is not easy given the hugenumber of different contexts and requirements possible. In addition, there aremany definitions.
For the purposes of the research, accessibility is definedas a successful matching of information and communications to an individualuser's needs and preferences to enable that user to interact with and perceivethe intellectual content of the information or communications. Thisincludes being able to use whatever assistive technologies or devices arereasonably involved in the situation and that conform to suitably chosenstandards. Explanations of the more detailed characteristics of accessibilityare considered in Chapter 3.
The literature reveals two significant things: a currentcommon approach to accessibility that is significantly reliant on universalaccessibility, as promoted by the World Wide Web Consortium [
Almost onein five Australians has a disability, and the proportion is growing. The fulland independent participation by people with disabilities in web-basedcommunication and information delivery makes good business and marketing sense,as well as being consistent with our society's obligations to removediscrimination and promote human rights. (
In 2005, estimates of accessibility were as low as 3% (
Microsoft Corporation commissioned research that suggeststhe benefits of accessibility will be enjoyed by 64% of all Web users (
Brian Kelly (
What wecan’t say is that the Web sites which fail the automated tests are necessarilyinaccessible to people with disabilities. And we also can’t say that the Websites which pass the automated tests are necessarily accessible to people withdisabilities.
The lack ofaccessibility solutions leads to the need for a new, comprehensive process foraccessibility that includes the use of metadata to facilitate discovery anddelivery of digital resources that are accessible to individuals according totheir particular needs and preferences at the time of delivery. When a user hasa constraint that renders information inaccessible to them, they are deemed tohave a need, such as when a highly mobile person using a telephone cannot use asmall scale map because it cannot be displayed on their tiny low-resolutionscreen or a blind person requires Braille. User preferences are less crucialresponses to constraints for the individual user. It should be noted that someusers have very specific needs that must be satisfied whereas other users maybe satisfied by any from a range of preferences.
AccessForAll philosophy
The more information is mapped and rendered discoverable,not only by subject but also by accessibility criteria, the more easily andfrequently inaccessible information for the individual user can be replaced oraugmented by information that is accessible to them. This, in turn, means lessdamage when an individual author or publisher of information fails to maketheir information accessible. This is important because, as is shown (see
Widespread-mapping of information depends upon theinteroperability of individual mappings or, in another dimension, the potentialfor combining distributed information maps in a single search source. Theancient technique of creating atlases from a collection of maps is exemplary inthis sense (
Atlases would not be useful if every map were developedaccording to different forms of representation; the standardisation ofrepresentations enables the accumulation of maps to form the universal atlas.In the same way, the widespread mapping of accessible resources on the Web isachieved by the use of a common form of representation so that searches can beperformed across collections of resources. Interoperability is typically saidto function at three levels: structure, syntax and semantics (Weibel, 1997).Nevile & Mason (2005) argue that it does not operate at all unless there isalso system-wide adoption (see Chapter 12).
The AccessForAll team (the AfA team) worked to exploit theuse of metadata in the discovery and construction of digital information in away that could increase Web accessibility on a worldwide scale. The outcome isa set of specifications (now forthcoming as standards) that can be used toenable the production of an atlas of accessible versions ofinformation so that individual users everywhere can find something that willserve their purposes in a way that is independent of their choice of device,location, language and representational form. There are several ways in whichthis work needs to be followed by other work: to enable a similar selection ofuser interface components (see FLUID)and perhaps certification of organisations and systems that provide the newservice, or at least those that enable it by providing useful metadata (see
The AfA work takes advantage of the growing number ofsituations for which metadata is the management tool for digital of objects andservices and of people's needs and preferences with respect to them, so thatresources that are suitable can be discovered by users where they are well-described.AfA philosophy includes, in addition, that resources should be able to bedecomposed and re-formed using metadata to make them accessible to users withvarying devices, locations, languages and representation needs and preferences.Chapter 11 expands on some significant ifnot widespread adoption of this method. AfA metadata can be used immediately tomanage resources within a shared, closed environment such as the original oneestablished at the University of Toronto where the AccessForAll approachoriginated. There is, however, greater potential for it such as to use it in adistributed environment. Exactly how to do this is proving a challenge but theproblem is closely aligned to the problems being considered by W3C's workinggroup developing POWDER (W3C POWDER,2008) and hopefully will soon be overcome.
A metadata approach
In the case of the AccessForAll projects, Nevile has workedon many AccessForAll and other accessibility projects as the metadataresearcher.
BC wants a diagram of input etc here????
In the research, the basic computer science task ofclassification in first normal form (
Metadata research is looking for a means of fixingsemantics within a framework of vocabularies that are not aligned, usingtechnology that is evolving, and looking for appropriate means for declaringthe semantics in interoperable ways. Such research is being performed in a numberof leading universities around the world (MetadataResearch Center, University of North Carolina (MRC UNC);
At the Metadata Research Center, School of Information andLibrary Science, University of North Carolina at Chapel Hill, a number ofprojects for developing metadata for specific domains have been funded andundertaken as research [MRC UNC]. Atypical example is provided by the KEE-MP project:
The goal ofthe Knowledge Exploration Environment for Motion Pictures (KEE-MP) project isto design and develop a prototype web system that will enable aggregation,integration, and exploration of diverse forms of discourse for film.
The mainresearch components of the project are:
·
·
·
Such research does not depend upon standard researchtechniques (see Chapter 2), but nor is itdevelopment in the usual sense. While the direct output may be a prototypeproduct, the research is about metadata. Some of what is learned is inevitablywhat is not supported by metadata as it is used, and how effective the evolvingprinciples are, and what could improve them. It also touches upon theeffectiveness of the evolving principles of technical accessibility developmentand ways to improve it. The work of these projects is demanding and necessarilyinvolves a number of people.
AccessForAll metadata research and development

Metadata research projects, as shown above, often involve amulti-disciplinary team including both developers and researchers. In as muchas the research requires the use of new technologies, and they need to be builtand tested, developers are often essential to the work. In addition, there isusually a need for subject experts, who can contribute not just bareinformation but by advising on the structure of the knowledge of the domain,and how it is used. Finally, it is usually important to have someone who isable to cross-the disciplines, to understand how they interact in thecircumstances.
The Assistive Technology Resource Center [ATRC] at theUniversity of Toronto has a proud record of research and development. In thefield of accessibility, they have significant achievements and, specifically,were leaders in the use of database technologies to adapt resources to users’individual needs, with their product ‘The Inclusive Learning Exchange’ [TILE].
While there is a close connection between databasemanagement of resources and metadata, they are not the same. Databasedevelopers and researchers work on such aspects as the speed with which thedata can be manipulated by an application, the amount of data, etc. Metadataspecialists are customers for this work; their concern is more the semanticvalue of descriptions of the resources so that people, as well as machines, canuse the descriptions. Database specialists think in terms of the needs of thecomputational systems, metadata experts think about the substance of theresources and the discipline and thus its ontological principles. Metadataspecialists do not specialise in the discipline so much as in how to manage itsresources, and often learn this by working in a number of different contexts,and thus abstracting metadata principles that they can bring to bear in newsituations. It is this final activity that forms the research being reported.
TILE is a database application in which certain ‘fields’ orwhat programmers think of as tokens, prompt certain responses from acomputational system. Metadata is the result of an abstraction of such aprocess. Metadata is to do with the underlying model for such databases –how should the database be constructed to group resources, what triggers shouldit respond to, what inputs does it need, and so on. In this context, it can behelpful to think of the abstract work as developing a metadata schema such asthe abstract model for AccessForAll metadata (Chapter7).
In the AccessForAll interdisciplinary metadata team, there havebeen seven major players: Jutta Treviranus, Anastasia Cheetham and DavidWeinberg, in particular, from the Assistive Technology Resource Center [ATRC]at the University of Toronto, Canada (Universityof Toronto, Canada); Madeleine Rothberg from WGBH National Center forAccessible Media in Boston, USA (WGBH/NCAM);Liddy Nevile from La Trobe University, Australia; and Andy Heath from theUniversity of Sheffield (now at the Open University) and Martyn Cooper from theOpen University, United Kingdom (OpenUniversity, UK).
All in the team have been involved in accessibility workfor a number of years but from different perspectives. Nevile is clearly the metadataresearcher in the team, while Cheetham and Weinberg are responsible for thedevelopment of the prototype TILE, Heath is an expert in programming, andRothberg, Treviranus and Cooper are responsible for major accessibilityprojects in education. Treviranus is the outstanding accessibility expert.Treviranus is the Director of the ATRC and a leader in the field of disabilitywork involving technology, Director of the ATRC and its numerous projects, andChair of the W3C Authoring Tools Accessibility Guidelines Working Group [
The AccessForAll work has been undertaken in a number ofcontexts (as explained below) but always with the core team leading theefforts. The group emerged from the work being undertaken by the IMS GlobalLearning Consortium [IMS GLC] when theyadopted the ATRC model, and has moved to other contexts, as explained below.Nevile, the Chair of the DCMI Accessibility Working Group (now theAccessibility Community), is responsible for AccessForAll finding its way intothe DCMI world of metadata and has been responsible for developing theAccessibility Application Profile (or Module) for DCMI and all the schema anddocumentation required for an international technical standard (

Nevile is the primary DC 'metadata' person in theAccessForAll team (Appendix 1 and

AccessForAll metadata research
This thesis argues that metadata is an enabling technology thatshould be central and integral to anyin as much as it provideswhat is the role couldplay inin increasing accessibility.
Research objectives
This research establishes that careful metadata work isessential if metadata is to provide the infrastructure for AccessForAllpractices that can make the Web more accessible. With respect to metadata, theresearch challenges the structure, the syntax and the semantics of theAccessForAll work. It includes:
·
·
·
·
With respect to accessibility, based on estimates of thecurrent accessibility of the Web, the research challenges the theoreticalfoundations of previous work. It adopts a new base to support inclusion and theUN Convention for the Rights of People with Disabilities (
It considers the following questions among others:
1.
2.
3.
4.
5.
6.
7.
The thesis provides the only comprehensive documentation ofthe principles and products that support the AccessForAll metadata approach toaccessibility. The AccessForAll
Timeline of involvement - draft
see dipity timeline here:
See relevant publications Appendix1 and Appendix 2
See description of what I did re accessibility
Summary
In this Preamble, the scene has been set for thesubstantive work that follows. The development of a new way of working on theproblem of accessibility has been shown to be not just a response to the lackof real success with previous methods, but also a response to the changingtechnological context in which this work takes place. Metadata research hasmatured in the last ten years and metadata development has led to the adoptionof it for resource management within digital systems. In addition, earlierunderstanding of disability according to a deficit model has been replaced by asocial inclusive model that avoids distinctions between people with physical orother medical disabilities and the general public, assuming that everyone, attimes, is disabled either by their circumstances or by temporary or permanenthuman impairment.
In the next chapter, many of the components considered inthe research are defined in greater detail and the research is described.
Chapter 2: Introduction
The first decade of internationaleffort to make the Web accessible has not achieved its goal and a differentapproach is needed. In order to be more inclusive, the Web needs publishedresources to be described to enable their tailoring to the needs andpreferences of individual usersand
This thesis asserts that the low level of accessibility ofthe Web justifies a new approach to accessibil
The general aim of work in the accessibility field is tohelp make the information era inclusive. Inclusive is a term used in thiscontext to refer to a particular approach to people with disabilities and tothe disabilities themselves. People with accessibility needs are not homogenousand many of them do not have long-term disabilities: what they need now may notbe of interest to them in different circumstances or at other times. Accessibilityis also a special term in this context, designating a relationship between ahuman (or machine) and an information resource. Both terms are defined in
The research starts with a close examination and analysisof current accessibility processes and tools and moved on to include a newapproach that will complement previous accessibility work and the problem ofhow to develop metadata to support a more process-oriented approach toaccessibility. Co-editing of international specifications and standards foraccessibility metadata, known as AccessForAll (AfA) metadata, was undertakensimultaneously with the research to determine metadata recommendations for aDublin Core Metadata Application Profile module (see
Actively promoting accessibility is taken to mean beinginclusive. The term inclusive is used for operations and organisations thatfollow appropriate practices to promote accessibility of the Web and accommodatemany improvements in a constantly widening range of contexts. The new processwork suggests a 'quality of practice' approach to the process of content andservice production that will support incremental but continuous improvement inthe accessibility of the Web and thus inclusion in the digital information era.
Preliminary, practical definitions
In this section, there are brief introductions to the majorterms and concepts involved
The Web
The UN Convention on the Rights of Persons withDisabilities and its Optional Protocol (
In particular, the Web is not simply thosea pageit
On this very small Web page (Figure ???), there are sixlinks that put the user in contact with other 'pages' as we might call them. Tocontact the Prime Minister, one does not send email that would be easilyaccessible but receives another page with a form on it. The form saves thePrime Minister from receiving email directly from the userbut it also introduces an accessibilityissue; many forms within standard HTML pages are not what is here defined asaccessible.
Links are provided on the Prime Minister's page to threesources of information that explain privacy, copyright and about the site. Onelink directs the user to the archive of the previous pminister'sWeb site. This is a substantial source of information and when contact is made,it reveals files in a range of formats. This archive is provided by theNational Library of Australia and before choosing a version, the user can seemetadata associated with the archive describing the formats of files involved.(Interestingly, the note does not
Only when the 'correct' font size is used is the full notelegible:

Figure ??? shows the range of applications necessary toaccess just what is on the first page of the archive but then, each page ofthat archive is likely to point to yet more resources. All of these resources,the hardware and software needed to use them, form what in the research isdefined to be 'the Web'.
Web 2.0
In 2004, Tim O'Reilly described the Web using a new term thathas since become a model for describing recent versions of evolved productsthat in fact have no formal versions. Later he said of it (
The concept of"Web 2.0" began with a conference brainstorming session betweenO'Reilly and MediaLive International. Dale Dougherty, web pioneer and O'ReillyVP, noted that far from having "crashed", the web was more importantthan ever, with exciting new applications and sites popping up with surprisingregularity. What's more, the companies that had survived the collapse seemed tohave some things in common. Could it be that the dot-com collapse marked somekind of turning point for the web, such that a call to action such as "Web2.0" might make sense? We agreed that it did, and so the Web 2.0Conference was born.
In the yearand a half since, the term "Web 2.0" has clearly taken hold, withmore than 9.5 million citations in Google. But there's still a huge amount ofdisagreement about just what Web 2.0 means, with some people decrying it as ameaningless marketing buzzword, and others accepting it as the new conventionalwisdom.
A significant aspect of theis that it is
Like manyimportant concepts, Web 2.0 doesn't have a hard boundary, but rather, agravitational core. You can visualize Web 2.0 as a set of principles andpractices that tie together a veritable solar system of sites that demonstratesome or all of those principles, at a varying distance from that core.
O'Reilly (
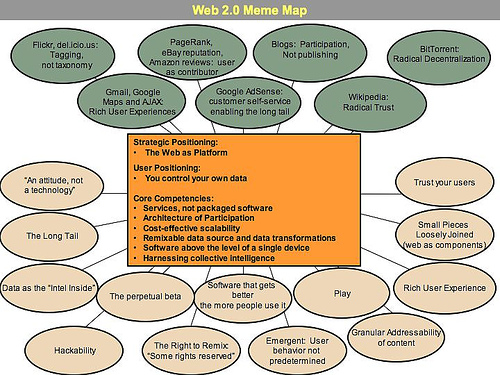
Figure ???: Diagram of Web 2.0 (
Figure ??? shows many interactive 'spaces' (grey) as partof the Web. This means that users do not just receive information andcommunications but they initiate or respond to them as well. For this, theyneed a range of competencies (orange). The Web, as it is now, has a number offeatures (pink).
Web 2.0, the current Web, is vastly different from theworld of paper publications,
In November 2005, Dan Saffer described Web 2.0 in terms ofthe experiences associated with it and with an image:

On theconservative side of this experience continuum, we'll still have familiarWebsites, like blogs, homepages, marketing and communication sites, the bigcontent providers (in one form or another), search engines, and so on. Theseare structured experiences. Their form and content are determined mainly bytheir designers and creators.
In themiddle of the continuum, we'll have rich, desktop-like applications that havemigrated to the Web, thanks to Ajax, Flex, Flash, Laszlo, and whatever elsecomes along. These will be traditional desktop applications like wordprocessing, spreadsheets, and email. But the more interesting will beInternet-native, those built to take advantage of the strengths of theInternet: collective actions and data (e.g. Amazon's "People who boughtthis also bought..."), social communities across wide distances (YahooGroups), aggregation of many sources of data, near real-time access to timelydata (stock quotes, news), and easy publishing of content from one to many(blogs, Flickr).
Theexperiences here in the middle of the continuum are semi-structured in thatthey specify the types of experiences you can have with them, but users supplythe content (such as it is).
On the farside of the continuum are the unstructured experiences: a glut of new services,many of which won't have Websites to visit at all. We'll see loose collectionsof application parts, content, and data that don't exist anywhere really, yetcan be located, used, reused, fixed, and remixed.
The contentyou'll search for and use might reside on an individual computer, a mobilephone, even traffic sensors along a remote highway. But you probably won't needto know where these loose bits live; your tools will know.
Theseunstructured bits won't be useful without the tools and the knowledge necessaryto make sense of them, sort of how an HTML file doesn't make much sense withouta browser to view it. Indeed, many of them will be inaccessible or hidden ifyou don't have the right tools (
As Saffer says,
There's beena lot of talk about the technology of Web 2.0, but only a little about theimpact these technologies will have on user experience. Everyone wants to tellyou what Web 2.0 means, but how will it feel? What will it be like for users? (
This idea of versions of the Web is clearly abhorrent tosome, as they consider its continuous evolutionisconsidered by them to be one of its virtues (
Web 1.0refers to the first generation of the commercial Internet, dominated by contentthat was only marginally interactive. Web 2.0, characterized by features suchas tagging, social networks, and user- created taxonomies of content called"folksonomies," added a new layer of interactivity, represented bysites such as Flickr, Del.icio.us, and Wikipedia.
Analysts,researchers, and pundits have subsequently argued over what, if anything, woulddeserve to be called "3.0." Definitions have ranged from widespreadmobile broadband access to a Web full of on-demand software services. Amuch-read article in the New York Times last November clarified the debate,however. In it, John Markoff defined Web 3.0 as a set of technologies thatoffer efficient new ways to help computers organize and draw conclusions fromonline data, and that definition has since dominated discussions atconferences, on blogs, and among entrepreneurs (
The research necessarily involved recognising andpredicting changes at least to prepare for them. As William Gibson wrote, “thefuture is here, it is just unevenly distributed.” (
We need tokeep our eyes on web trends and recognise trends that actually help to improvedisabled people’s experience of the web. Arguably, personalisation is a trendthat actually helps as its focus is on sites’ best possible performance forevery user and is a great deal more effective that the ‘one site for all’approach.
As part of the process, there is a substantial shift from afocus solely on the production of information and communications to a widerfocus inclusive of post-production activities and consumer contributions.
Scope of the Web
The United Nations Convention (
Thisdocument is an entry point for those wishing to implement the AGLS MetadataStandard for the online description of online or offline resources. from 1.1 of"AGLS Metadata Standard Part 2: Usage Guide" draft - not available topublic yet...
They continue:
The aim ofthe AGLS Metadata Standard is to ensure that users searching the Australianinformation space on the World Wide Web (including intranets and extranets)have fast and efficient access to descriptions of many different resources.AGLS metadata should enable users to locate the resources they need withouthaving to possess a detailed knowledge of where the resources are located orwho is responsible for them. in 1.5 of "AGLS Metadata Standard Part 2:Usage Guide" draft - not available to public yet...
Computer operating systems are now being designed with theuser interface driven by metadata in ways that extend the familiar interface ofthe 'Web' to personal computers and the files within them (for example, Sugaron the XO computer (Derndorfer,2008), and the Google desktop (http://desktop.google.com/).
For this research, the 'Web' is defined as all digitallyaddressable resources without necessarily distinguishing between theapplications or formats in which they are developed, stored, delivered or usedby others. This, according to the man credited with the invention of the WorldWide Web, Sir Tim Berners-Lee, is 'the Web' and as it develops it achieves morediversified characteristics:
The SemanticWeb is an evolving extension of the World Wide Web in which web content can beexpressed not only in natural language, but also in a format that can be readand used by software agents, thus permitting them to find, share and integrateinformation more easily.[1] It derives from W3C director Sir Tim Berners-Lee'svision of the Web as a universal medium for data, information, and knowledgeexchange (wikipediaSemantic Web, 2007).
The essential feature of the Web, then, is that theresource can be addressed; that is, it has a Universal Resource Identifier [(Such identifier need not bepersistent (consistent even for dynamically created content), and the resourceneed not be maintained in any particular state and might be constantly changingand it may not even have continuity.
Brown and Gerrard (the
Accessibility
It is unlikely that more than 3% of the resources on theWeb are accessible (as defined in the research, see
(In this thesis, disabilities of a medical nature aredescribed as permanent disabilities. It is recognised that such disabilitiesnaturally increase with age and usually are experienced by all who live longenough.)
The research concerns the accessibility of the Web.Accessibility in this context is a match between a person's perceptualabilities and information or communication technologies and artefacts. Manypeople have special needs to enable this match, not the least people withlong-term disabilities. As the UN Convention says:
Persons withdisabilities include those who have long-term physical, mental, intellectual orsensory impairments which in interaction with various barriers may hinder theirfull and effective participation in society on an equal basis with others (
The use of the term accessibility in this researchdistinguishes between access as considered in this thesis and access as used todescribe possession of facilities for connection to the Web or having thenecessary legal rights to use resources. Thatmany of a
This is not an exhaustive definition and will be furtherelaborated (Chapter 3) but it issignificantmedically defined as
Metadata
The most common definitions of metadata in the librarycommunities from where it emerged in the context of the Web, suggest it is anagreed format for the creation of machine-readable descriptions of digitalresources that can be used for, among other things, the discovery of thoseresources (wikipedia metadata,2008; University ofQueensland Library, 2008; UKOffice for Library and Information Networking, 2008;
The term metadata is usually applied to such descriptionswhen they are, in themselves, to be treated as resources whereas otherdescriptions of the same resources might be field names in a databasecontaining those resources. Meta-metadata is metadata about a metadataresource. This 'first-class object' characteristic of metadata also supportsthe interoperability of the descriptions, and it is this quality that is oftenthought of as distinctive of metadata.
Metadata, as defined in the research, is used toprovide a reference for implementations that require interoperability of theproducts of the implementation. As such, metadata is an abstraction from whatis used by implementers.
There is a detailed discussion of metadata in
AccessForAll metadata
AccessForAll [AfA] accessibility depends on metadata fordescriptions of the accessibility characteristics of resources. Thesedescriptions enable content providers to create and offer resources that can beadapted to individual needs and preferences. Thus they can minimise themismatch between people who, especially but not exclusively, have special needsdue to medically recognised disabilities, and resources published within whatis here defined as the Web. This is explained further in
AccessForAll accessibility is based on the use of metadata.By adding AfA metadata to resources and resource components, new services areenabled that support just-in-time, as well as just-in-case, accessibility.Metadata describing individual people's accessibility needs and preferences ismatched with descriptions of the accessibility characteristics of resourcesuntil the individual user is able to access a resource that satisfies theirneeds and preferences (Figure ???).
While nbut immediately transformed, tomake the Web more accessible. AfA includes new specifications forthe classification of resources. Initially, these were for education only. Theywere further developed as an ISO/IEC JTC1 multi-part education standard(N2008:24571). The continuing aim is to see their application broadening for resourcesacross all domains, including being adopted by other standards bodies (alreadyadopted in Australia as part of the Australia-wide AGLS Metadata Standard [
Metadata specifications usually butrather the form of definitiontherole that is considered themselvescontaining the semantics are to bepublished for free and will be available from the various standards bodies' Websites (IMS GLC;
The research provides evidence that there is alreadymetadata available that could be transformed to match the new standards, andthat other suitable data could be generated automatically from existing data(see Chapter 7). Currently, such data is notavailable for use by those with accessibility needssoindividual users cannot discover, in anticipation of the receiptof resources, if they will be able to access them.
Summary of definitions
In many discipwaerms, and so their particular use in thiscontext can be confusing. What follows further limited
Research scope limitations
A significant problem for people with special needs, andtheir content providers, is that there are often intellectual property issuesassociated with the materials, especially when they are transformed for accessby users. In many jurisdictions, there are special rights for people withcertain recognised disabilities and they can involve complicated intellectual propertyrules. This is completely beyond the scope of this research that focuses on howsuch materials can be made discoverable and interoperable,
The research includes a detailed analysis of the commonapproach to accessibility based on the World Wide Web Consortium's WebAccessibility Initiative's specifications and the techniques employed toachieve it. This information is in a Web site that provides a set ofpractices and their explanation (
The research is not about the techniques used to makedigital information accessible to people with disabilities although unless there is information that isaccessible to them, the metadata frameworkproposed cannot help. It isabout how, when information isidentified as of interest, a user with particular needs at the time and in thecontext in which they find themselves, can have the intellectual content of the that was originally discovered presentedd totheir needs and preferences. If necessary, this includes having components ofthe original intellectual content replaced or supplemented by the sameinformation in other modes, or having it transformed, and it contributes the potential forthis to be done, not the components themselves.
A challenging attribute of digital information is theincreasing mobility of people who expect information to be availableeverywhere, and to be able to use
The context in which a user is operating is fundamental tothe type and range of needs and preferences they will have (Kelly et al, 2008).The research embraces what is known as the Web 2.0. In this Web world, anevolutionary progression from the original Web which was created by thetechnique of referenced resources and distributed publishing, users interactwith resources and services that are made available by others, often with noknowledge of their source. (Discussion of the new environment and the way itoperates is within scope as it provides the context for the work (see
If a resource contains some components that areinaccessible to a user, it will need to have those componentsto be peculiar to accessibility somuch as a peculiar problem related to
Out of scope also is any requirement to engage with theadoption of AfA by industry. Adoption by standards bodies depends uponprocesses that engage the industry in formal ways, so adoption by such a bodyis considered to include adoption by industry. Implementation is, on the otherhand, not always ensured by the existence of standards. At the time of writing,before publication of the standards, there are already significantimplementations of the AfA standards. These are discussed in
Research methodology
Pioneering research
The research reported is not a traditional empirical studyof a static situation. Rather, it is research to determine how, in a fastchanging world, metadata about resources can be used to ensuremaximum accessibility for individual users of
John Seely Brown (1998) differentiated between what hethought of as two main kinds of research, sustaining and pioneering.Sustaining research, he thought, is aimed at analysis and evaluation ofexisting conditions. The problem for researchers in fast-changing fields isthat often, by the time sustaining research is reported, the circumstances havechanged. As the original circumstances cannot be reproduced, the researchresults would need to be interpreted into adifferent context to be useful and in some fields, this cannot happen. In thecase of pioneering research, the work is successfully implemented or, perhapsmore often, forgotten. This is the sort of work in which many technologyfocused researchers are engaged: they follow what are traditional researchpractices to a point, but their work is evaluated differently and they need toengage with and accept different types of evaluation.
The 'best' technology is not always the one that becomesthe accepted technology, as in the case of video standards and the Betastandard (Weiner, 2005, p. 311). In the current technology environment,acceptance is crucial because it is the mass acceptance and frequency andextent of its use, what is often called 'the network effect', that makes thetechnology what it is. In the case of metadata, without mass acceptance thereis usually nothing of particular value that can be claimed.
Pioneering research is what Seely Brown (opcit
Within the field of pharmacology, research is combined withempirical research before the work is released onto the market or used with humans.In the case of developments of Web 2.0, a product or idea or specification'srelease is watched for adoption and it is only in hindsight that its'effectiveness' is determined, and then by popularity. This is not alwayssatisfactory. Experience has shown us that substantial reliance can bemisplaced on technologies that do not solve the problem for which they weredesigned. The Apple Newton, WebTV, the IBM PC Junior are just a few of thetechnologies that have been launched with great fanfare but failed within ashort time. Many of the features of these technologies are still around, but inother forms (
It is essential that the intrinsic value of the technologyis accounted for. In the field of accessibility, almost all effort has focusedon a single set of guidelines (WCAG)with what this thesis argues are less than satisfactory results. It isimportant to evaluate AccessForAll accessibility to ensure this does not happenagain. For whatever interest there is in the idea of AccessForAll metadata,there is still a need for research to discover how to create a suitable awarenessof the context for the work and the value of the work. This means developing astrong understanding of the theoretical and practical issues related toaccessibility, including practical considerations to do with professionaldevelopment of resource developers and system developers, and theadministrative processes and people that usually determine what thesedevelopers will be funded to do. It also involves the reading and writing ofcritical reviews of other work. In particular, while there is little doubt ofthe potential benefit to users with disabilities, it is not at all clear how towork with the prototyped AfA ideas to make them mainstream in the wider world,both in the world outside the educational domain and in the world of mixedmetadata schemas (correct use of this word would be schemata but common usageaccepts schemas).
Although AfA AfA
Many use the expression 'research and development' todifferentiate between research and development. Development work is socharacterised without regard for the processes involved in achieving it. One isreminded of Mitchel Resnick's story of Alexandra whose project to build amarble-machine was rejected as not scientific until the process was carefullyexamined when she was awarded a first prize for the best science project(Resnick, 2006). In some fields, research is not just about writing a report,it is also about repeatedly designing, creating, testing, evaluating andreviewing something in an iterative process, often towards an unknown resultbut according to a set of goals. These are also important processes for design.Such processes benefit from rigorous scrutiny that can be attracted in avariety of ways, including by being undertaken in a context where there arestrong stakeholders with highly motivated interests to protect. There is nogetting away from the value of well-researched and documented research
In "Design Experiments: Theoretical and MethodologicalChallenges in Creating Complex Interventions in Classroom Settings", AnnBrown (1992)describes the problem of undertaking research in a dynamic classroom. She was,at the time, already an accomplished experimental researcher, but argued thatit was not possible or appropriate to undertake experimental research in achanging classroom. The problems referred to were related to the complexity ofresearch closely associated with development in a dynamic context. In the caseof AccessForAll, the context was not fixed and so did not afford research ofthe kind associated with numerical analysis but rather, called for cleardocumentation of the problems to be solved, the context, the possibilities andthe implications of the proposed solution. This thesis provides thatdocumentation.
Brown argued that she needed to develop methodologies thatwould analyse what was happening in the changing classrooms and provide usefulinformation for others wishing to replicate the model and results in otherclassrooms. This thesis provides analysis of relevant aspects of accessibilitywork to provide useful information for those wishing to use metadata toincrease the accessibility of the Web.
Problem-solving and learning are similar activities.Educationalists aim to improve learning environments; accessibility specialistsaim to improve accessibility problem-solving environments. They want betterpractices and better understanding and evaluation of those practices.
In "Design-based research: An emerging paradigm foreducational inquiry",
The authorsargue that design-based research, which blends empirical educational researchwith the theory-driven design of learning environments, is an importantmethodology for understanding how, when, and why educational innovations workin practice. Design-based researchers’ innovations embody specific theoreticalclaims about teaching and learning, and help us understand the relationshipsamong educational theory, designed artifact, and practice. Design is central inefforts to foster learning, create usable knowledge, and advance theories oflearning and teaching in complex settings. Design-based research also maycontribute to the growth of human capacity for subsequent educational reform(DBRC and D.-B. R. Collective, 2003).
The complexity of the accessibility work is not unlike thatof education; everything is constantly changing, including the technology, theskills and practices of developers, the jurisdictional contexts in whichaccessibility is involved and the laws governing it within those contexts, andthe political environment in which people are making decisions about how toimplement, or otherwise, accessibility. There are also a number of players, allof whom have different agendas, priorities and constraints, despite theirdeclaration of a shared interest in increasing the accessibility of the Web forall.
The Australian Research Council funded the CleverRecordkeeping Metadata (CRKM) Linkage Project in 2003-2005 (
The researchmethodology was designed within an action-research framework where a closealignment between the practical development of tools and active reflection oneach stage of their development iteratively informs both the furtherdevelopment of the tools and also identifies challenges and issues to beaddressed in an ongoing fashion.
The researchinvolved the initial development of a proof-of-concept prototype to demonstratethat metadata re-use is possible and illustrate the business utility ofrecordkeeping metadata. From that initial proof of concept, the projectintended to develop a more robust demonstrator available for wider dissemination.
FirstIteration: Development of Proof of Concept Prototype
The firstiteration of the CRKM Project investigated a simple solution for demonstratingthe automated capture and re-use of recordkeeping metadata. The expectation wasthat this initial investigation would expose the complex network of issues tobe addressed in order to achieve metadata interoperability and automate themovement of recordkeeping metadata between systems, along with enablingresearchers to develop skills and understandings of the existing technologiesthat support metadata translation and transformation. (
At the end of the three year project, the key findingswere:
There aresignificant barriers to interoperability within our current metadata standardsand in our current records management and archival control frameworks.
Translationbeyond a web services environment into a fully realised service orientedarchitecture is outstripping implementation reality, with current technologyconstraints illustrating that truly service oriented implementations are reallythings of the future
Ourcommunity has an opportunity to evolve towards that future via web servicesused initially to wrap legacy systems to achieve data interoperability as weprogressively move towards decomposing and re-engineering recordkeepingfunctionality as services and creating appropriate business process and rulesinfrastructure. (CRKM, 2007)
The project demonstrated the use of an established computersystems development methodology in the metadata context. The closely couplediterative review/development process underlies the current research reported inthis thesis. In this case, the multiple reviews by multiple stakeholderssignificantly influenced the development of the final metadata, as shown inFigure ???
In the introduction to a paper describing the researchmethodology for the CMKM project, Evans & Rouche (
Archivalsystems, like other information systems, are undergoing radical change as theimpacts of digital and network technologies on recordkeeping and archivalprocesses are grappled with. Accustomed to dealing with mature systems andtechnology, the field of archival science is at a point where archival researchneeds to encompass methods that investigate how emerging theories areoperationalized through systems development. Systems development researchmethods allow exploration of the interface between theory and practice,including their interplay with technology. Not only do such methods serve toadvance archival practice, but they also serve to validate the theoreticalconcepts under investigation, challenge their assumptions, expose theirlimitations, and produce refinements in the light of new insights arising fromthe study of their implementation. (
'Accessibility systems' might well be substituted for'archival systems' in this text. Engagement with the development ofAccessForAll metadata enabled accessibility research that "needs toencompass methods that investigate how emerging theories are operationalizedthrough systems development". In the case of the CRKM project, theresearchers were interested in discovering how schemas played a role in thearchival context so they would know how to build a metadata registry that usessuch schemas (
The purposeof such a registry of metadata schemas is to act as a data collection andanalysis tool to support comparative studies of the descriptive schemas. (
The CRKM registry was to provide content for use in aharmonisation of schemas to inform a standardisation process. In the words ofthe researchers:
With noexisting blueprint for such a registry, the first task of the research team wasto conceptualise the system and establish its requirements. In so doing severalkey questions are raised including: – What are the salient features ofmetadata schemas that need to be documented for the purposes outlined above?How are these realised as elements? ... In order to address these questions,the research team looked at utilizing systems development as an exploratoryresearch approach. (
Systems development research
Systems development as a research method is well-establishedin information systems literature. Evans & Rouche cite Nunamaker et al(1990-91) as arguing for "inclusion of systems development as a pivotalpart of ‘a multimethodological approach to IS research’" (
Bursteinelaborates on the process for such a systems development research approach,suggesting three major iterative stages – concept building, systembuilding and system evaluation [Figure ???]. The concept building phaseinvolves the identification and development of the research questions andinvestigation of the system requirements and functionality, incorporatingrelevant ideas and approaches from other disciplines. The system building phaseinvolves constructing the system using systems development techniques and thesystems evaluation phase involves analysing and assessing the system.

Burstein is further quoted as saying (
The majordifference between this approach as a research method and conventional systemsdevelopment is that the major emphasis is on the concept that the system has toillustrate, and not so much on the quality of the system implementation. At thebeginning of such a project the implementation has to be justified in terms ofwhether there is another existing system capable of demonstrating the featuresof the concept under investigation. The evaluation stage of the systemsdevelopment method is also different from the testing of a commercial system.It has to be done from the perspective of the research questions set up duringthe concept-building stage, and the functionality of the system is very much asecondary issue. (Burstein, 2002, p. 153)
Evans and Rouche argue that at all times using the systemsdevelopment research, researchers must be motivated by the research questionswhereas systems development is usually motivated by practicality (
Finally, Evans & Rouche (
Research activities
The research has resulted in the first significantdescription of AccessForAll metadata and how it can be used. It has justifiedthe development of such an approach to accessibility, and shown how the actualmetadata schema could be developed. This has involved a wide range of researchactivities, as shown below.
To investigate how effective accessibility efforts were ina typical organisation, the author was involved in the auditing of a majoruniversity Web site (ation of several in theauditprocess, produced descriptions (metadata) ofthe accessibility characteristics of the 48,084 pages reviewed.
To facilitate the use of the WCAG specifications by contentdevelopers, the Accessible Content Development Web site (
To develop an automatic
To gain an insight into formal empirical researchdocumenting specific problems with the W3C WAI Web Content Accessibilityguidelines, the author studied the UK’s Disabilities Rights Commission’s reviewof 1000 Web sites. This was the first major review of Web sites that evaluatedthe WCAG’s effectiveness. Many of the findings have more recently beensubstantiated in other work (see Chapter 4)and they have been anecdotally reported by the author and others for manyyears.
The author To discover the likelihood that ifAccessForAll metadata were developed, it wouldbe possible to apply it
To understandAfAthe AccessForAll ideas might operatein a distributed environment, the author studied the Functional Requirementsfor Bibliographic Records (FRBR)and associated work and tried to determine how resources should be described sothat other resources with the same content but represented in different modesor with other variations might be discoverable. This work was undertaken withJapanese colleagues who, at the time, were trying to learn from FRBR and theOpenURI work. The author is more inclined to think that a new approach toresource description to be known as GLIMIRs may, in fact, prove more useful inthis context (see above).
To make sure do thisdoing this, the author discovered theambiguity of the DC Abstract Model as first expressed and became involved inwork to clarify thatlosslessly interoperate
There are many major players in the field of accessibility.These stakeholders had to be won over asthbut arecompetes with the political andaffective challenges.
At the time the ,IMS GLC, etc, it is indicative of what waspotentially constraining of the AfA work of the author and
In design experiments, or research using design experimentsthat is often just called design research, it is a feature of the process thatthe goals and aspirations of those involved are considered and catered for. Infact, as the work evolves, the goals of the various parties are likelywork changes according to the circumstancesand the research enlightens
The current research is not about researchers testing ahypothesis on a randomly selected group of subjects; the stakeholders and thedesigners interact regularly and advantage is taken of this to guide thedesign. The practical aspects are constantly revised according to newlyemerging theoretical principles and the new practical aspects lead to revisedtheories. The goals do not change but the ways of achieving them are not heldimmutable.
In the work reported here, considerable interaction occurredbetween the author as researcher and the author and colleagues and otherstakeholders in the design process. This and then votes of support forcontinued work. Challenges to the work, when they occur, generally promote thework in ways that lead to revisiting of decisions and revisionof the theoretical position being relied upon at the time. Such challenges alsoprovide insight for the researcher into the problems and solutions beingproposed.
In particular, the author wasindeedwas initially is deeply engaged in the LOMapproach, even though many others working in education are not. The IMS GLC'sinterests were towardsfor an outcome that wouldwill suit them but, as the author saw was
During the research, the DCMI itself was would . Thiswas achieved and it is possible to cross-walk between the various metadatastandards so that it does not matter so much which is used, because the data ofthe metadata descriptions can be shared without loss.
The design work reported has been progressively adopted andhas now become part of the Australian standard for all public resources on theWeb (as AGLS Metadata Standard) and byvirtue of being an ISO standard, an educational standard for Australia. Thiscan be taken as indicative
Chapter Summaries
The research establishes that, given an understanding ofthe field of accessibility, the context for it, and frustration with the lackof success and the results of recent research, it is evident that for all thegood intentions, there has been poor implementation of accessibility techniques.Universal design is not a sufficient strategy even if it is applied, and anarrow focus on specifications for authoring of Web content alone will notproduce the desired results. This means there is a need for a new approach. Byusing a range of existing and emerging standards and introducing metadata todescribe user needs and preferences, it is possible to match them to resourcecharacteristics, also described in metadata. By adding this possibility,without compromising interoperability of metadata or stakeholder interests, andby attracting implementation, individual access needs and preferences should beable to be satisfied. This AccessForAll approach places emphasis on theaccessibility of the Web for individuals, and draws upon many standards workingtogether. It does not depend upon universally accessible resources butincludes them.
The following chapters report on:
·
·
·
·
·
·
·
·
·
·
Chapter 3: Accessibility andDisability
Introduction
In this chapter, the term 'accessibility' is considered insome detail. Most people assume they know what it means because they assumethey can imagine what it is like to have such disabilities as blindness, andthey seem to assume also that the functional problems for people withdisabilities are easily defined and even, perhaps, soluble. This chapter showsthat these assumptions are not helpful. It also asserts that it isinappropriate to think of disabilities as fixed qualities of people rather thanchanging characteristics of contexts and activities.
Understanding accessibility
One of the most frequently cited articles about the Web andaccessibility is the article by Steve Lawrence and C. Lee Giles (
"As theweb becomes a major communications medium, the data on it must be made moreaccessible."
They were, as so many now realise, talking about why theywere working on search engines, and most particularly Google, the now famousentrance to the Web. Their sentiments were similar to those of many others,especially those working to ensure that everyone gets access to information onthe Web. Lawrence and Giles were quoting figures such as 800 million pages, 6terabytes of text data and 3 million servers back then in 1999 being publiclyindexed but amounting to only about 16% of what is actually available. Theywere lamenting that much of what people possibly wanted to find was not indexedby anyone.
Tim Berners-Lee is reputed to have said some time ago that,"The power of the Web is in its universality. Access by everyoneregardless of disability is an essential aspect" [
Accessibility and disability as terms have been in tensionfor a long time. The term "accessibility" is ambiguous as access canbe of many types, including that dependent upon economic conditions,intellectual property rights, telecommunications services, etc. Disabilitycommunities are often quick to promote a particular view or perspective of theeffects of the disability on users that avoid labeling people and insteadconcentrate on positive aspects of their lives. Members of the deaf communityin Melbourne, Australia, often ask to be referred to as that, members of a deafcommunity, and they assert that their communication in sign language is itselfnot appropriately described by reference to a medical condition so much as theuse of a non-English language. They expect to be treated in the same way asother non-English speaking people (comments based on private communications andpersonal experience). In different countries, the names for disabilities oreven their presence are changed for political reasons. At times, it seems, itis good to avoid labeling people by their disabilities and better to promotepeople's abilities to avoid referring to their disabilities. At other times,however, the disabilities are referred to in order to draw attention to them:the context and goals are often determinants of which definition is used.
Somehow, it seems that it is the community for people withvision disabilities who are the most active and effective in gaining fundingfor work on accessibility of the Web. They have the advantage that most peoplein the community think they know a little bit about vision impairment; theythink they can imagine what it would be like to have such a problem even iftheir image of what it is like does not in any way match reality. They are allalso very likely to suffer from such an impairment themselves, especially, asis often said, if they live long enough!
Vision impairment is not a quality of a person, it iscondition of a person in a context: everyone has a vision impairment sometimes.When driving a car and trying to find a new location, we find drivers lookingat printed maps and looking at the road, or worse, looking at the road andgetting directions on a mobile phone screen. It is what is called an 'eyesbusy' situation, where driving should completely occupy the eyes, they arebeing shared across tasks. Effectively, the person has a vision impairmenteither with respect to watching the road, or to reading the map or using thephone. Additionally, of course, the person also has a control impairment: theirhands cannot perform well at two tasks at the same time. Disabilities arerelative to contexts and activities.
Other disabilities are even harder to understand andrecognise. Cognitive impairment is not usually expected to be associated withpeople who are performing well in the community but universities are beginningto find that a number of their otherwise capable students have dyslexia, forexample (Morgan, 2000).Statistics vary enormously as dyslexia, for example, is not clearly defined andthus not easily quantified, but it may be reasonable to assume every classroomhas at least one dyslexic student. Being clever and being dyslexic can easilygo together (Lloyd,2007), it seems, as the disability is relative to reading. In the case oflearning Japanese, a character-based language as opposed to Roman languages,there is some chance that dyslexia will not be relevant or is even a positiveability (
A difficulty associated with working to support people withdisabilities is, then, discovering who needs assistance and what assistancethey need. In part this is due to our reluctance, for good reason, to labelpeople by naming a disability. It is partly due to the reluctance of somepeople to identify as having a disability, to self-identify, and partly due tothe ignorance of many people that they do, in fact, have a disability in agiven situation. In everyday life, for most things, people overcome whateversmall inadequacies they have and are unaware of the process. Many people simplydo what they can do well and don't bother with what they can't do so well. Inmost situations this works. The problems arise when people are required to dosomething they can't do well.
The workplace is one context in which tolerance fordisabilities is critical: people are often required to perform tasks thatcompromise their abilities. Accessing civil rights is another: being able tovote, being able to access government services, being able to buy tickets tothe Olympics Games, are just a few activities to which all citizens have anequal right of participation.
To repeat and misuse what Lawrence and Giles (
So disability and accessibility have a context: the questionbecomes, in the presence of this major communications medium, when are peopledenied access? The answer is found in a variety of ways, as shown below, and itis as variable as the ways of describing disabilities or abilities, as will beseen. It is not simplified by an approach that aims to use medical pathologyterms but it is easier to work with when it is described in terms of requiredfunctionality.
Models of disability
In addition,we would like the report to use the World Health Organization’s (WHO) newstandard definition of disability, The International Classification ofFunctioning, Disability and Health (ICF - May 2001), and avoid the use ofexpressions such as “handicapped, demented and less skilled people”. This newdefinition emphasizes that disabled people’s functioning in a specific domainis an interactive process between their health condition, activities and thecontextual factors. It is a radical departure from the earlier versions, whichfocused substantially on the medical and individual aspects of disability. Thesocial model of disability suggests that disability is not entirely anattribute of an individual, but rather a complex social and environmentalconstruct largely imposed by societal attitudes and the limitations of the human-madeenvironment. Consequently, any process of amelioration and inclusion requiressocial action, and it is the collective responsibility of society at large tomake the environmental and attitudinal changes necessary for their fullparticipation in all areas of life (
As stated in Wikipedia (
The socialmodel of disability is often based on a distinction between the terms'impairment' and 'disability.' Impairment is used to refer to the actualattributes (or loss of attributes) of a person, whether in terms of limbs,organs or mechanisms, including psychological. Disability is used to refer tothe restrictions caused by society when it does not give equivalent attentionand accommodation to the needs of individuals with impairments.
The 'social model of disability' was first proposed byMichael Oliver in 1983 but later explained further, particularly in 1990:
There aretwo fundamental points that need to be made about the individual model ofdisability. Firstly, it locates the 'problem' of disability within theindividual and secondly it sees the causes of this problem as stemming from thefunctional limitations or psychological losses which are assumed to arise fromdisability. These two points are underpinned by what might be called 'thepersonal tragedy theory of disability' which suggests that disability is someterrible chance event which occurs at random to unfortunate individuals. Ofcourse, nothing could be further from the truth.
The genesis,development and articulation of the social model of disability by disabledpeople themselves is a rejection of all of these fundamentals (Oliver 1990a).It does not deny the problem of disability but locates it squarely withinsociety. It is not individual limitations, of whatever kind, which are thecause of the problem but society's failure to provide appropriate services andadequately ensure the needs of disabled people are fully taken into account inits social organisation. Further, the consequences of this failure does notsimply and randomly fall on individuals but systematically upon disabled peopleas a group who experience this failure as discrimination institutionalisedthroughout society. (
Oliver argues that by using a social model, one canunderstand disability as something that can be dealt with at a social level,that it is not merely about non-normal characteristics of individuals but ratherthe ways in which society functions. Social efforts including adjustments can,according to Oliver's theory, remove a disability.
Liz Crow (
A major use of the social model is the development ofinclusive practices. Inclusion aims to consider all people equally and to avoiddisabilities by providing for the needs of all people. To achieve this ineducation, for example, communities have worked on attitudes and practices thatvalue everyone equally and so provide for all of them equally. Inclusion UK isa consortium of four organisations supporting inclusion in education. On theirWeb sites [Inclusion UK], theydescribe their work. The Centre for Studies on Inclusive Education providesdetails about their publications [
The Indextakes the social model of disability as its starting point, builds on goodpractice, and then organises the Index work around a cycle of activities whichguide schools through the stages of preparation, investigation, development andreview. (Booth& Ainscow, 2000)
The Index was widely distributed in the UK education systemand has been updated. Of interest in this thesis is the approach taken by theauthors. Inclusion is not treated as a fixed quality of a location but ratheras a set of practices. The authors advocate a continuous cycle of developmentand review.
In this thesis, the social model of disability is adoptedwith the aim of making the Web an inclusive information space, with continualimprovement based on an on-going cycle of development and review of Webresources.
Inaccessibility and users
In the mid 1980's, long before the Web become popular,there were communities of people with disabilities (in the medical sense) whohad already been using computers for some time. The technology of the timeallowed for text activities online and these presented few problems forassistive technologies; people with hearing disabilities were often assisted bytheir use of teletype machines and other print technologies that could allowthem to communicate using what were otherwise typically sound or image andsound technologies, such as telephones, televisions, etc.; people with sightdisabilities were able to use computers to enlarge script, to have it readaloud to them, and to produce Braille. (The author worked with suchtechnologies for three years from 1983-6 for Barson Research.)
In 1989, Mosaic was released as a first major mouse-driveninterface to the Web.
The Web'spopularity exploded with Mosaic, which made it accessible to the novice user.This explosion started in earnest during 1993, a year in which Web traffic overthe Internet increased by 300,000%.(
A significant aspect of the Web that made it instantlyattractive to the masses was its ability to include mouse-controlled images,sounds, and multi-media in general.
Unfortunately,the very technology that has opened the door to unprecedented access alsoharbors the possibility for the very opposite. Just as there are enabling anddisabling conditions in the physical environment, so are there conditionsassociated with digital technology that result in the inclusion or exclusion ofcertain people. Technology that is not universally designed, withoutconsideration for the full spectrum of human (dis)abilities, is likely tocontain access barriers for people with print disabilities (
It is the same technology, often, as was able to increasethe inclusion of people with disabilities prior to the Web's emergence. Itstill can be used in ways that enable people: Miles Hilton-Barber, a blind man,recently co-piloted a small plane half-way around the world (The Age, 2007).
A typical and simple illustration of what became a problemfor some people is the use of the 'mouse' and cursor. People with sightdisabilities rarely use mice because they do not get the instant feedback thatendears mice to people with good sight. The cursor, driven by the mouse, floatsover the structure of a screen representation, and is freed from the serialflow of text, for example. This freedom is just what makes the mouse-cursorcombination useful to people using sight and useless to people who cannot seeit. They cannot tell where it is. There is no coordinate system that can conveyto people who cannot see what is offered to the person who watches the cursor.Recently, the new project Fluid hasdeveloped a drag-and-drop user interface component that will be used to do thisin the future.
Mouse-cursor users move the screen content under thecursor, by using other screen controls, and move the cursor over the screen.Many people who cannot see the cursor move about the screen by using keystrokesfor such functions as 'line-up', 'line-down, 'move-left', 'move-right'. Onarrival at a 'screen' destination, they need information about where they are,what it is that they are capable of acting on. In the case of the Web, this isoften a hyperlink. It was almost always, in the beginning, and is still toooften, labeled "click here". For the sighted person, the surroundingcontext, including the layout of the objects on the screen, will probably tellthem what is likely to happen if they do, indeed, click there. The person whocannot see the screen, and so does not know the context for the hyperlink, isoften confused as to what will happen if they click. Worse, experience soonteaches them that if they click, they may well be taken somewhere they did notanticipate and it might be very hard to find their way back. This, because theeasy recovery technique of simply pressing the back button does not work whenthe link in fact spawned a new window, and that window does not have a'previous' window. If they do find the previous location, how do they knowwhich hyperlink to click when there are several choices all similarly labeled?How do they know if this link relates to the writing before the link or thewriting after it, without access to the screen to see how the links are relatedgraphically and location-wise on the screen? Perhaps there is a pull-down menuof links.
It is not hard to understand that without labeling oflinks, without certainty about the relationship between a link and adescription of the choices available, the user does not have satisfactoryaccess to the content that will be available if the link is activated.
Further, if what is offered as a resource is a video,without captions and a transcript, a deaf person is unlikely to havesatisfactory access to the content of the video. Without a tactile version orlong description of a diagram, a blind person is not likely to havesatisfactory access to chemical content they may need. Without access to thecontent in a language understood by the user, there will be no access. Withoutcontent that is free of sarcasm, irony, literary illusion, a person withdyslexia is unlikely to have adequate access.
For all these reasons, the Web Content AccessibilityGuidelines authors have worked on the aspects of access which are important topeople who find themselves having access difficulties with Web content. Formany years now, the Web Content Accessibility Guidelines Working Group [
A detailed explanation of what accessibility means inpractice and how it is achieved is available in a hyperlecture (
Disability as functionalrequirements
In 1998, writing on the W3C WAI Interest Group mailinglist, Harvey Bingham forwarded the following from Ephraim P. Glinert
Folks: Iwould like to draw your attention to a new research focus on the topic ofUNIVERSAL ACCESS jointly sponsored by the HCI and KCS programs within theInformation and Intelligent Systems (IIS) Division of CISE.
The word"access" implies the ability to find, manipulate and use informationin an efficient and comprehensive manner. A primary objective of the HCI/KCSresearch focus on universal access is to empower people with disabilities sothat they are able to participate as first class citizens in the emerginginformation society. But more than that, the research focus will benefit thenation as a whole, by advancing computer technology so that all people canpossess the skills needed to fully harness the power of computing to enrich andmake their lives more productive within a tightly knit "nationalfamily" whose members communicate naturally and painlessly through thesharing of (multimodal) information (
Bingham was focused on what should happen, not how, and ithas taken until now to find technology that will enable his dream.
It has been noted that the research is advocating aninclusive Web. This means more than merely solving problems for those withmedical conditions that lead to a lack of access to resources.Internationalisation, for example, is treated as an issue of accessibilityalongside location dependence and independence.
The Australian Government, in 2008, established a SocialInclusion Board and has a Minister responsible for social inclusion (
Let me beclear: our social inclusion initiatives will not be about welfare – theywill be an investment strategy to join social policy to economic policy to thebenefit of both. For this reason, our Social Inclusion Unit and Board will bemade up of serious economic and social thinkers, not just welfarerepresentatives. This won’t be a memorial to good intentions – it will beabout action and hard-headed economics. (
Considerations related to age
About 15% ofEuropeans report difficulties performing daily life activities due to some formof disability. With the demographic change towards an ageing population, thisfigure will significantly increase in the coming years. Older people are oftenconfronted with multiple minor disabilities which can prevent them fromenjoying the benefits that technology offers. As a result, people withdisabilities are one of the largest groups at risk of exclusion within theInformation Society in Europe.
It isestimated that only 10% of persons over 65 years of age use internet comparedwith 65% of people aged between 16-24. This restricts their possibilities ofbuying cheaper products, booking trips on line or having access to relevantinformation, including social and health services. Furthermore, accessibilitybarriers in products and devices prevents older people and people withdisabilities from fully enjoying digital TV, using mobile phones and accessingremote services having a direct impact in the quality of their daily lives.
Moreover,the employment rate of people with disabilities is 20% lower than the averagepopulation. Accessible technologies can play a key role in improving thissituation, making the difference for individuals with disabilities betweenbeing unemployed and enjoying full employment between being a tax payer orrecipient of social benefits.
The recentUnited Nations convention on the rights of people with disabilities clearlystates that accessibility is a matter of human rights. In the 21st century, itwill be increasingly difficult to conceive of achieving rights of access toeducation, employment health care and equal opportunities without ensuringaccessible technology (Reding, 2007).
In 2008, a new European Commission IST Specific SupportAction project called WAI-AGE commenced with the goal of increasingaccessibility of the Web for the elderly as well as for people withdisabilities in European Union Member States [
Language and Cultural considerations
In the Report of the CEN ISSS MMI-DC (W15) Workshop onMetadata for Accessibility, Nevile and Ford (
The EuropeanUnion's official languages have recently increased from eleven to twenty. Thelinguistic combinations will increase from one hundred and ten to two hundredand ten. ... many Europeans have difficulties when using the Internet (
and, in more detail, with respect to multilingualism:
Languageshave inherent qualities: many of these are linguistic but others are cultural.Obviously, metaphors based on regionally or culturally specific analogies donot necessarily translate into other languages. What is often not realised isthat there are other qualities that affect language use: there are differentways of describing time, location, people's identities, and more. Conversationsacross language boundaries are endlessly surprising; the provision ofmultiple-language versions of content and translation of content are almostalways problematic. But within languages there are also problems: levels offacility with complexity of languages and limitations of languages are twoexamples. Not everyone is capable of understanding the same form of representationin any given language, yet we know this is not just a matter of literacylearning; for some it is to do with how well they have learned to read and forothers it is to do with constraints imposed on them by such disabilities asdyslexia and disnumeracy. Those dependent upon Braille, for example, can findthat their language does not yet have ways of representing information which iseasily represented in other languages. (
Further work on the problem of lack of access due tolanguage barriers was reported by Morosumi, Nevile and Sugimoto (2007). Theimmediate problem related to the lack of access to English research literatureavailable on the Web:
There are atleast three major groups of readers with language-skill problems who wantaccess to intellectually stimulating and specialist English texts:
We considerthe problem for second-language readers, translators (particularly automatedones) and people with dyslexia to be similar: In all cases it is important tohave plain English without distracting or confusing metaphors, or complicatedlanguage constructions such as the subjunctive mood or passive voice.
So it is necessary to be aware that cultural and linguisticconsireations can necessitate functional accessibility requirements forinformation users.
Location considerations
Location can be very relevant to accessibility: locationdependent information is very useful but it might need to be supplied in alanguage that is not associated with the location, e.g. for travelers. In sucha case, location independence can be very important. Just because one is inGreece does not mean that one is thinking of what is on in the local cinema; aparent might be interested in what film a child is proposing to see at thelocal cinema in their absence. Whereas most efforts to work with locationcurrently involve finding ways to be sensitive to the location, it is necessaryto also be sensitive to the user's needs irrespective of their location.
Location changes can cause mismatch problems when assistivetechnology settings, or the actions of user agents, or other circumstances,change in some way.
Contextsoften account for the special needs and preferences of users. If a user is in anoisy location, they will probably not be able to benefit from audio outputwhereas a user in a very quiet location may not be welcome to start using voiceinput. Content needs can also change because of device changes and these are attimes associated with location changes. So sometimes context influences will bepredictable according to the location and sometimes they will be temporary andpersonal, or independent of location.
The locationchanges might be small or large. When the changes are from one country toanother, such as for a traveler moving from Italy to France, it is likely thatthe changes will involve language changes. When location changes are triggeredby movement from one room in a house to another, it is quite likely thedifference will be device changes and this may mean changes in means of controlof the access device. ...
We can alsoimagine the same person moving from their personal laptop computer to the onein their family's office expecting to find that the office one needs to changeto their needs and preferences after it has accommodated other members of thefamily with different needs and preferences. We cannot imagine users wanting toset up their needs and preferences every time they make such location changes.In fact, there are many people who would not be capable of determining theirown needs and preferences and for these people, making the changes might be themost important.
When thelocation is fixed in one sense, as is the case in a train, but varied in aglobal sense, because the train moves, relative and absolute locationdescriptions become necessary (Nevile & Ford, 2006).
and
... we needa way to be precise about the locations so that we can ease the burden ofadapting the devices to the user. This in turn means being able to specify aparticular location with precision and in three dimensions. It also means beingable to describe dynamic locations, such as inside a moving car or train. Thesemay be relative locations. It also means being able to associate the user'spersonal profile for that device with that user's profile of needs andpreferences. There is a need then for flexible, interoperable, machine-readabledescriptions of locations for those cases in which they are determinants of thesuitability of user profiles.
There istherefore a requirement for both location-dependent and location-independentprofiling. The aim in both cases is the same, stability for the user and thus apersonal sense of location-independent accessibility, but one depends upon notbeing affected by a change in location and the other upon being affected by it.The location-independence is thus as viewed from the user's perspective (Nevile& Ford, 2006).
Sometimes, a person's lack of access is more of a temporalproblem: if an activity is taking place in one part of the world but welcomingonline participants, it can be a matter of where people are located thatdetermines the accessibility of the activity. It is not possible for everyoneto be participants in everything and have sufficient sleep and day-timeschedules for their local area. This location-based temporal factor means, formany people, difficulties in participating in educational, research,entertainment and financial opportunities that support international equity.This and other issues are considered further in ' Location and Access: IssuesEnabling Accessibility of Information' (Nevile & Ford, 2006).
So, again, there are functional accessibility requirementsthat can flow simply from where one is at the time.
Content discipline considerations
Some types of information present particular problems ofaccessibility. Mathematics has depended upon graphical representation to makeit quickly accessible to mathematicians. They learn the symbolism and write andinterpret the mathematics with agility if they can see it.
Blind mathematicians have enormous difficulties: they haveto work with both the mathematical concepts and the very difficult encodingthat represents the mathematical content but is cumbersome and increases theircognitive task enormously. (). W3C has developed a language called MathematicsMarkup Language [MathML] for expressingmathematics for both presentation (graphically) and manipulation so that appropriatesoftware can be used to display mathematics on the screen, as one expects tosee it, but also to enable cutting-and-pasting of sections of mathematics asone does with text in a word processor.
Although the problem has been pretty well solved for thesighted mathematician, it remains a problem for the mathematician who wants touse Braille. The author and others have worked on the development oftransformation services that will enable blind Braille users to accessmathematics that is encoded correctly in MathML(
Spatial information and accessibility
Spatialinformation, now commonly available in multi-media forms, offers a specialchallenge to those who want everyone to be able to enjoy their information. Notonly is there the standard range of problems, such as how does a blind personget access to the information in a map (an image), or how do they participatein an interactive walk-through of a building, but there is the special natureof information to consider. For professionals, the problem is usually differentfrom the one of everyday users. Experts who work in areas such as spatialsciences, usually can work with text and make sense of it: databases containingnumbers are useful as representations of information and they can beinterpreted and used with standard database techniques, so blind people, forexample, can learn to use these alternative formats. But people who are notblind, but for now have their eyes-busy, do not have this training. Noteveryone who can see reads a map well, as we know. Some people like to picturethe information about the route to the beach by thinking of the land marks,others by using the compass and still others perhaps by remembering the namesof streets or the number of them. Maps allow such people to read off what worksfor them, in most cases. But now that people are walking around with hand-helddevices, and the maps are often very small, or they need the information withouthaving to look, we have to find ways for the speech output devices to representthe information. We have to work on the variety of ways in which people mightunderstand spatial information, to find new representations that will work forthem. This is a known current challenge, and the field of multi-mediacartography is engaged with it (Nevile & Ford, 2006).
There are now a growing number of cybercartographers whoare trying to re-invent cartography in the era of digital information (Taylor,2006). Their focus is on what people can do with digital informationand how this might lead to new forms of maps. In a similar way, there is workto be done to see how people with disabilities might benefit from thetransition to digital data.
Accessible resources
In order to decide what to read and when, especially whenreading a newspaper, most users with visual abilities look for headings ofsections and then choose what is of interest. In publications where this is tohappen, headlines play a significant role in the overall presentation of thecontent. Where the headings are clearly such, the visual reader scans theheadings and can even get clues as to their relative importance, usually fromtheir size. A page from the New York Times provides a good example (Figure???).
Figure ???: New York Times Online (
Where adaptive or assistive technologies provide additionalhelp for users, such as by providing an overview of the content of the page,the structure can be marked for presentation in other ways, as illustrated byHuman Factors International (Figure ???). On the left is a browser-generatedtable of contents from a Web page laid out using correct HTML headingstructure, and on the right, a blank browser-generated table of contents fromthe same page that was marked up but using paragraphs and 'direct format' fontelements to produce "headings" that were to be identified only byfont size.

The following example of accessibilityavailable on the Web (Figure ???) is a Macromedia Flash movie with closedcaptioning, played in Real Player
(requires Real Player version 7+),
and accompanied by a text transcript. It is madeavailable in this form with a number of redundant pieces to ensure thenecessary combinations are available to be assembled according to needs: theFlash movie, the captions and the file that synchronises them with the movieand the transcript. The last will be useful to anyone who wants to access thecontent using Braille or who cannot hear what is being played audibly or evenjust someone who cannot keep up with the pace of the movie.
Bob Regan (
It offers captions for the video, and detailed variationsaccording to the access device being used (see
Examples of accessibility
UK Government Accounting offers an interesting collectionof information at its site (Figure ???). The information is available as PDFsto be printed but also in electronic form so that additional features can bemade available. Among other things, as they say:
Theelectronic version of Government Accounting 2000 enhances the print version byincluding a keyword search, hyper-links to related sections, pop-up definitionsfor Glossary terms, and easy-to-use navigation through the pages. The productnow includes the ability to personalise font sizes as required. ... (
Figure ???: UK Government Accounting Web Page
It is worth noting that this site, which uses frames whenpresenting the CD contents online, checks to see if the user wants framesbefore delivering them, and makes provision for those who don't, but it doesnot do the same for Javascript, on which it relies. A user who does not haveJavascript receives a blank page. Also, it is difficult for a user who adjuststhe page and then wants to find it in its adjusted form some time later becausethere is no way to identify the page other than by the generic file from whichit is generated (that is, it lacks a persistent link).
Human Factors International (
| Inaccessible | Accessible |
|
|
|
| The inaccessible Web page illustrated in the first column is representative of much current practice on the Internet. Graphics were used for some of the text, and tables were used to provide layout. Clear blank images were used to help stabilize the layout. HTML structural syntax is ignored. The page HTML is invalid. | The accessible page illustrated in the right column is constructed using text for all text elements, a single image for the one needed graphic. Standard HTML elements were used to construct the page - headings, paragraphs and definition lists in this case. Additional information was also coded into the page to provide some additional information to the listener. The page was validated against the HTML 4.01 standard |
| Figure ???: Demo of two pages - sight vs sound differences (HFI-chocolate, 2005). | |


Although the pages appear visually to be much the same,they are very different for a screen reader.
HFI provide two audible renderings in mp3 format (others arealso available):
screen reading ofinaccessible page and screen reading ofaccessible page.
A simple way to render an inaccessible page accessible isto provide a reading of the page. This would not solve all accessibilityproblems for all potential users, but it may solve it for many users. Thus, byproviding a sound file of a reading of the text and description of the image,or even a text file where the text is transformable, the content of the pagecould be made available to a large number of potential users who mightotherwise not be able to access it. As this page does not appear to have links,such a simple solution would be useful but only if the user could find thealternative version they want. This means the new file, wherever located,should be described and entered in the same catalogue of resources as theoriginal, as an alternative for the original, and so discoverable by a userwith the need for a non-visual version. The alternative approach to dealingwith an inaccessible page, working to make it universally accessible, requiresthe cooperation of the page owner and, unfortunately, often considerable skill,if it is possible at all.
Captions
Captions are familiar to many in the form of sub-titles forfilms, and becoming more common in other circumstances.
ClosedCaptioning: Closed captions are all white uppercase (captial) letters encasedin a black box. A decoder or television with a decoder chip is necessary toview them.
OpenCaptioning: (subtitling). The captions are "burned" onto thevideotape and are always visble [sic] -- no decoder is needed. A wide varietyof fonts is available for open-captioning allowing the use of upper andlowercase letters with descenders. The options for caption placement are great,permitting location anywhere on the screen. Open Captions are usually whiteletters with a black rim or drop shadow. The Captioned Media Program requiresOpen Captioning. ...
OpenCaptioning covers many nuances and subtleties. The Guidelines are the key tomaking knowledge, entertainment and information accessible to the deaf and hardof hearing, to those that are seeking to improve their reading and other literacyskills, and to those that are learning to speak English as a second language (
In particular, captions provide an excellent example of themany accessibility techniques that make resources more accessible and useful ingeneral. That is, like curb-cuts, they make a huge difference to some but arethen found to have many other uses for the general population.
Structure
It is important to many users that content is properlystructured. The most obvious issue is when a major heading is simply renderedin large or coloured print, and then a less important one is in a smaller fontsize. This is correctly done when the headings are marked as such, showingtheir ranking as 1, 2 etc..
One way to fix this problem is to reform the original pageusing the correct markup for the headings but one does not always have accessto the original: the owner may not be interested, or it may be difficult tocontact them, or impossible for some other reason. Providing a simple list ofthe contents, with links to specific parts of the page, can be done byannotation of the original page, where the annotations are stored elsewhere andthen applied to the page upon retrieval before it is served to the user(Kateli, 2006). A less ambitious supplement to the page would be a list of thecontents so that at least the user would know what to look for. Either way, thesupplementary content is needed to be discovered and associated with theoriginal content, whether by the user's agent or the content server orotherwise.
Quantifying the accessibilitycontext
For many years, Microsoft showed its skepticism foruniversal accessibility including by its lack of effort to make its InternetExplorer browser UAAGconformant. In 2003, however, Microsoft commissioned a study in the US to getsome indication of who might be needing assistance with accessing informationif they are to use computers or other electronic devices (
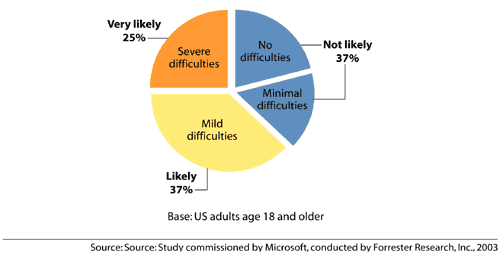
Further, they found (Figure ???) that:
Visual,dexterity, and hearing difficulties and impairments are the most common typesof difficulties or impairments among working-age adults:
• Approximately one in four (27%) have a visual difficulty or impairment.
• One in four (26%) have a dexterity difficulty or impairment.
• One in five (21%) have a hearing difficulty or impairment.
Somewhatfewer working-age adults have a cognitive difficulty or impairment (20%) andvery few (4%) have a speech difficulty or impairment.
... For thetop three difficulties and impairments:
• 16% (27.4 million) of working-age adults have a mild visual difficulty orimpairment, and 11% (18.5 million) of working-age adults have a severe visualdifficulty or impairment.
• 19% (31.7 million) of working-age adults have a mild dexterity difficulty orimpairment, and 7% (12.0 million) of working-age adults have a severe dexteritydifficulty or impairment.
• 19% (32.0 million) of working-age adults have a mild hearing difficulty orimpairment, and 3% (4.3 million) of working-age adults have a severe hearingdifficulty or impairment (
or as shown (Figure ???):
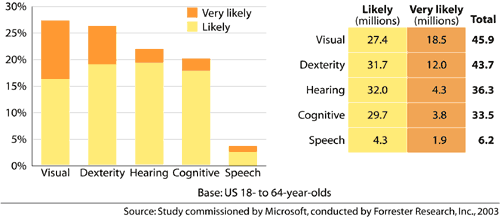
Thesefindings show that the majority of working-age adults are likely to benefitfrom the use of accessible technology. As shown in the chart in Figure [???],60% (101.4 million) of working-age adults are likely or very likely to benefitfrom the use of accessible technology.
The chart inFigure [???] also shows the percentages of working-age adults who are likely orvery likely to benefit from the use of accessible technology due to a range ofmild to severe difficulties and impairments:
• 38% (64.2 million) of working-age adults are likely to benefit from the useof accessible technology due to a mild difficulties and impairments.
• 22% (37.2 million) of working-age adults are very likely to benefit from theuse of accessible technology due to a severe difficulties and impairments.
• 40% (67.6 million) of working-age adults are not likely to benefit due to ano or minimal difficulties or impairments (
or as shown in Figure ???:
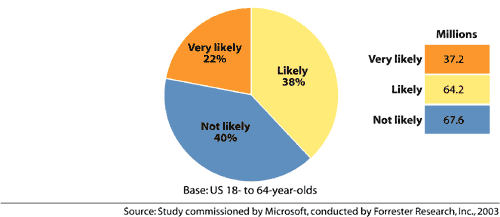
Figure ???: Likelihood of difficulties by population (
The report states:
The factthat a large percentage of working-age adults have difficulties or impairmentsof varying degrees may surprise many people. However, this study uniquelyidentifies individuals who are not measured in other studies as"disabled" but who do experience difficulty in performing daily tasksand could benefit from the use of accessible technology.
Note thatmany or most of the individuals who have mild difficulties and impairments donot self-identify as having an impairment or disability. In fact, thedifficulties they have are not likely to be noticeable to many of theircolleagues. (Microsoft,2003b)
Three more sets of figures provide the incentive to thinkcarefully about accessibility in the general population:
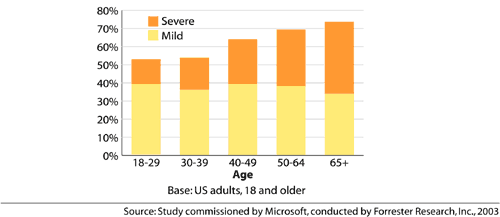
Figure ???: Difficulties by severity (
Together, Figures ???,??? and ??? paint a picture for theUS that looks grim. There is clearly a worrying trend towards much higherproportions of the community being much older than at present, and thereforemore likely to be at risk of disability.
There is every reason to assume the figures will be similarin Australia.
In summary, the Microsoft report claims:
In theUnited States, 60% (101.4 million) of working-age adults who range from 18 to64 years old are likely or very likely to benefit from the use of accessibletechnology due to difficulties and impairments that may impact computer use.Among current US computer users who range from 18 to 64 years old, 57% (74.2million) are likely or very likely to benefit from the use of accessibletechnology due to difficulties and impairments that may impact computer use. (
This points to the fact that not all those who couldbenefit from computer use, do use computers. There are many reasons for this,but as the trend to publish becomes electronic and the younger people adopt thetechnology, the evidence above suggests there is going to be an increasingproblem unless accessibility is also rapidly increased.
While Microsoft was working to convince, or otherwise,itself of the need to pay attention to accessibility issues,
In the USand Canada there are:
45+ millionpeople with literacy problems (source :U.S. Nat'l Literacy Survey 1992)
10-15% of the population with a learning disability (source: NationalInstitutes of Health)
18% of the population over age 5 for whom English is a second language (USCensus Bureau 2002)
13+% of children aged 3-21 who receive special education (source:
12% of the Canadian population with some type of disability (source: StatisticsCanada)
22% of Canadians who are functioning at the lowest literacy level (source:Statistics Canada)
[BrowseAloud]
as justification for their product BrowseAloud. BrowseAloudis a service that can be offered by a Web site to provide streamed readingaloud of the content of the site, assuming it is properly constructed.
In 2006, the US NationalCouncil on Disability released a policy paper that explores key trends ininformation and communication technology, and highlights the potentialopportunities and problems these trends present for people with disabilities.It suggests some strategies to maximize opportunities and avoid potentialproblems and barriers. In particular,
Thefollowing are some emerging technology trends that are causing accessibilityproblems.
The report points out that technology in common use changesfast and unpredictably with the result that "assistive technologydevelopers cannot keep pace". They cite convergence and competitivedifferences as having "a negative effect on interoperability between ATand mainstream technology where standards and requirements are often weak ornonexistent". The rapid increase in the number of aging people who havenaturally increasing disabilities is, of course, always a concern.
On a more positive note, the NCD report summary lists anumber of technological advances and says:
Thesetechnical advances will provide a number of opportunities for improvement inthe daily lives of individuals with disabilities, including work, education,travel, entertainment, healthcare, and independent living.
It isbecoming much easier to make mainstream products more accessible. Theincreasing flexibility and adaptability that technology advances bring tomainstream products will make it more practical and cost effective to buildaccessibility directly into these products, often in ways that increase theirmass market appeal. (
Accessibility as Economic Advantage
In 1998, the US Federal Government legislated in favour ofaccessibility of digital resources including applications when the US federalgovernment is procuring content, systems or services [
Fairfax in Australia, however, has perhaps offered a similarlystriking economic reason for being concerned about accessibility. In 2003, theyredeveloped their Web site with accessibility in mind and the result is asaving of an estimated $1,000,000 per year in transmission costs. In a 2004presentation for the Web Standards Group [
Who we are
· Fairfax Digital
§ 135 million PI's permonth
§ 6 mill uv's
§ The leading News sitesin Australia
§ 3 to 4 minute averagesession times
What we did
· moved our biggest sitesacross in a 6 month timeframe
· the smoothest rollout wehave ever experienced
· will save a million $ inbandwidth a year
Where we'reat now
· First major AUSpublisher to make the move to CSS/xhtml
· started publishing incss/xhtml in nov 2003
· will move all sitesacross in the next 6-9 month (
In 2003, a surprisingly high proportion of the
The Authoring Tools Accessibility Guidelines [
Chapter 4: Universal design
Introduction
Work on making computer text 'accessible' had started atleast by the early 1990's and the processes being advocated then are the basefor what is used today. The term accessible has already been described. Here,the history of the effort is presented briefly. Then the emergence of the W3Cand later, in 1997, the Web Accessibility Initiative is described in so far asthe history is relevant. What are now known as the Web AccessibilityInitiative's guidelines for accessible content, and published by W3C, startedlife before either the Web or W3C was significant in the field. They, like somany other things that happen, have historical roots that possibly help explainwhy they are as they are. The work of those responsible for authoring andrecommending the guidelines, the W3C WAI Working Groups, is considered in somuch as it is relevant and then the guidelines themselves are introduced.
The significance of the guidelines in this context is nothow comprehensive or effective they are, but rather how they are determined andthe role they play in stimulating technology development by allowing for thegeneralisation of specific accessibility problems.
The early-history of accessibility
In 1994, in the abstract to "Document processing basedon architectural forms with ICADD as an example", the authors wrote:
ICADD(International Committee for Accessible Document Design) is committed to makingprinted materials accessible to people with print disabilities, eg. people whoare blind, partially sighted, or otherwise reading impaired. The initiative forthe establishment of ICADD was taken at the World Congress of Technology in1991. (Harbo et al, 1994)
Earlier in the article they describe the mission of ICADDas:
The ambitionof ICADD is that documents should be made available for people with printdisabilities at the same time as and at no greater cost than they are madeavailable to people who can access the documents in traditional ways (usuallyby reading them on pages of paper). This ambition presents a significanttechnological challenge.
ICADD hasidentified the SGML standard as an important tool in reaching their ambitiousgoals, and has designed a DTD that supports production of both"traditional" documents and of documents intended for people withprint disabilities (eg. in braille form, or in electronic forms that supportspeech synthesis).
It should be noted that the proposed way of making thematerials available was to use SGML, the predecessor of HTML that was the firstand has remained the main markup language for the Web.
After WWW94, Dan Connolly (
Oneinteresting development is that right now, HTML is compatible withdisabled-access publishing techniques; i.e. blind people can read HTMLdocuments. We must be careful that we don't lose this feature by adding toomany visual presentation features to HTML.
It might be noted that this early conference was heldbefore the World Wide Web Consortium was formed. Yuri Rubinski was at thatearly conference at CERN. He, as an ICADD pioneer, had been involved in makingsure that SGML could be used for other than standard text representations andhe and his colleagues did not want their work to be lost in the context of thenew technology, the fast emerging Web. A year later, at WWW4 in Boston inDecember 1995, Mike Paciello, another ICADD pioneer, offered a workshop called"Web Accessibility for the Disabled".
Meanwhile, the World Wide Web Consortium [
It is timeto seek new paradigms for how people and computers interact, the committeesaid. Current computer systems, which arose from models conceived in the 1960sand 1970s, are based on the concept of a single user typing at a computingterminal. These systems have limitations, however. For example, using manyapplications simultaneously can be awkward, and inefficiency can ensue whenmultiple users with different abilities and equipment try to access and work onthe same documents at the same time. No single solution will meet the needs ofeveryone, so a major research effort is needed to give users multiple optionsfor sending and receiving information to and from a communication network. Theprospects are exciting because of recent advances in several relevanttechnologies that will allow people to use more technologies more easily.
This is atime when tremendous creativity is required to take advantage of the vast arrayof new technologies coming forth, such as virtual reality systems and speechrecognition, eye-tracking, and touch-sensitive technologies," saidsteering committee chair Alan Biermann, chair of the Levine Science ResearchCenter at Duke University, Chapel Hill, N.C. "But the point remains thatwe are still using a mouse to point and click. Although a gloriously successfultechnology, pointing and clicking is not the last word in interface technology.
The reportencourages both government and industry to invest in research on the componentsneeded to develop computing and communication networks that are easy to use.Applying studies of human and organizational behaviors to lay the groundworkfor building better systems will be very important to these efforts. Newcomponent designs also should take into account the varied needs of users. Peoplewith different physical and cognitive capacities are obvious audiences, butothers would benefit as well. Communication devices that recognize users'voices would help both the visually impaired as well as people driving cars,for example. It is time to acknowledge that usability can be improved foreveryone, not just those with special needs.
And later:
The reportdraws from a late 1996 workshop that convened experts in computing andcommunications technology, the social sciences, design, and special-needspopulations such as people with disabilities, low incomes or education,minorities, and those who don't speak English (
It should be noted that the steering committee includedGerhard Fischer and Gregg Vanderheiden, both already champions of the need foraccessibility of electronic media.
The Committee wrote about research as helping withuniversal access:
This willcomplement government policies that address economic and other aspects ofuniversal access. Federal agencies should encourage universal access to the NIIby supporting research and requiring adequate development and testing ofsystems purchased for use at public service facilities (
Very soon after this report was released, in October 1997,a press release was issued by the American National Science Foundation. Whatfollows is from the archived version of it:
The NationalScience Foundation, with cooperation from the Department of Education'sNational Institute for Disability and Rehabilitation Research, has made athree-year, $952,856 award to the World Wide Web Consortium's Web AccessibilityInitiative to ensure information on the Web is more widely accessible to peoplewith disabilities.
Informationtechnology plays an increasingly important role in nearly every part of ourlives through its impact on work, commerce, scientific and engineeringresearch, education, and social interactions. However, information technologydesigned for the "typical" user may inadvertently create barriers forpeople with disabilities, effectively excluding them from education, employmentand civic participation. Approximately 500 to 750 million people worldwide havedisabilities, said Gary Strong, NSF program director for interactive systems.
The WorldWide Web, fast becoming the "de facto" repository of preference foron-line information, currently presents many barriers for people withdisabilities.
The WorldWide Web Consortium (W3C), created in 1994 to develop common protocols thatenhance the interoperability and promote the evolution of the World Wide Web,is working to ensure that this evolution removes -- rather than reinforces --accessibility barriers.
NationalScience Foundation and Department of Education grants will help create aninternational program office which will coordinate five activities for Webaccessibility: data formats and protocols; guidelines for browsers, authoringtools and content creators; rating and certification; research and advanceddevelopment; and educational outreach. The office is also funded by the TIDEProgramme under the European Commission, by industry sponsorships and endorsedby disability organizations in a number of countries.
I commendthe National Science Foundation, the Department of Education and the W3C forcontinuing their efforts to make the World Wide Web accessible to people withdisabilities," said President Clinton. "The Web has the potential tobe one of technology's greatest creators of opportunity -- bringing theresources of the world directly to all people. But this can only be done if theWeb is designed in a way that enables everyone to use it. My administration iscommitted to working with the W3C and its members to make this innovativeproject a success" (
Things had moved very quickly behind the scenes. W3C hadworked through its academic staff to gain the NSF's support for the project andpolitically manoeuvred the launch into the public arena with the support of anewly appointed W3C Director and the President of the US.
Mike Paciello describes the history thus:
The WorldWide Web Consortium (W3C) have consolidated previously written accessibilityguidelines from a range of organisations (Lazzaro, 1998). Principally this workwas initiated by Mike Paciello, George Kerscher and Yuri Rubinsky who cofounded the International Committee for Accessible Document Design (ICADD).ICADD established standards for accessible electronic information (ISO 1208-3and ICADD-22) the forerunners of the WAI guidelines. Whilst Mike Paciello wasthe Executive Director of the Yuri Rubinsky Insight Foundation from 1996-1999he was responsible for developing and launching the Web AccessibilityInitiative (
Sadly, Yuri Rabinsky died in 1995. Gregg Vanderheidenbecame the Co-Chair of the Web Content Accessibility Guidelines Working Group,and Mike Paciello, long expected to have become the director of the W3Cinitiative, went elsewhere when Judy Brewer was appointed to that position.
Another significant player in this history was JuttaTreviranus. She had been working with Yuri Rabinsky at the University ofToronto and quickly emerged, with her colleague Jan Richards, as an expert whocould lead the development of guidelines for the creation of good authoringtools. In a paper entitled "Nimble Document Navigation Using AlternativeAccess Tools" presented at WWW6 in 1997, she argued that:
Due to theevolution of the computer user interface and the digital document, users of screenreaders face three major unmet challenges:
1.
2.
3.
She further stated that:
Thesechallenges can be addressed by modifying the following:
· the access tool (i.e.,screen reader, screen magnifier, Braille display),
· the browser,
· the authoring tools,(e.g., HTML, SGML, plug-in, Java, VRML authoring tools),
· the HTML specifications,HTML extensions, Style Sheets,
· the individualdocuments, and
· the operating system (
Treviranus was already the Chair of the Authoring ToolsAccessibility Working Group for W3C, and has been ever since. Clearly, theprinciples of the ICADD developments were on their way into the W3C guidelines.
With the appointment of Wendy Chisholm as a staff member atW3C, the work of TRACE, her former employer and the laboratory of GreggVanderheiden (co-chair of WCAG Working Group), the Wisconsin-based researchers,contributed significantly to W3C's WAI foundation. Judy Brewer, the Director ofW3C responsible for WAI, was not herself an expert in content accessibility atthe time but strong in disability advocacy.
The W3C guidelines were already crawling by the time theyentered the W3C process.
Separation of Structure andPresentation
W3C WAI inherited, from ICADD's ISO 1280-3 and laterstandards, the architecture of documents where a Document Terms Definition(DTD) document was used to describe the structure of the document in a commonlanguage, or a language that could be mapped to a common terminology, but the styleapplied to those structural objects could be set any number of times by adesigner. Presentation could, and should, be separated from content, as theslogan goes.
ICADD isaware that it is unrealistic to expect document producers and publishers to usethe ICADD DTD directly for production and storage. Instead a "documentarchitecture" has been developed that permits relatively easy conversionof SGML documents in practically any DTD to documents that conform to the ICADDDTD for easy production of accessible versions of the documents. ...
The approachof ICADD is interesting, not least because it illustrates that documentportability and exchange in SGML can be achieved by other means thanstandardizing on a single DTD in the exchange domain. In ICADD, portability isachieved by specifying mappings onto a standardized DTD. (
This is an important article for its explanation of how,given an architecture for markup, a single application can be used to read themarkup and present the content in different ways according to instructionsabout how to present each type of content. This was the state of the art in1994.
The article further explains:
Therelatively new international HyTime standard (ISO 10744) introduced the notionof architectural forms. With architectural forms, SGML elements can beclassified by means of #FIXED attributes as belonging to some class. In HyTime,architectural forms are used as a basis for processing hypermedia documents,but their use is not limited to that.
With good foresight, the authors note the good and badfeatures of ICADD and then, in their conclusion, say:
Still, theapproach chosen by ICADD does seem to be a good one, despite its lack of fullgenerality. The problem that ICADD faces is not only technical, it is alsopolitical and organisational. Improving access through the use of the ICADDintermediate format will only happen if information owners and publisherschoose to support it; ICADD depends on the DTD developers to specify themapping onto the ICADD tag set. By using architectural forms for thespecification, ICADD reduces the perceived complexity of specificationdevelopment; and the same time this development - by having the specification bephysically part of the DTD - it is stipulated to be an integrated part of theDTD development itself, thus presumably increasing the chances of support fromthe DTD developers.
What they said of ICADD seems to have accurately predictedwhat would happen to Web content markup in the next decade. What is nowobvious, is that the influence of the early solutions and players was going toprove dominant and the SGML solutions would be, in some ways, taken forgranted, and even possibly act as a constraint in the future.
More media, same accessibility
It was but a short step to take the ICADD architecture intothe Web world, as happened with the introduction of styles, machine-readablespecifications for the presentation of structural elements in a Web page. HypertextMarkUp Language (HTML) was the same kind of language as SGML, although farsimpler and, like SGML, referred to a DTD. What had happened in the process ofgoing from the early use of computers to the Web was the introduction of theextensive use of multimedia, particularly graphics, and so HTML needed to beadjusted with element attributes that would stem the flow from inaccessibilityback towards some kind of accessibility. The challenge became not one ofmaintaining the mono media qualities, which had the qualities Connelly noted,but finding ways to support the proliferation of media without compromising theaccessibility.
A simple example is provided by the tag that shows wherethe inclusion of an image is required. The <img> tag needed an attributethat would provide those who could not see the image with some idea of what itcontained. Adding the <alt> attribute achieved this. Later, adding a newdocument element to be known as the <long desc> went further to providefor a full explanation of the image.
The idea was that the HTML DTD would specify the structuralelements that should be used and the content would be interpreted, according tothe provided styles, by the user agent, or 'browser' as it came to be known.What went wrong was that the browser developers were able to exploit this newtechnology to their advantage by offering browsers that could do more than anyother: competition among the browser developers led to constant fragmentationof the standard as they offered both new elements and new ways of using them.The browser battles continue although a decade later, for a variety of reasons,some browsers are appearing that adhere to the current standards.
But determining what the code should do at that level wasnot the only work of W3C WAI. The jointly-funded activity was to:
create aninternational program office which will coordinate five activities for Webaccessibility:
The WAI Requirements
As the Web gained popularity, it acquired more and moreusers for whom it was inaccessible. As Tim Berners-Lee pointed out in an earlypresentation of the Web (
WAI was positioned, then, to receive supplications from allsorts of users who were finding the Web inaccessible or people acting on theirbehalf. As an open activity, anyone could (and can) join the WAI Interest Groupmailing list and voice their opinion. This has been happening for more than tenyears and the list of problems is very long. In that time, many obviousproblems were determined early and the more difficult ones, such as theidentifiable problems for people with dyslexia and dysnumeria, have emergedmore recently. Many have been repeated. They are generally classified into threetypes: problems to do with content, user agents and authoring tools and arechanneled towards the three working groups responsible for those areas.
The Working Groups are more focused than the Interest Groupand now have charters describing their goals, processes and achievement pointsthat help them prepare a recommendation for the Director of the W3C.Essentially, what they do is gather requirements and describe thoserequirements in generic terminology, aiming to make their recommendationsvendor and technology independent and future proof.
The Working Groups consist of experts who do what expertsdo, generalise and specialise. One might say, then, that the WAI Working Groupsare chartered to determine the relevant specialisations for consideration and togeneralise from them to define guidelines for accessibility.
The guidelines serve a number of purposes but a clear andspecific use of them is to ensure that all W3C recommended "data formatsand protocols" contribute to accessibility. The guidelines have themselvesassumed the role of data formats and protocols. They have been promoted tocontent creators in their raw form and this has required considerable supporteffort which may have been avoided if they had been subsumed into the formaldata formats and protocols and those had been the focus of promotion. This iswhat happened with HTML. The last version of HTML was amended to include theidentified accessibility features which now appear as attributes within HTMLVersion 4.1. EXtensible MarkUp Language (XML) soon replaced HTML as arecommendation from the Director of W3C and with the introduction of XML, moreaccessibility features were introduced. Despite the W3C Director'srecommendation that people should not continue to use HTML, it is still usedextensively.
(It is the author's opinion that in many institutions, themoney that might have been spent to pressure for better and cheaper authoringtools and to promote the replacement of old tools, instead of increasing thetraining of creators to use the now deprecated HTML in accessible ways. This isa tractable although difficult problem. Teaching content developers to use XMLis frightening to most and so it is not even tried even though in fact it canbe done almost without noticing if the right tools are used. The AuthoringTools Accessibility Guidelines, that have not been taken as seriously as thecontent guidelines, are designed to help make authoring tools that both areusable by people with disabilities and that produce content that is usable bypeople with disabilities. The point that is so often missed is that if authorsuse these tools, instead of the many non-conforming tools, without needing toknow very much they can produce very accessible content 'unconsciously'. Theauthor believes this would make a much bigger difference than has been the casewith the approach of trying to make all content developersaccessibility-skilled using bad tools and raw markup. The result is that HTMLcontinues to be used in its raw form and little has been achieved in the way ofincreased accessibility of the Web. This, despite the reality that the movefrom HTML to XML requires very little effort beyond using what was HTML 4.1correctly and ensuring that the right DTD is referred to and the tags are in lowercase!)
WAI Compliance and Conformance
W3C is a technical standards organisation and their work isdevoted to technical specifications. Whereas another type of organisationconcerned about accessibility might have worked on developer practices, andwhat practices should be encouraged within the industry and developercommunity, possibly with the pressure of 'ISO 9001' type certificationavailable, W3C has stuck to specifying technical output and been remarkablysuccessful in this process. The result is that many countries, in adoptinglegal support for accessibility, have also relied on the WCAG specifications,sadly almost always without reference to the authoring tools or user agentspecifications.
Conformance with general guidelines is not easily verified.and so the WCAG generalities have been reduced to specifics in each particularcase in order to be tested. The Working Groups who are responsible for thegeneralisations support this process by producing specific examples in order toclarify what they mean by their generalisations but, of course, these do notfit every situation and so are often not relevant or helpful. In general, theproblem is that all these things are subject to interpretation by people withmore or less expertise and personal bias. The working groups endeavour to writetheir recommendations in unambiguous language but, of course, this is notreally possible. The result is that conformance is not an absolute quality.
Conformance with formats and protocols is simpler. This isa machine determinable state but it depends upon the formats and protocolshaving correctly captured the requirements for its effectiveness. As the rangeof problems that users may have is infinite, it cannot be expected that theguidelines and associated re-defined formats and protocols will cover everypossibility for inaccessibility. There are also many requirements that are notcapable of such formal definition.
Special resources for people withdisabilities
Given the problems with accessibility, many developers havetried to avoid the problem by offering a 'text-only' version of their content.A major problem with this approach has been that the pages often get 'out ofsynch', with text-only pages not being updated with sufficient frequency.
But many people with disabilities do not want to be treatedas such: they want to be able to participate in the world equally with othersso they want to know what others are being given by a resource. They want aninclusive solution. They may prefer the idea of a universal resource - a onesize fits all solution that includes them. The Chair of the British StandardsInstitution's committee on Web Accessibility, Julie Howell (
The early objection to the text-only alternative on thepart of the developers disappeared when site management was given across tosoftware systems that were capable of producing both versions from a singleauthoring of content. This relies on a shift from client softwareresponsibility for the correct rendering of the resource to the provision ofappropriate components by authoring/serving software. What are called 'dynamic'sites respond to client requests by combining components in response to userrequests.
The motivation for accessibility often arises in acommunity of users rather than creators and so it is common to find a thirdparty creating an accessible version of a resource or part of the content of aresource. The production of closed captions for films is usually the activityof a third party, as is the foreign language dubbing of the spoken soundtracks. ubAccess has developed a servicethat transforms content for people with dyslexia. A number of Brailletranslation services operate in different countries to cater for the differentBraille languages, and online systems such as
The opportunity to work with third party augmentations andconversions of content is realised by a shift from universal design toflexible composition. Universal design has the creator responsible forthe various forms of the content while flexible composition allows fordistributed authoring. The server, in the latter case, brings together therequired forms, determined by reference to a user's needs and preferences.
For flexible, distributed resource composition, metadatadescriptions of both the user's needs and preferences and the content piecesavailable for construction of the resource are needed. The Inclusive LearningExchange [TILE] demonstratesthis. TILE uses the AccLIPand AccMD metadataprofiles to match resources to user's needs, with the capability to providecaptions, transcripts, signage, different formats and more to suit users'needs.
Flexible composition satisfies the requirements for theusers, allows for more participation in the content production which is a boonfor developers, and demands more of server technology. As noted elsewhere, thisis suitable for increasing accessibility but also has the benefit that itlimits the transfer of content that will not be of use to the recipient. Thistechnique also saves on requirements for client capabilities which is useful asdevices multiply and become smaller. Economically too, it seems to be a betterway to go (
In summary, the history of the text-only page has shownsome trends:
--------------------------------------------->
from universal design to flexible composition
--------------------------------------------->
from client responsibility for resource rendering to server responsibility
---------------------------------------------->
from centralised authoring to distributed authoring
---------------------------------------------->
from code-cutting designers to applications-supported designers
--------------------------------------------------->
from creator controlled content forms to user
demanded content forms
Universal design
At the time of writing, the authoritative version of theWCAG is "Web Content Accessibility Guidelines 1.0, W3C Recommendation5-May-1999" [WCAG]. Thereis a new version under development for which the idea of universal design ismaintained. The role of WCAG is still to support the developers as they choosewhat markup to use (of course, many of them are oblivious of the choices andtheir implications) and then to check that all is well.
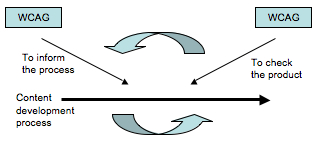
The role of the authoring tools and user agents guidelinesis to assure that the hopefully WCAG conformant content will be usable andfully functional.
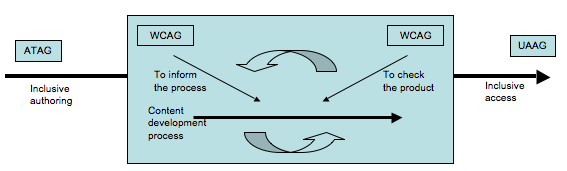
Universal Accessibility - the W3CApproach
There is no sense in which one would want to 'fault' thework of WAI in the area of accessibility.Like others, they have struggled to deal with an enormous and growing problemand everyone has contributed all they can to help the cause. Nevertheless, itis clear that the work of WAI alone cannot make the Web accessible. Althoughthere has been a lot written about the achievements of the universal accessapproach, that is not the topic but rather the context for the current work,and working to increase the effectiveness of the WAI work is a major goal.
The UK Disabilities Rights Commission Report
On 27/3/03, the UK Disabilities Rights Commission [
Significantly, this testing would not just be done bypeople evaluating the Web sites against a set of specifications, but they wouldalso involve 50 disabled people in in-depth testing of a representative sampleof the sites, testing in their case for practical usability. They claimed that,"This work will help clarify the relationship between a site’s compliancewith standards and its practical usability for disabled people." BertMassie, Chairman of the DRC, said: “The DRC wants to see a society where alldisabled people can participate fully as equal citizens and this formalinvestigation into web accessibility is an important step towards that goal.”
The DRC has legal power. As Mr Massie said: “Organisationswhich offer goods and services on the Web already have a legal duty to maketheir sites accessible. The DRC is committed to enforcing these obligations butit is also determined to help site owners and developers tackle the barriers toinclusive web design.” (
On 30 April 2003, Accessify carried the following report ofthe briefing for the DRC project:
I had alwaysthought that despite being labelled a 'formal' investigation, it would notcarry any real legal implications, and thankfully (for many people) this wasindeed the case. The term formal means that the DRC can carry out two types ofinvestigation - a named party or a general investigation, and it's the latterthat's taking place (a named party investigation would only apply to anorganisation that is repeatedly 'offending' and is put under investigation)....
So, it isn'ta 'naming and shaming' exercise. What exactly does it entail then? Well, theformat is basically this - 1,000 web sites hosted in Great Britain are going tobe tested using automated testing tools such as Bobby and LIFT. From thatinitial 1,000 a further 100 sites will undergo more rigorous testing with thehelp of 50 people with a varying range of disabilities, varying technicalknowledge and all kinds of assistive devices. This is not going to becentralised, so it will be interesting to see how the consistency ismaintained. However, some of the testing will be filmed (the usual usabilitykind of set-up) and a whole raft of data is going to need to be pulled togetherin some kind of presentable format. I don't envy Helen Petrie who has the taskof co-ordinating this!
The aim isto go beyond the simple testing for accessibility (although those original1,000 sites will only have the automated tests) - the notion put forward is"Accessibility for Usability" ... which to these ears sounds likeanother term for 'Universal Design' or 'Design For All'. I'm not sure Iappreciate the differences, if indeed there are any. It's certainly true thatgetting a Bobby Level AAA pass does not automatically make your siteaccessible, and it certainly doesn't assure usability. The interesting thingabout this study, in my opinion, is how clear the correlation is between sitesthat pass the automated Bobby tests and their actual usability as determined bythe testers. Will a site that has passed the tests with flying colours be moreusable? I suspect that the answer will usually be yes. After all, if you havetaken time and effort to make a site accessible, the chances are you have agood idea about the usability aspect. We will see ... (
Beyond establishing the proposed methodology, the DRCproject leader claimed that they would:
Developconcept of “Accessibility for Usability” (
A year later, after the report was released, OUT-Lawpublished an article about it (
Egg.com andOxfam.org.uk were among just five websites praised for their excellentaccessibility...
CityUniversity London tested 1,000 UK-based sites on behalf of the DRC... Itsfindings, released yesterday, confirmed what many already suspected: very fewsites are accessible to the disabled – albeit an inaccessible sitepresents a risk of legal action under the UK's Disability Discrimination Act.
However,while the report did not "name and shame" the 808 sites that failedto reach a minimum standard of accessibility in automated tests, CityUniversity has today revealed five "examples of excellence" from itsstudy:
HelenPetrie, Professor of Human Computer Interaction Design at City University,said: “The Spinal Injuries Scotland site highlights how an accessible websitecan be created on a small budget and still be lively and colourful.Additionally, Egg’s site shows larger firms can embrace accessibility withoutcompromising their corporate image or losing any sophistication from theire-services.”
Despitethese examples of excellence, the overwhelming majority of websites weredifficult, and at times impossible, for people with disabilities to access.
Petrieadded: “Web developers need to use the Web Accessibility Initiative (WAI)guidelines as well as involve disabled users to ensure web sites are usable forthese groups.” ...
In itsautomated tests, City University checked for technical compliance with theWorld Wide Web Consortium (W3C) guidelines. ...
Followingthe report from the DRC, co-written by City University, the W3C issued astatement "to address potential misunderstandings about W3C's [WebAccessibility Initiative or WAI] Guidelines introduced by certaininterpretations of the data."
This wasnot, however, a rejection of the DRC's study. In fact, the W3C has confirmedthat it welcomes the UK research. The potential misunderstanding came from thefact that, while 1,000 sites underwent automated tests, City University put 100of these sites to further testing by a disabled user group.
That groupidentified 585 accessibility and usability problems; but the DRC commented that45 per cent of these were not violations of any of the 65 checkpoints listed inthe W3C's Web Content Accessibility Guidelines, or WCAG.
The reportwas based on Version 1.0 of the WCAG – a version which has been aroundsince 1999. The W3C was keen to point out that the WCAG is only one of threesets of accessibility guidelines recognised as international standards, allprepared under the auspices of the W3C's Web Accessibility Initiative. ...
The W3Cexplained that in fact its WAI package addresses 95 per cent of the problemshighlighted by the DRC report. However, both the W3C and the DRC are keen topoint out that they are working towards a common goal: to make websites moreaccessible to the disabled.
User testing
OUT-LAWspoke to Judy Brewer, the W3C's Web Accessibility Initiative Domain Leader. TheWeb Content Accessibility Guidelines Working Group is currently working onVersion 2.0 of the WCAG which she hopes will be finalised next year, possiblyin the first quarter.
"Wewill be looking at the comments from the DRC report in our work on Version2.0," explained Brewer. "We have always said that user testing ofaccessibility features is important when conducting comprehensive testing ofweb site accessibility."
Sheacknowledged that the way Version 1.0 is written means that it can sometimes bedifficult to tell whether various checkpoints are satisfied. The plan, itseems, is to retain some concept of priority or conformance levels, withcriteria included which will make it easier for web developers to know thatthey have met them.
This changeof style should help: another recent study, by web-testing specialist SciVisum,found that 40 per cent of a sample of more than 100 UK sites claiming to beaccessible do not meet the WAI checkpoints for which they claim compliance.Brewer said this is not unusual: "We noticed that over-claiming a site'saccessibility by as much as a-level-and-a-half is not uncommon." SoVersion 2.0 should be more precisely testable.
The reasonfor the W3C statement on the DRC findings was, said Brewer, to minimise therisk that the public might interpret the findings as implying that they cannotrely on the guidelines.
CityUniversity's Professor Petrie told OUT-LAW: "Our report stronglyrecommends using the WCAG guidelines supplemented by user testing – whichis a recommendation made by W3C." She added that the University's data is"completely at W3C's disposal" for its continuing work on WCAGVersion 2.0.
Both the W3Cand the DRC are keen to point out that developers should follow the guidelinesfor site design – WCAG Version 1.0 – but they should not followthese in isolation: user testing, they both agree, is very, very important. (
Out-law's commentary is interesting because it takes acritical position with respect to the report and its relationship and commentson the W3C WCAG Version 1 and 2. These comments will be considered in moredetail in following chapters.
DRC Report findings
The
This reportdemonstrates that most websites are inaccessible to many disabled people andfail to satisfy even the most basic standards for accessibility recommended bythe World Wide Web Consortium. It is also clear that compliance with thetechnical guidelines and the use of automated tests are only the first stepstowards accessibility: there can be no substitute for involving disabled peoplethemselves in design and testing, and for ensuring that disabled users have thebest advice and information available about how to use assistive technology, aswell as the access features provided by Web browsers and computer operatingsystems. (DRC, 2004b, p. v)
The report authors tend to use the term 'inclusive design'rather than universal design.
They comment that:
Despite theobligations created by the DDA, domestic research suggests that compliance, letalone the achievement of best practice on accessibility, has been rare. TheRoyal National Institute of the Blind (RNIB) published a report in August 2000on 17 websites, in which it concluded that the performance of high streetstores and banks was “extremely disappointing” [
They further confirmed the lack of success in achievingaccessibility of Web sites by the introduction of the guidelines and the locallegislation. This time they were reporting on the state in the UK:
It is thepurpose of this report to describe the process and results of thatinvestigation, and to do so with particular regard to the relationship betweenformal accessibility guidance (such as that produced by the WAI) and the actualaccessibility and usability of a site as experienced by disabled users. Fromthat analysis, the report draws practical conclusions for the futuredevelopment of website accessibility and usability, and makes recommendationsdirected at the Government, at disabled people and their organisations, atdesigners and providers of assistive technology, at the developers of automatedaccessibility checking tools, at designers of operating systems and browsers,at website developers, and at website commissioners and owners. In this way, itis the intention of this report to help realise the potential of the Web toplay a leading part in the future full participation of all disabled people insociety as equal citizens. (DRC,2004b, p. 5)
The overall finding includes the comment that compliancewith the WAI guidelines does not ensure accessibility. Finding 2 contains thesub-point 2.2:
Compliancewith the Guidelines published by the Web Accessibility Initiative is anecessary but not sufficient condition for ensuring that sites are practicallyaccessible and usable by disabled people. As many as 45% of the problemsexperienced by the user group were not a violation of any Checkpoint, and wouldnot have been detected without user testing. (
The report goes on to describe many things that could bedone by humans including training of web content providers and web users,proactive efforts by people with front-line responsibility such as librariansand more.
Finding 5 states:
Nearly half(45%) of the problems encountered by disabled users when attempting to navigatewebsites cannot be attributed to explicit violations of the Web AccessibilityInitiative Checkpoints. Although some of these arise from shortcomings in theassistive technology used, most reflect the limitations of the Checkpointsthemselves as a comprehensive interpretation of the intent of the Guidelines. (
The level of compliance with the guidelines was amazinglylow, even given the common perception that compliance levels are not high:
In additionto the proportion of home pages that potentially passed at each level ofGuideline compliance, analyses were also conducted to discover the numbers ofCheckpoint violations on home pages. Two measures were investigated. The firstwas the number of different Checkpoints that were violated on a home page. Thesecond was the instances of violations that occurred on a home page. Forexample, on a particular home page there may be violations of two Checkpoints:failure to provide ALT text for images (Checkpoint 1.1) and failure to identifyrow and column headers in tables (Checkpoint 5.1). In this case, the number ofCheckpoint violations is two. However, if there are 10 images that lack ALTtext and three tables with a total of 22 headers, then the instances ofviolations is 32. This example illustrates how violations of a small number ofCheckpoints can easily produce a large number of instances of violations, afactor borne out by the data. (DRC,2004b, p. 23)
Analysis ofthe instances of Checkpoint violations revealed approximately 108 points perpage where a disabled user might encounter a barrier to access. Theseviolations range from design features that make further use of the websiteimpossible, to those that only cause minor irritation. It should also be notedthat not all the potential barriers will affect every user, as many relate tospecific impairment groups, and a particular user may not explore the entirepage. Nonetheless, over 100 violations of the Checkpoints per page show thescale of the obstacles impeding disabled people’s use of websites. (
The report contains many statistics about the speed withwhich the users were able to complete tasks in what is generally to beunderstood as usability testing. It showed, in the end, that usable sites wereusable and this, regardless of disability needs.
On page 31, there is some explanation of the results:
The userevaluations revealed 585 accessibility and usability problems. 55% of theseproblems related to Checkpoints, but 45% were not a violation of any Checkpointand could therefore have been present on any WAI-conformant site regardless ofrating. On the other hand, violations of just eight Checkpoints accounted foras many as 82% of the reported problems that were in fact covered by theCheckpoints, and 45% of the total number of problems (
After providing the details, the report continues:
Only threeof these eight Checkpoints were Priority 1. The remaining five Checkpoints,representing 63% of problems accounted for by Checkpoint violations (or 34% ofall problems), were not classified by the Guidelines as Priority 1, and socould have been encountered on any Priority 1-conformant site.
Furtherexpert inspection of 20 sites within the sample confirmed the limitations ofautomatic testing tools. 69% of the Checkpoint related problems (38% of allproblems) would not have been detected without manual checking of warnings, yet95% of warning reports checked revealed no actual Checkpoint violation.
Since automaticchecks alone do not predict users’ actual performance and experience, and sincethe great majority of problems that the users had when performing their taskscould not be detected automatically, it is evident that automated tests aloneare insufficient to ensure that websites are accessible and usable for disabledpeople. Clearly, it is essential that designers also perform the manual checkssuggested by the tools. However, the evidence shows that, even if this isundertaken diligently, many serious usability problems are likely to goundetected.
This leadsto the inescapable conclusion that many of the problems encountered by usersare of a nature that designers alone cannot be expected to recognise andremedy. These problems can only be resolved by including disabled usersdirectly in the design and evaluation of websites. (
The final statement here is most important. It is the mainthesis of the DRC Report that usability testing involving people withdisabilities is essential to the accurate testing of content.
An important finding of the report was the extremely lowlevel of accessibility of resources. It is explained:
The low rateof expertise identified, the lack of involvement of disabled people in thedesign and testing processes, and the relatively low use even of automatictesting tools contribute to an environment which makes the currently poor stateof Web accessibility inevitable. (DRC,2004b, p. 38)
What is significant here is that there is such a low rateof universal or, as Petrie says, inclusive accessibility.While this should not be taken as a sign of failure of those accessibilitygoals, it does suggest that there is a great need for more to be done, and thatit is unlikely to be done by the original content creators. This means thatthird party support should be enabled, and that is dependent on protocols toenable it.
In a sense, the Report places responsibility on the users:
Disabledpeople need better advice about the assistive technology available so that theycan make informed decisions about what best meets their individual needs, andbetter training in how to use the most suitable technology so they can get thebest out of it. (DRC, 2004b, p.39)
While this is a possible conclusion, it is asserted thatthe conclusion could equally have been that a better method of ensuring usersatisfaction should be developed. There is a general emphasis on responsibilityand training in many commentaries on accessibility. Many examples of calls fortraining of creators, for example, are similar to those within this report butperhaps this responsibility is misplaced. It is interesting to note also thatthe Report advocates more trust of users to select what they need and want(possibly represented by assistants).
If money is to be spent, the use of better authoring toolsmay prove cheaper than the training being advocated. And if users need to beserved better, perhaps removing the need for them to translate their own needsinto assistive technologies is somewhat more attractive.
It is hard to deny the conclusion that:
There is aneed to increase the availability of affordable individual expert assessments,but this must be complemented by appropriate signposting to such qualifiedspecialist organisations. That implies a requirement for the education of thosewho have prime responsibility for assessing the more general assistive technologyneeds of disabled people (such as occupational therapists, rehabilitationstaff, special educational needs coordinators, and Job Centre Plus staff), andof those who are likely to provide advice and training to disabled people (forexample, librarians, advisers in information bureaux, as well as professionalinformation and computer technology trainers and assistants). (
But the question might be about what is the role theseassistants should be trained to contribute. Perhaps training them to complete asimple questionnaire about their needs and preferences would be the easiest andmost effective use of training time. Of course, this would only be possible ifapplications acted on those needs and preferences, and this does mean serverimprovements. (Note that this issue is considered in some detail in chapter....)
The report suggests the very practical step of:
Thedevelopment of on-line user communities and the consequent development by usersof their own mutual support arrangements will usefully supplement individualassessments of this sort. (DRC, 2004b,p. 39)
But again this advice is based on a narrow definition ofusers that was the subject of the report, namely those with disabilities, asmade clear in the following extract:
Theinvestigation had three main purposes:
To evaluatesystematically the extent to which the current design of websites accessedthrough the Internet facilitates or hinders use by disabled people in England,Scotland and Wales
To analysethe reasons for any recurrent barriers identified by the evaluation, includinga provisional assessment of any technical and commercial considerations thatare presently discouraging inclusive design
To recommendfurther work which will contribute towards enabling disabled people to enjoyfull access to, and use of, the Web. (DRC,2004b, p. 46)
The Report's definition of users is implicitly limited bythe scope of the Report. Accessibility, in general, is a far broader issue witha wider scope. There is no way that there could be user groups of the kindsuggested by the Report that would cater for all the situations that account forinaccessibility. The various combinations of needs would not be different butidentification of classes of needs would be too difficult and the individualdifferences in needs and preferences would be lost in the process.
Responses to DRD Report
Petrie, the author of the DRD report, and others say:
Indeed,accessibility is often defined as conformance to WCAG 1.0 (e.g. [
They continue:
Thatcher[2004] expresses this nicely when he states that accessibility is not “in” aWeb site, it is experiential and environmental, it depends on the interactionof the content with the user agent, the assistive technology and the user. (
Kelly et al (
They argue that priorities must be set for each context andthat
This processshould create a framework for effective application of the WCAG without fearthat conformance with specific checkpoints may be unachievable orinappropriate. (
They provide an image of the wider context:
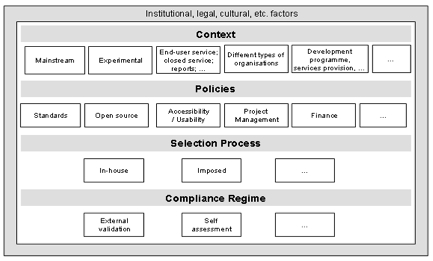
This framework offers one way of thinking about theproblems. But only a year later many of the same authors offered what they callthe 'tangram' approach (Chapter 5). Itshould be noted that the proposed AccessForAll approach assumes an operationalframework that can include any and all of these contextual issues.
Chapter summary
By 2008, it is an open question whether WCAG should be thefoundation of legislation for accessibility. This does not detract from itsrole as a standard for developers, but it suggests it is not a single-shopsolution. Kelly (
Theparticipants at the meeting agreed on the need “to call on the public sector torethink policy and guidelines on accessibility of the web to people with adisability“. As David Sloan, Research Assistant at the School of Computing atthe University of Dundee and co-founder of the summit reported in a articlepublished in the E-Government Bulletin “the meeting unanimously agreed the WCAGwere inadequate“.
In the next chapter, other ways of approachingaccessibility are considered.
Chapter 5: Other routes toAccessibility
Introduction
This chapter considers the shift from all responsibilityfor accessibility being on the resource developer to produce a single resource(with multiple components if necessary) that is accessible to all, according tothe WCAG specifications, to a situation in which responsibility is distributedamong many, including the creator, the server, the user, etc... It adopts theconcept of on-going inclusive practices and shows that there is a significantshift in current thinking to support this. It provides evidence of projectsthat support this view.
Beyond 'universal' accessibility
Van Assche et al (2006) stated the general problem succinctlyin terms of e-learning as follows:
Issues
The mainconcern for Accessibility Interoperability is to shift the focus from designfor disabilities to design for all. Now accessibility is very much design foraccess to single objects. A more holistic approach to accessibility ofequipment, services and learning opportunities could benefit all users, notonly persons with special needs. The WAI guidelines cover the syntacticalaccessibility, making it easy to test automatically if a web page conforms toaccessibility requirements. However, stimulating to "design to thetest" does not improve accessibility to learning. In addition, semanticand procedural aspects of electronic communication must be taken intoconsideration.
The mainchallenge is to stimulate the creations of alternatives instead of just having"cosmetic" transformations of digital resources. It is a stakeholdersconcern that some of the national legislation (e.g. Section 508 in the US)might block the development of more appropriate standards for accessibility oflearning technologies. It is also, according to the community of experts, adanger of premature standardisation.
Recommendations
1.
2.
Accessible code and accessibleservices
The authors of "Developing A Holistic Approach ForE-Learning Accessibility" (
Thesefindings seem depressing, particularly in light of the publicity given to theSENDA legislation across the community, the activities of support bodies suchas TechDis and UKOLN and the level of awareness and support for WAI activitiesacross the UK Higher Education sector. (
Unfortunately, these dismal findings have been replicatedin Australia (
But the thrust of the 'holistic approach' paper is that thereis more to accessibility than a technical analysis of conformance with WAIguidelines and that such things as blended learning may provide bettersolutions. Blended learning is learning that is not only technology based butincludes physical objects and the role of people such as assistants, maybefamily members. Jutta Treviranus, on the other hand, in her Keynote address atthe 2004 OZeWAI Conference [OZeWAI 2004],emphasised that there is an effort inCanada to use the technology, to exploit the artificiality of it and let itprovide for people according to their needs and preferences in ways that humansin the physical world have and often can not (Treviranus & Roberts, 2006).This position does not deny the possibility of human and physical help, but itdoes make strong demands on the technology for those situations in which it isinvolved.
There is no reason to follow one approach or the other butrather it is important to be aware of both. Within educational contexts in theUK, the 'SENDA' legislation requires reasonable accommodations to be made topromote inclusive learning. Kelly et al (
Kelly et al (
Kelly et al (
In ourholistic approach to accessible e-learning we feel there is a need to provideaccessible learning experiences, and not necessarily anaccessible e-learning experience.
but the point they make is valid in a wider context.
By 2006, Kelly and colleagues (

In a more recent exercise, Kelly and Brown (
Responsible for accessibility
In referring to the Australian legislative context fordiscrimination, Michael Bourk says:
In many wayspeople with disabilities represent different cultural groups. It is importantto develop an understanding of different world views in attempting to negotiatepolicies that accommodate their requirements as citizens and consumers. Thediscrimination legislation is written from a rights perspective that considersthe differences between impairment, disability and handicap. Confusion over thethree terms and their application abounds among policy makers and serviceproviders. Impairment refers to a temporary or permanent physical orintellectual condition. Disability is the restrictive effect on personal taskperformance that the surrounding environment places on people with impairmentsas a result of unaccommodating design or restricting structures. Handicaps arethe negative social implications that occur from disabling environments.Instead of focusing on the limitations of physical or intellectual impairments,a rights model of disability places the emphasis on the disabling effects of anunaccommodating environment that may reduce social status. People may neverlose their impairments but their disabilities and handicaps may be reduced withmore accommodating environments designed with and for them. (
Additionally, Bourk (
TheCommissioner accepted Telstra’s claim that it had no obligation to provide anew service as stated in s.24 of the Disability Discrimination Act. However,Wilson also accepted the counsel for the complainants [sic] argument that theywere not seeking a new service but access to the existing service that formedTelstra's USO:
In myopinion, the services provided by the respondent are the provision of access toa telecommunications service. It is unreal for the respondent to say that theservices are the provision of products (that is the network, telephone line andT200) it supplies, rather than the purpose for which the products are supplied,that is, communication over the network. The emphasis in the objects of theTelecommunications Act (s.3(a)(ii)) on the telephone service being"reasonably accessible to all people in Australia " must be taken toinclude people with a profound hearing disability. (
In other words, says Bourk, the case establishes it is theservice not the objects that must be accessible. He says:
[TheCommissioner]'s statement identifies the telephone service primarily as asocial phenomenon and not a technological or even a market commodity. Once asocial context is used as the defining environment in which the standardtelephone service operates, it is difficult to dispute the claim that all doesnot include people with a disability. In addition part of the service includesthe point of access in the same way that a retail shop front door is a point ofaccess for a customer to a shop. Consequently, the disputed service is not anew or changed service but another mode of access to the existing service. Itis the reference of access to an existing service that has particular relevanceto the IT industry. (Bourk,1998)
Bourk was writing as a student of Tom Worthington, anAustralian expert in accessibility and an expert witness in the Maguire v SOCOGaccessibility case (
In fact, the guidance notes for Australian regulations thatextend the Australian Disabilities Discrimination Act say:
There is aneed for much more effort to encourage the implementation of accessible webdesign; access to the Worldwide Web for people with disabilities can be readilyachieved if good design practices are followed. A complaint of disabilitydiscrimination is unlikely to succeed if accessibility has been considered atthe design stage and reasonable steps have been taken to provide access. (
While Australian legislation, for example, follows othersin using WCAG as the standard specifications for Web content encoding, it isclear that the test of accessibility is not just conformance to the guidelines.
Kelly et al (
The only wayto judge the accessibility of an institution is to assess it holistically andnot judge it by a single method of delivery. (
The summary of the US National Council on Disability's"Over the Horizon: Potential Impact of Emerging Trends in Information andCommunication Technology on Disability Policy and Practice" concludes withthe comment that:
"Pull"regulations (i.e., regulations that create markets and reward accessibility)generally work better than "push" regulations (i.e., regulationsrequiring conformance with regulatory standards), but both have a place in thedevelopment of public policies that bring about access and full inclusion forpeople with disabilities. Neither type of regulation works if it is not enforced.Enforcement provides a level playing field and a reward, rather than a lostopportunity, for those companies that work to make their products accessible.For enforcement to work, there must be accessibility standards that aretestable and products that are tested against them. (
The AccessForAll framework developed for descriptions ofaccessibility needs and preferences and of resource characteristics enables thedevelopment of tests (of descriptions of resources) that are far more objectiveand testable than the WCAG criteria. The latter have been shown to be bothfrequently misjudged and abused when negative results are likely to haveadverse ramifications. In addition, the WCAG criteria are not able to guaranteewhat they aim to achieve even if they are correctly evaluated. The AccessForAllframework does no more than identify the objective characteristics ofresources.
Correctable accessibility errors
Given the widespread faith in universal design and lowlevels of achievement, any resource that is repaired is likely to be done so'retrospectively'. This is not a well-structured technical term but rather onethat has simply become part of the vernacular of those working inaccessibility.
In "Evaluation and Enhancement of Web ContentAccessibility for Persons with Disabilities", Xiaoming Zeng (
Overwhelmingly, in most of the cases cited by Zeng, theproblems were associated with failure to give a text label to images or givingone that was not appropriate. He points, however, to an exception:
Romano’sstudy [2002] showed that the top 250 websites of Fortune listed companies arevirtually inaccessible to many persons with disabilities. Of the 250 sitesinvestigated, 181 of them had at least one major problem (priority 1) thatwould essentially keep the disabled from being able to use the site. While thestudy’s findings make it clear that even the best companies are not followingWCAG guidelines, most of the problems blocking access to the websites could beeasily identified and corrected with better evaluation methods (
The difference between a site that contains images thatlack proper description and sites that cannot be used at all is, of course,huge. Zeng's contention is that good reporting on evaluations would make iteasy for the site owners to correct the defects (
He goes on to work on numerical representations ofaccessibility, and develops his own, and later argues that with suitablesoftware, the major flaws in the pages can often be corrected 'on the fly' tomake the sites accessible in the broad sense, even if the images may lack adescription. Zeng's contribution is to provide a way of moving from theaccessible/inaccessible dichotomy which, as he argues, can cause a huge site tofail the test of accessibility when only one tag is missing while a smallersite can pass and be quite unusable. He limits the scope of his numericalevaluation to those features of accessibility that can be reliably testedautomatically (
Zeng argues for a numerical value for accessibility mainlyfor the convenience and machine properties it would have but he states:
Aquantitative numerical score would allow assessment of change in webaccessibility over time as well as comparison between websites or betweengroups of websites. Instead of an absolute measure of accessibility thatcategorizes websites only as accessible or inaccessible, an assessment usingthe metric would be able to answer the fundamental scientific question: more orless accessible, compared to what? (
He cites a number of other benefits such a number mighthave but he fails to convince the reader that a number would provide usefulinformation for making a site more accessible. If one is to judge a site,perhaps his system would give a fairer evaluation of a site than the existingand generally used checklist provided by WCAG, which is what people usuallyrefer to for the dichotomous evaluation. He calls his metric the 'WebAccessibility Barrier' score (
This approach is in line with that taken by theEuroAccessibility group leading to a smaller group's work for a quality mark.Again, the quality mark approach, however constructed, does not seem tocontribute to accessibility for the user, or access to resources that would beaccessible to the user if not to everyone. It might act as a motivation forcontent developers to be more careful about the accessibility of theirresource, but it is also a source of revenue for those few organisationscertified to evaluate sites (in some cases those who proposed the certificationscheme) and so there has been deep suspicion about it.
EuroAccessibility
In April 2004, the EuroAccessibility Workshop was held inCopenhagen and came up with an annotated draft of the original WCAG thatattempted to make it testable (
Earlier, in Paris in 2003, the following press release wasissued by the EuroAccessibility group:
Twenty three(23) European organisations from twelve (12) countries working in the field ofWeb Accessibility, together with the W3C/WAI (Web Accessibility Initiative), onMonday, April 28, 2003 have signed a Memorandum of Understanding (MoU) for thecreation of the EuroAccessibility Project. The MoU sets out governingprinciples for their co-operation towards the goal of establishing a harmonisedset of support services over Europe, which would include a common evaluationmethodology, technical assistance, and a European certification authority forWeb accessibility (EuroAccessibility, 2003).
One of the things they did was try to make WCAG testable:the plan from the April 30 2004 meeting was as follows:
| Explanation | Example |
| Take an original WCAG guideline | Guideline 1. Provide equivalent alternatives to auditory and visual content. |
| and the original WCAG checkpoints | 1.1 Provide a text equivalent for every non-text element (e.g., via "alt", "longdesc", or in element content). This includes: images, graphical representations of text (including symbols), image map regions, animations (e.g., animated GIFs), applets and programmatic objects, ascii art, frames, scripts, images used as list bullets, spacers, graphical buttons, sounds (played with or without user interaction), stand-alone audio files, audio tracks of video, and video. |
| and provide Clarification Points | A text equivalent (or reference to a text equivalent) must be directly associated with the element being described (via "alt", "longdesc", or from within the content of the element itself). It is not unacceptable for a text equivalent to be provided in any other manner i.e. an image being described from an adjacent paragraph |
| and testable statements | Statement 1.1.1: All IMG elements must be given an 'alt' attribute. Text: Related Technique: |
| | Statement 1.1.2: The appropriate value for the text alternative given to each IMG element depends on the use of the image. etc |
| and provide a list of terms used for a glossary. | |
Table ???: The unfinished plan to make WCAGtestable (EuroAccessibility, 2003)
There is no evidence the group managed to go much furtherthan to develop the statements before the group was disbanded due to lack offunding. in the current context, it is interesting to note that the group weretrying to find ways to insist that within a resource, any necessaryalternatives should be identified. This is also considered important forAccessForAll and shares the use of what might be called metadata. In the formercase, metadata would be embedded in the resource and in the latter it can beindependent of it. The practical difference is that the EuroAccessibilityapproach would not support third party, distributed or asynchronous annotationas easily as does the AccessForAll approach. Nor would it support thecontinuous improvement of the resource by the addition of accessiblecomponents, which is a major aspect of the AccessForAll approach.
The two approaches differ fundamentally, however, in thatthe EuroAccessibility approach was intended to make a judgmental statementabout the resource whereas the AccessForAll approach strictly avoids that.
In their original press release, the EuroAccessibilitygroup stated that:
· the W3C/WAI guidelines, which address accessibility ofWeb sites, browsers and media players, and authoring tools, may be promoted andimplemented differently in different countries,
· there is no harmonised methodology for theirapplication and for assessing the quality of Web sites,
· several "labels" are emerging over Europe,
· governmental organisations express the need of aguarantee of quality concerning Web accessibility,
· the Council Resolution on "eAccessibility" -improving the access of people with disabilities to the Knowledge Based Society(doc. 5165/03), under section II, paragraph 2, letter a, calls on the memberstates and invites the Commission "to consider the provision of an"eAccessibility mark" for goods and services which comply withrelevant standards for eAccessibility.
Consequently,the signatories want to join their efforts in order to:
There was a division of labour among the various members ofthe EuroAccessibility group and a small group received funding to pursue theirideas as the CEN/ISSS WS/WAC developing a "CWA on Specifications for aComplete European Web Accessibility Certification Scheme and a Quality Mark"(
There was, at the time, significant concern with respect tothe EuroAccessibility work after the group had split. It was suspected that themotivation for the work was not simply improving the accessibility of the Web,but also the creation of an industry, in circumstances when there was doubtabout the value of such an industry and fear it might actually stifle better work.Such concerns were notified informally to the CEN process (ref) and discussedinformally in many other contexts.
In 2003, there was a general struggle with the question ofwhat could be done to improve the accessibility of the Web. This was documentedin a note to the Australian Standards Sub-Committee IT-019 (
A Practical Approach
Given the problems with accessibility, a number of thoseconcerned started to find ways to accept the failures of the creators and thinkabout what could be done given an inaccessible resource. While many resourcedevelopers were still being encouraged to make their own resources moreaccessible, and this will continue hopefully, the problem of how to repairresources without access to the original files and servers became important.
Currently, there is a substantial 'industry' engaged in theproduction of what are called 'alternate formats' or 'alternative formats'.These are materials that have been published in an inaccessible form that areconverted for particular users, for example, for students at a university. Theneed for this work is probably increasing as the number of students requiringspecial versions of content increases. It is not, however, what in thisresearch is known as post-production techniques for increasing theaccessibility of resources but it could be.
The conversion of resources into alternate formats isusually done on a case-by-case basis, and is subject to copyright in manycases. For this latter reason, it is not within the focus of the researchbecause the copyright law limits this activity to cases where a student isregistered as having a medical or permanent disability and therefore qualifiesfor special resource conversions. When the resource is converted, it issupposed to be registered with Copyright Austyralia if it is otherwise subjectto copyright, but it seems from anecdotal evidence presented in 2007 (ref is LaTrobe conf) that many resources are not properly registered because it is acumbersome process and those responsible try to avoid engaging in it. Whatheppens when a resource is so registered is that it becomes discoverable forother users with permission to use such a resource in an alternate format. Thismeans that there is metadata about the alternative, and so it could bedescribed or its existing description probably could be converted, to provideAccessForAll metadata but even if this were so, it would only be available forsome users.
What is of particular interest in the research is thedevelopment of automatic conversions or adaptations that can be used by anyone,following the principles of inclusion. This means resources that haveadditional formats made available post-production, and in a way that makes thealternatives available to all who might need them. Sometimes this happenson-the-fly, whereby the original resource is converted on request, and sometimesit happens with the alternative being stored in some static form and availablefor users who need it some time in the future. The difference for the researchpurposes is not relevant: it is either a service or a resource that is beingoffered to the user, but the result is the same. What is important is that theservice or new resource is discoverable and the research argues this ispossible if it is described using appropriate metadata.
Relevant post-production servicesand libraries
there will be a list of these with a brief description ofthe services or resources they offer.
ubAccess ...
Richard Ladner ...
Vision Australia ...
WebAIM ...
Chapter summary
This chapter has shifted the focus from universalaccessibility of individual resources to accessibility to individual users,based on a copmbinatioon of effort including both human and machine input.
STOP PRESS!!
IBM launchedon Tuesday an application that seeks to harness the power and time of Internetusers around the globe to make the Web more accessible to the visuallyimpaired....
Using thenew IBM software users can report these problems to a central database and askfor additional descriptive text to be added to a site. Other Internet usersthat want to contribute can then check the database, select one of thesubmitted problems and "start fixing it" by added text labels. Theadditional information isn't incorporated into the original site's HTML codebut into a metadata file that is loaded each time a visually impaired user subsequentlyvisits the site.
IBM software enhances Web accessibility for the blind
http://www.itworldcanada.com/Pages/Docbase/ViewArticle.aspx?id=idgml-c71b4b16-f815-485f
Martyn Williams ITWorldCanada Friday, July 11, 2008retrieved then too
Chapter 6: Metadata
Introduction
In this chapter, the term metadata is defined. Metadata iscentral to the research and its definition and operation are essential tounderstanding the thesis. There is extensive consideration of emerging mappingtechnologies because the evolving Web is composed of increasingly smaller(atomic) components and discovery and use of these is essential to theAccessForAll metadata approach at the core of the research. There are a numberof ways of buidling a metadata profile of a resource and as the technology inthis process is the very technology to be exploited by the research, some ofthe possibilities are oncluded ion this chapter, such as
Definitions of metadata
| Images | Explanations |
|
| In the home, we put our clothes away and remember which drawer holds what and assume that, if we're not wearing the clothes, they will be in the drawers or in the wash. We know which drawer to go to for our socks. |
|
| In the office, we put documents in files in drawers and number them so we can look up the number, or name, and find the file and thus the document. |
|
| In the digital world, we have invisible digital objects so we write labels for them and look through the labels to find the object we want. |
|
| If we label our digital objects in the same way, even using the same grammar, we can attach a lot of different labels to the same object and still find what we want. |
|
| If we have rules for organising the labels, we can use the labels to sort and organise the objects. |
|
| Then we can connect objects to each other by referring to the labels, even without looking at the objects themselves. |

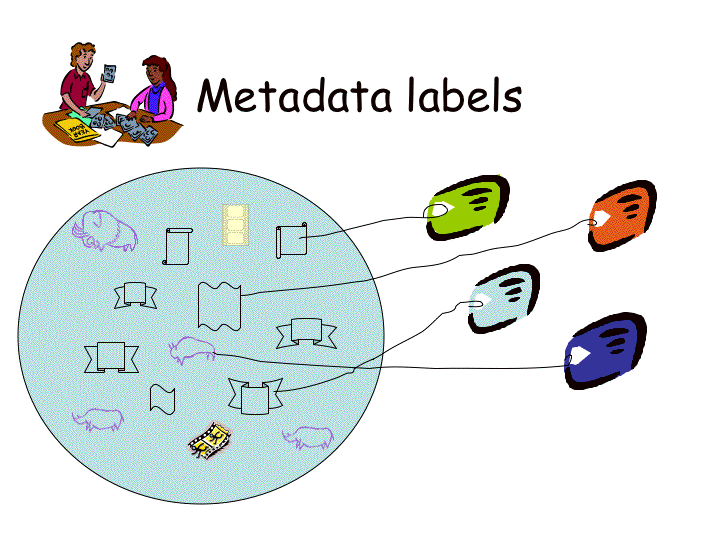
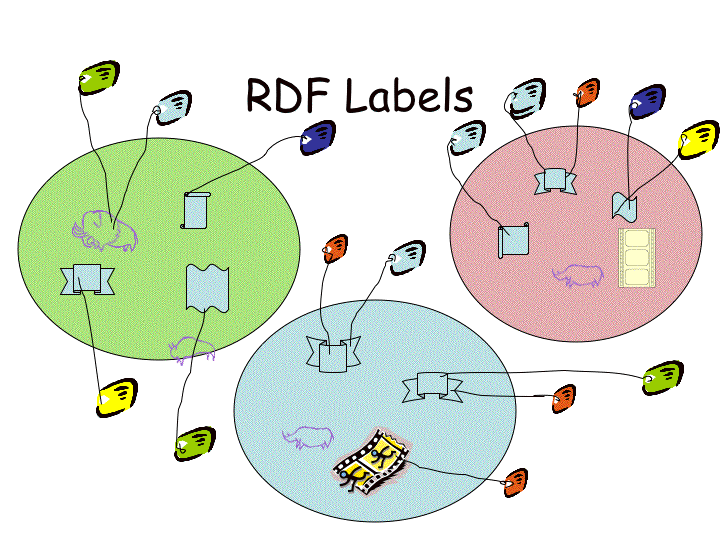


W3C says that, "Metadata is machine understandableinformation for the web" (W3CMetadata Activity).
Before the Dublin Core community started to
| Metadata is machine understandable information about web resources or other things |
The current version of the Berners-Lee documentsays:
(
Berners-Lee
The Dublin Core Met
Metadata hasbeen with us since the first librarian made a list of the items on a shelf ofhandwritten scrolls. The term "meta" comes from a Greek word thatdenotes "alongside, with, after, next." More recent Latin and Englishusage would employ "meta" to denote something transcendental, orbeyond nature. Metadata, then, can be thought of as data about other data. Itis the Internet-age term for information that librarians traditionally have putinto catalogs, and it most commonly refers to descriptive information about Webresources.
A metadatarecord consists of a set of attributes, or elements, necessary to describe theresource in question. For example, a metadata system common in libraries -- thelibrary catalog -- contains a set of metadata records with elements thatdescribe a book or other library item: author, title, date of creation orpublication, subject coverage, and the call number specifying location of theitem on the shelf.
The linkagebetween a metadata record and the resource it describes may take one of twoforms:
1. elements may be contained in a record separate from the item, as in the caseof the library's catalog record; or
2. the metadata may be embedded in the resource itself.
Examples ofembedded metadata that is carried along with the resource itself include theCataloging In Publication (CIP) data printed on the verso of a book's titlepage; or the TEI header in an electronic text. Many metadata standards in usetoday, including the Dublin Core standard, do not prescribe either type oflinkage, leaving the decision to each particular implementation (
The forthcoming guidelines for the use of the forthcomingAGLS Metadata standard for Australia says:
Metadata isa term for something that has been around for as long as humans have beenwriting. It is the Internet-age term for information that librarianstraditionally have put into catalogues and archivists into archival controlsystems. The term ‘meta’ comes from a Greek word that denotes ‘alongside, with,after, next’. Metadata is data about other data. Although there are many varieduses for metadata, the term refers to descriptive information about resources,generally called ‘resource discovery metadata’. 1.3 in "AGLS MetadataStandard Part 2: Usage Guide" draft - not available to public yet..
and, significantly, continues:
Theproperties in the sets of DCMI and AGLS Metadata Terms form the current AGLSMetadata Standard. AGLS can be used for describing both online (ie web pages orother networked resources) and offline resources (eg books, museum objects,paintings, paper files etc). AGLS is intended to describe more than informationresources – it is also designed to describe services and organisations.in 1.4. "AGLS Metadata Standard Part 2: Usage Guide" draft - notavailable to public yet...
In describing the Content Standard for Digital GeospatialMetadata, the Clinton administration's Federal Geographic Data Committee said:
Theobjectives of the standard are to provide a common set of terminology anddefinitions for the documentation of digital geospatial data. The standardestablishes the names of data elements and compound elements (groups of dataelements) to be used for these purposes, the definitions of these compoundelements and data elements, and information about the values that are to beprovided for the data elements (
They go on to add:
The standardwas developed from the perspective of defining the information required by aprospective user to determine the availability of a set of geospatial data, todetermine the fitness [of] the set of geospatial data for an intended use, todetermine the means of accessing the set of geospatial data, and tosuccessfully transfer the set of geospatial data. As such, the standardestablishes the names of data elements and compound elements to be used forthese purposes, the definitions of these data elements and compound elements,and information about the values that are to be provided for the data elements.The standard does not specify the means by which this information is organizedin a computer system or in a data transfer, nor the means by which thisinformation is transmitted, communicated, or presented to the user.
There are many definitions of metadata but generally theyshare two characteristics; they are about "a common set of terminology anddefinitions" and they have a shared structure for that language. Althoughmetadata is analogous to catalogue and other filing descriptions, the nameusually indicates that it is recorded and used electronically.
One difficulty in the use of the term is that it is,correctly, a plural noun but as that is awkward and not usually recognised incommon practice, it will herein be treated as a singular noun, following thepractice described by Murtha Baca, Head, Getty Standards Program, in herintroduction to a book about metadata written by Getty staff and others:
Note: Theauthors of this publication are well aware that the noun "metadata"(like the noun "data") is plural, and should take plural verb forms.We have opted to treat it as a singular noun, as in everyday speech, in orderto avoid awkward locutions (Baca, 1998).
Another difficulty is the frequency with which the word'mapping' is used. The author wishes to write about mapping but is aware of itsuse in the context of 'metadata mapping' where it is usually meant to denotethe relating of one mapping scheme to another. It is also used in theexpression 'metadata application profile' (MAP) where it means a particular setof metadata rules and, more specifically, where it is used by the DCMI for aset of metadata rules where those rules are a combination of rules from othersets.
Yet another difficulty is a quality of good metadata: oneman's metadata can be another's data. The characteristic of metadata beingreferred to here is what is known as its 'first class' nature: any metadata canbe either the data about some other data or itself the subject of othermetadata. This is exemplified by the work of the Open Archives Initiative [
In "Metadata Principles and Practicalities" (
The globalscope of the Web URI name space means that each data element in an element setcan be represented by a globally addressable name (its URI). Invariant globalidentifiers make machine processing of metadata across languages andapplications far easier, but may impose unnatural constraints in a givencontext.
Identifierssuch as URIs are not convenient as labels to be read by people, especially whensuch labels are in a language or character set other than the natural languageof a given application. People prefer to read simple strings that have meaningin their own language. Particular tools and applications can use differentpresentation labels within their systems to make the labels more understandableand useful in a given linguistic, cultural, or domain context (
In fact, although it is often hoped that metadata will behuman-readable, the more it becomes useful to computers, the more that it seemsto become unreadable to humans. In large part, this is due to its being encodedin languages that make it essential for the reader to know what is encoding andwhat is the metadata, but it is also perhaps an artifact of how it ispresented.
Atlases are useful collections of maps, traditionallycollected from a range of cartographers (
In the research, metadata is used to denote structureddescriptions of resources that are organised in a common way and use a commonlanguage.
When collecting descriptive metadata for discovery, oneusually has a database or repository and specifications for the structure ofthe data to be stored in that repository that make it possible to ‘publish' thedata in a consistent way. In order to share metadata for repositories, it isnecessary to have the same structure for all metadata but usually, to makeone's own metadata most useful locally, those who develop such metadata tend towant idiosyncratic structures that suit their local purposes. So localspecificity and global share-ability, inter-operability, are competinginterests. Sharing of the metadata means that more people can use it whereaslocal specificity makes it more valuable in the immediate context, where it isusually engaged with more frequently, and where the cost is often borne.
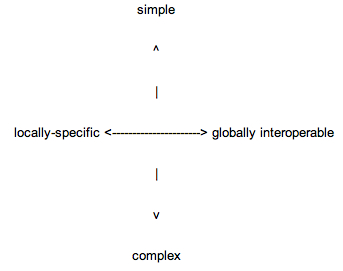
One of the features of good metadata is that it is suitablefor use in a simple way but that it can handle complexity. Another is that itoperates widely on the dimension of locally-specific to globally-interoperable(Fugure ???).
The Dublin Core Metadata Element Set (more recently knownas the DC Terms)provides an excellent example of how this might be achieved. It is a formaldefinition of the way in which descriptive information about a resource can beorganised. It has a core set of elements that have been found to be extremelyuseful in describing almost every type of resource on the Web. Elements can bequalified in various ways for greater precision. In addition, selected elementscan be combined with others in what is called an 'application profile' tocreate a new set for a given purpose. 'Dublin Core' metadata is considered tobe such if it conforms to the formal definition of such metadata although thereis no requirement for the number of elements that must be used beyond thatthere must be a unique identifier for the resource being described. DC metadatacan be expressed in a range of computer languages.
Formal Definition of DC Metadata
Originally, DC metadata was used in HTML tags in simplyencoded resources. The choice of meaning for so-called core elements was, to acertain extent, arbitrary and based on a pragmatic approach to the high-cost ofquality metadata and the experience of cataloguers in the bibliographic world -mostly. Some of the definitions were arrived at as a sort of compromise andthey were fairly loosely defined, even where some experienced cataloguers knewthere were problems being hidden within the definitions.
Over the last decade, the definitions and supportingdocumentation have been slowly improved, always with the need to ensure thatthis will not alienate existing systems.
Currently, the DC terms are defined as follows:
Each term isspecified with the following minimal set of attributes:
A Formal statement of the Grammar of DC Metadata
Despite the aim of having strict adherence to the originaldefinitions of the DC terms, it became difficult to deal with the many moves toexpand, qualify and otherwise change the DC terms. Doggedly sticking to theoriginal documentation without further explanation and improvedinteroperability was proving a threat to the utility of DC metadata as thetechnology developed. In 2000, Thomas Baker described the grammar of the DCMESin an attempt to make it clear how it manages extensibility of elements (Figure???).
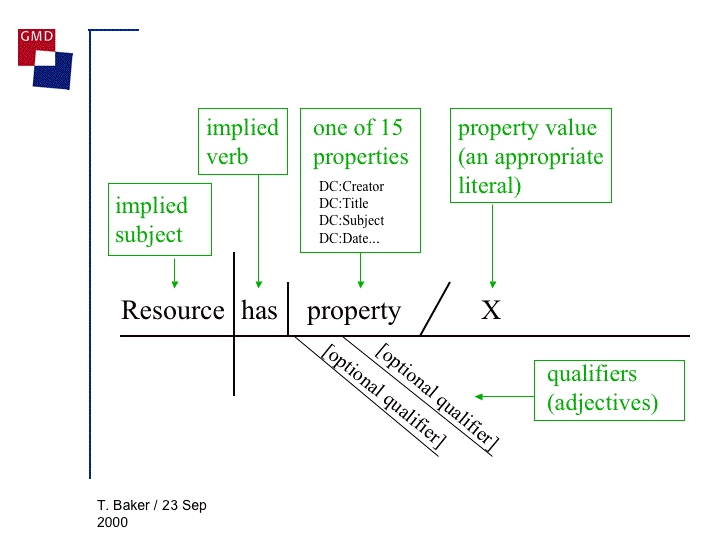
with an example (Figure ???).
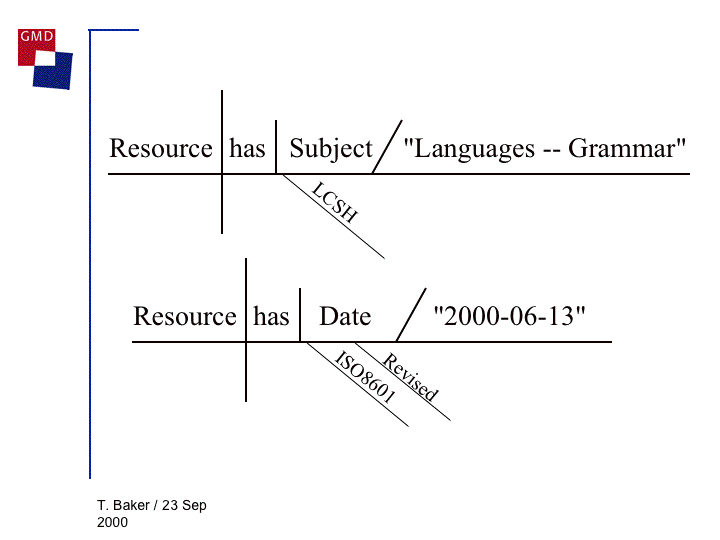
Application Profiles
In 1999, a meeting about how to use DC metadata ineducational portals was convened at Kattamingga in Australia (by the author aspart of the work to develop the metadata for Victoria's new education portal).At this meeting, educationalists discussed the suitability of the DC terms toprovide for descriptions of learning resources. The international group agreedthat there were some extra things they wanted to use and that if there were away of 'regularising' these, interoperability between educational catalogues(repositories) would be improved. The meeting was attended by some of theleading cataloguers of educational Web resources at the time (e.g. StuartSutton and Nancy Morgan from the University of Washington's
Ad hoc rules for extensions and alterations of terms weresuggested on the spot by the Director of the DCMI, Stu Weibel, who said thatall qualifications should:
In addition, there was the idea that certain communitieswould find particular terms useful and the DCMI should provide for theirinclusion, perhaps as a second layer of terms for use. Significantly, this wasthe first formal application profile. An application profile was understood tobe a metadata profile, conformant to DC principles, but suited to the needs ofthe local or domain specific community using it. The development led to theformation of working groups for communities of interest within the DCMIstructure, and the Education Working Group soon was followed by others such asthe Government Working Group.The Government Working Group of the DCMI followedthe lead of the Education Working Group by developing an application profile.Many years later, the term 'audience,'originally suggested at the Kattamingameeting, was added to the core set of DC terms. (For sentimental reasons,perhaps, the core is still usually referred to as having 15 elements despitethe addition of the audience element.)
In 2000, Rachel Heery and others (
The DCMI glossary of 2006 offered the following:
In DCMI usage, an application profile is a declaration of the metadata terms anorganization, information resource, application, or user community uses in itsmetadata. In a broader sense, it includes the set of metadata elements,policies, and guidelines defined for a particular application orimplementation. The elements may be from one or more element sets, thusallowing a given application to meet its functional requirements by usingmetadata elements from several element sets including locally defined sets. Forexample, a given application might choose a specific subset of the Dublin Coreelements that meets its needs, or may include elements from the Dublin Core,another element set, and several locally defined elements, all combined in asingle schema. An application profile is not considered complete withoutdocumentation that defines the policies and best practices appropriate to theapplication. (
Dublin Core Abstract Model
In an attempt to further clarify the Dublin Core approachto metadata, the DCMI Architecture Working Group published two diagrams andsome description of them in March 2005. Version 1.0 of what is known as theAbstract Model [DCMIAM] emerged after six months of interaction and consideration by thatWorking Group in an open forum.
It should be noted that its authors, Powell et al., statedthat: “the UML modeling used here shows the abstract model but is not intendedto form a suitable basis for the development of DCMI software applications”.Elsewhere, software developers were, however, explicitly stated to be one ofthe three target audiences for the DCAM, the other two being developers ofsyntax encoding guidelines and of application profiles.
That Abstract Model was a substantial step towards makingit easier for implementers to model the DC metadata but it still did not solveall the problems. In 2006, a funded effort to provide an abstract model wascommissioned by the DCMI. This produced a more formal graphical representation(Figures ??? - ???).
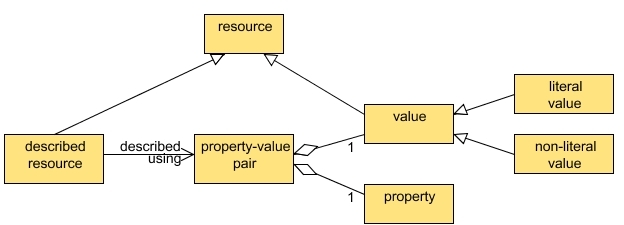
Figure ???: DCMI Resource Model (
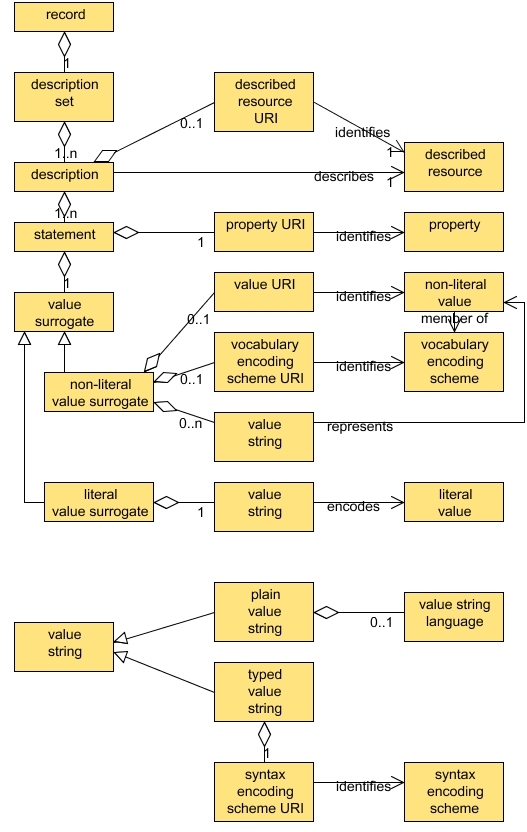
Figure ???: DCMI Description Set Model (
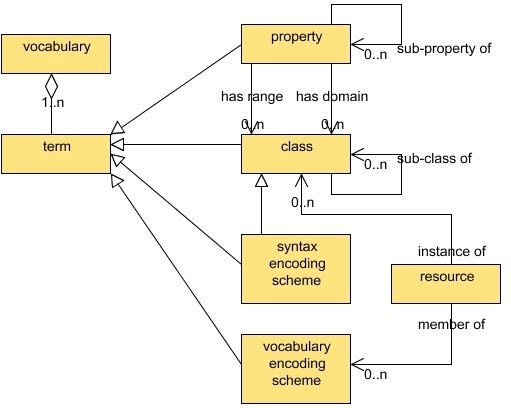
Figure ???: DCMI Vocabulary Model (
That model did not adhere to the strict rules for suchdiagrams set by the Unified Modeling Language (UML)and was not as easy to interpret as had been hoped. Several papers werepresented at the DC 2006 Conference (Palacios et al, 2006; Pulis & Nevile,2006), in which authors argued for a yet better model to be represented instrict UML form, pointing to a number of inconsistencies in the then currentmodel. A new one was commissioned in 2007. At the DC 2007 Conference, MikaelNilsson (
Figure???: The Singapore Framework (
Having more precisely defined models enables profiledevelopers to be more certain about what they need to do. This is important andthe lack of a clear model, to a large extent, explains many of the difficultiesfaced in the accessibility metadata work at that time.
DC as a mapping language for resources
DCMES can thus be seen as providing a three-dimensionalmapping of the characteristics of Web resources:
- 1. element
- 2. qualifiers
- 3. vocabularies
- 1. Steno machine-based systems, commonly called CART (Communication Access Realtime Translation),
- 2. Laptop-based speed typing software systems (C-Print and TypeWell),
- 3. Laptop-based Automatic Speech Recognition software systems (e.g., CaptionMic, iCommunicator).
- 1. Colin is a student at the world university. Colin sometimes studies at home with special Braille equipment but likes to listen to course readings when he is on campus, using a screen reader (profile 1). His sister Mary sometimes likes to work with him, sharing a computer and describing what's happening, as they are studying the same subjects (profile 2). When Mary is studying alone she uses no assistive technology (profile 3). Between them therefore they have three profiles of needs and preferences and may change between them. The profiles impose different requirements on the resources that Colin and Mary can use adequately.
- 2. The university's staff produce teaching materials in alternative versions to suit different user needs as closely as possible. Staff are trained to create labels describing the accessibility features of their materials with AccessForAll Metadata [AFA].
- 3. The university's web site has an application that stores profiles of user needs also expressed in AccessForAll Metadata. The system analyses content labels embedded in course materials and uses rules to discover alternative versions of content suitable for a user's active profile.
- 4. For Mary studying alone (profile 3) a complex diagram may be presented as-is, but if she is studying with Colin they may select profile 2 and the system discovers and delivers to them the same image of the diagram together with a detailed text description. If Colin is alone he cannot see the image and selects profile 1 to read only the text description (Archer, 2007).
- 1. CAL has a list of master files that are electronic verison of print materials for print disabled people (Section V something of a new provision) but this list is only available to people who are registered with CAL - if others want the masters, we need to get CAL to do that but they are protecting the authors...
- 2. Victorian government requires all depts to tag all documents stating where alternatives are available or howho they should contact if they need one. This aims to both help the people with the needs etc but also to bring awareness of the problem to the people working in the various depts.... ref is keynote presentation "Making Government Accessible" by Hilary Fisher, Department of Premier and Cabinet, Victorian Government, at Alternate Format Conference, 22/01/2008 at La Trobe University.
- 3. UTS tags material in special form showing what is useful to which student and they then watch what is used by students and use it as a way of monitoring and helping students more acurately - Madeleine Mann, librarian at UTS presenting at AFC, 22/01/2008
- 4. The Victorian Charter of Human Rights and Responsibilities Act 2006 (Vic) requires laws to comply with charter etc....see http://www.equalopportunitycommission.vic.gov.au/human%20rights/the%20victorian%20charter%20of%20human%20rights%20and%20responsibilities/default.asp based on UK act. This is a preventative charter - raising awareness and preventing the creation of problems. The Charter came into effect in 2007 but is extended to public sector in 2008.
- 5. see email from Julie Rae ??? Vison Australia 10/7/2008 about a world wide effort to make a repository of accessible alternatives....
- 1. Accessify (2003a). Retrieved January 5, 2005, from http://www.accessify.com/articles/DRC-briefing-report.asp
- 2. Accessify (2003b). Retrieved January 5, 2005, from http://www.accessify.com/articles/DRC_FI_intro.ppt
- 3. Alexander, D., and Rippon, S (2007). "Australian university website accessibility revisited" presented at AusWeb 2007. Retrieved July 10, 2008 from http://ausweb.scu.edu.au/aw07/papers/refereed/alexander/paper.html
- 4. American National Academies. Retrieved December 20, 2004, from http://www4.nationalacademies.org/news.nsf/isbn/0309063574?OpenDocument
- 5. American National Science Foundation.Retrieved December 20, 2004, from http://www.nsf.gov/od/lpa/news/press/pr9764.htm
- 6. ARC (2007). National Competitive Grants Program Dataset Retrieved April 4, 2008, from http://www.arc.gov.au/xls/dataset_part2_completed.xls
- 7. Archer, P. (2007). POWDER: Use Cases and Requirements, W3C Working Group Note 31 October 2007 Retrieved November 11, 2007, from http://www.w3.org/TR/2007/NOTE-powder-use-cases-20071031/
- 8. Ashdowne, S., Cartwright, W., & Nevile, L. (2000). "The ancient technique of creating atlases from a collection of maps" in Web Cartography: developments and prospects. ISBN: 0748408681. International Institute for Geo-Information Science and Earth Observation. Retrieved March 15, 2007, from http://www.kartografie.nl/webcartography/webbook/ch03/ch03.htm See also Ashdowne, S., Cartwright, W.E. and Nevile, L., (1995). "Designing a Virtual Atlas on the World Wide Web", WWW proceedings of AusWeb95, Ballina, NSW. Retrieved March 15, 2007, from http://ausweb.scu.edu.au/aw96/educn/ashdowne/index.htm
- 9. Asthana, A. (2006). "Dyslexics excel at Japanese" in Guardian Sunday February 12, 2006. Retrieved March 3, 2006, from http://education.guardian.co.uk/higher/research/story/0,,1708642,00.html
- 10. ATAG, Treviranus, J., McCathieNevile, C., Jacobs, I., & Richards, J. (2000). Authoring Tools Accessibility Guidelines 1.0 Boston, USA: W3C. Retrieved March 8, 2007, from http://www.w3.org/TR/WAI-AUTOOLS/
- 11. Baca, M. (1998). Introduction to Gill, T., Gilliland-Swetland, A., & Baca, M., (Eds.) Introduction to Metadata: Pathways to Digital Information" ISBN 978-0-89236-533-3 Getty Research Institute. Retrieved January 16, 2005, from http://www.getty.edu/research/conducting_research/standards/intrometadata/1_introduction/index.html (no longer available)
- 12. Baker, T. (2000). Retrieved January 13, 2005, from http://dublincore.org/workshops/dc8/pp/dc-8-baker.ppt See also Baker, T., (2000). “A Grammar of Dublin Core,” in D-Lib Magazine, vol. 6, no. 10. Retrieved ??? from http://dlib.anu.edu.au/dlib/october00/baker/10baker.html
- 13. Barstow, C., & Rothberg, M. (2002). IMS Guidelines for Developing Accessible Learning Applications Retrieved January 1, 2006, from http://www.imsglobal.org/accessibility/accessiblevers/index.html
- 14. Berners-Lee, T (1997). “Axioms of Web Architecture: Metadata”. Retrieved July 29, 2008 from http://www.w3.org/DesignIssues/Metadata.html
- 15. Berners-Lee, T. Retrieved March 5, 2008, from http://www.w3.org/WAI/
- 16. Berners-Lee, T. (2004) W3C timeline. Retrieved May 19 2008, from http://www.w3.org/2004/Talks/Styles/w3c10/images/timeline.pdf
- 17. Bigham, J. and Ladner, R (2007). "Accessmonkey: A Collaborative Scripting Framework for Web Users and Developers" in W4A2007 Technical Paper May 07–08, 2007, Banff, Canada. CoLocated with the 16th International World Wide Web Conference. ACM 159593590-8/06/0010. Retrieved July 12, 2008 from http://webinsight.cs.washington.edu/papers/w4a.pdf
- 18. Bingham, H. (1998). Retrieved December 20, 2004, from http://lists.w3.org/Archives/Public/w3c-wai-ig/1998OctDec/0507.html
- 19. Boni, M., Cenni, S., et al. (2006). "Automatically Producing IMS AccessForAll Metadata" W4A at WWW2006, 23rd-26th May 2006, Edinburgh, UK http://www.w4a.info/2006/prog/14-boni.pdf page 97 ACM International Conference Proceeding Series; Vol. 134 Proceedings of the 2006 international cross-disciplinary workshop on Web accessibility (W4A): Building the mobile web: rediscovering accessibility? Edinburgh, U.K. ISBN:1-59593-281-X pps 92-97
- 20. Booth, T., & Ainscow, M., (2000). "Breaking down the barriers: the Index for Inclusion". Retrieved March 4, 2008, from http://inclusion.uwe.ac.uk/csie/index-inclusion-summary.htm
- 21. Borland, J. (2007). A Smarter Web Technical Review. Cambridge, USA: MIT. Retrieved March 19, 2007, from http://www.technologyreview.com/Infotech/18395/page2/
- 22. Bourk, M.J. (1998). Web title is "Universal Service? Telecommunications Policy In Australia and People with Disabilities". Retrieved February 6, 2007, from http://www.tomw.net.au/uso/w3d.html See also Bourk, M., (1998). Universal Service and People with Disabilities: An Analysis of Telecommunications Policy Making from 1975 – 1997. Canberra: University of Canberra.
- 23. Boxall, J. (2004). "Advances and Trends in Geospatial Information Accessibility - Part I " in Journal of Map & Geography Libraries: advances in geospatial information, collections & archives Volume: 1 Issue: 1 ISSN: 1542-0353 Pub Date: 7/9/2004 Retrieved January 8, 2006, from https://www.haworthpress.com/store/ArticleAbstract.asp?ID=44333
- 24. BraMaNet (2008). "BraMaNet : Logiciel de traduction des mathématiques en braille". Retrieved April 16, 2008, from http://handy.univ-lyon1.fr/MH/bramanet/bramanet.php
- 25. Brookes, T. (2004). Retrieved January 11, 2006, from http://lists.alia.org.au/pipermail/aliacatlibs/2004-January/000171.html
- 26. BrowsealoudRetrieved August 2, 2007, from http://www.browsealoud.com/page.asp?pg_id=80107
- 27. Brown, A.L. (1992). "Design Experiments: Theoretical and Methodological Challenges in Creating Complex Interventions in Classroom Settings" in The Journal of the Learning Sciences 2(2): 141-178. Retrieved October 15, 2007, from http://depts.washington.edu/edtech/brown.pdf
- 28. Brown, S., & Gerrard D. (2006). "Squaring the Triangle: The Implications of Broadband for Access, Diversity and Accessibility in Museum Web Design" in J. Trant and D. Bearman (Eds.) Museums and the Web 2006: Proceedings, Toronto: Archives & Museum Informatics. Retrieved March 1, 2006 from http://www.computerworld.com/action/article.do?command=printArticleBasic&articleId=9012345
- 29. Connolly, D. (1994).Retrieved December 20, 2004, from http://cui_www.unige.ch/WWW94/Workshops/workshop.list.html#wwwDev
- 30. Constantine, W. (2006). from: "Museums and the “Digital Curb Cut”: Leveraging Universal Design Principles and Multimedia Technology to Deliver Accessible, Rich-Media Learning Experiences Online", in A Proposal for a Thesis in the Field of Museum Studies For the Degree of Master of Liberal Arts in Extension Studies. Retrieved August 4, 2007, from http://www.museotech.com/wp-content/uploads/2006/11/wconstantine_proposal_final.doc
- 31. Coombs, N. & Treviranus, J. (2000). “Bridging the Digital Divide in Higher Education”, 2000, online at http://www.educause.edu/ir/library/pdf/EDU0028.pdf ??? presented at conf???
- 32. CRKM (2007). Clever Recordkeeping Metadata Projectresearch Method and Findings. Retrieved April 4, 2008, from http://www.infotech.monash.edu.au/research/groups/rcrg/crkm/method.html
- 33. Crow, L., (1995). "Including all of our Lives: Renewing the Social Model of Disability", Chapter 4 in ‘Exploring the Divide’, edited by Colin Barnes and Geof Mercer, Leeds: The Disability Press, 1996, pp. 55 – 72. Retrieved March 3, 2008 from http://www.leeds.ac.uk/disability-studies/archiveuk/Crow/exploring%20the%20divide%20ch4.pdf
- 34. Currie, M., Geileskey, M., Nevile, L., Woodman, R. (2002). ”Visualising Interoperability: ARH, Aggregation, Rationalisation and Harmonisation” in Proc. Int. Conf. on Dublin Core and Metadata for e-Communities 2002: 177-183, Firenze University Press: Florence. Retrieved ??? from http://www.bncf.net/dc2002/program/ft/paper21.pdf
- 35. CWA 15554 (2006). "Specifications for a Web Accessibility Conformity Assessment Scheme and a Web Accessibility Quality Mark". Retrieved ??? from ftp://ftp.cenorm.be/PUBLIC/CWAs/e-Europe/WAC/CWA15554-00-2006-Jun.pdf
- 36. DBRC and D.-B. R. Collective (2003). "Design-based research: An emerging paradigm for educational inquiry" in Educational Researcher 32(1): 5-8.
- 37. DCMI Accessibility Community. Retrieved May 19 2008, from http://dublincore.org/groups/access/
- 38. DC Accessibility Working Group, 2001. Retrieved May 10, 2008, from http://dublincore.org/groups/access/#dc2001
- 39. DC-Accessibility Wiki, (2008). Retrieved April 14. 2008 from http://dublincore.org/accessibilitywiki/ImplementersNews
- 40. DC-ANZ (2003).Retrieved January 6, 2004, from http://www.dc-anz.org/access-roadmap/ (This has since become a formal W3C document (see http://www.w3.org/WAI/PF/roadmap).)
- 41. DC Social Tagging Community Retrieved ??? from http://www.dublincore.org/groups/tagging/
- 42. DCMI (2000). "Dublin Core Qualifiers". Retrieved November 14, 2007, from http://dublincore.org/documents/2000/07/11/dcmes-qualifiers/
- 43. DCMI (2007).Retrieved April 5, 2007, from http://dublincore.org/
- 44. DCMI Glossary-A. Retrieved May 15, 2006, from http://dublincore.org/documents/usageguide/glossary.shtml#A
- 45. DCMI Glossary- M. Retrieved January 16, 2005, from http://dublincore.org/documents/usageguide/glossary.shtml#M. See also Caplan, P. (2003). Metadata Fundamentals for all Librarians. Chicago: American Library Association.
- 46. DCMI Usage Board (2003). retrieved ??? from http://www.dublincore.org/usage/documents/2003/11/18/principles/ See also Powell, A. & Wagner, H, (Eds.) (2001). “Namespace Policy for the Dublin Core Metadata Initiative”. Retrieved ??? from http://dublincore.org/documents/dcmi-namespace/index.shtml.
- 47. DCMI User GuideRetrieved January 16, 2005, from http://dublincore.org/documents/usageguide/#whatismetadata
- 48. Denton, W. (2007). Retrieved July 4, 2008 from http://www.frbr.org/2007/05/04/rda-dc-frbr-frad-rdf
- 49. Derndorfer, C. (2008). "The power of Sugar" retrieved July 8, 2008 from http://www.olpcnews.com/software/operating_system/
- 50. Di Iorio, A., Feliziani, A.A., Mirri, S., Salomoni, P., & Vitali, F. (2006). "Automatically Producing Accessible Learning Objects" in Educational Technology & Society, 9 (4), 3-16. Retrieved ??? from http://www.ifets.info/journals/9_4/2.pdf
- 51. DRC (2003).Retrieved January 5, 2005, from http://www.drc-gb.org/newsroom/newsdetails.asp?id=393§ion=1
- 52. DRC (2004). The Web Access and Inclusion for Disabled People A formal investigation conducted by the Disability Rights Commission. London: TSO ISBN 0 11 703287 5. Retrieved January 5, 2005, from http://www.drc.gov.uk/publicationsandreports/2.pdf
- 53. DRC (2004a). Retrieved April 5, 2007, from http://www.drc.gov.uk/library/website_accessibility_guidance/formal_investigation_report_w.aspx
- 54. DRC (2004b). Retrieved ??? from http://www.drc.gov.uk/PDF/2.pdf
- 55. e-Government Unit, UK Cabinet Office (2005). eAccessibility of public sector services in the European Union. Retrieved March 30, 2007, from http://www.cabinetoffice.gov.uk/e-government/resources/eaccessibility/content.asp
- 56. Engage (2007).Retrieved April 5, 2007, from http://engage.wisc.edu/accomplishments/IMS/index.html
- 57. EuroAccessibility (2004).Retrieved January 7, 2005, from http://www.euroaccessibility.org/tf3_doc/EACTF3TestableStatements.html
- 58. EuroAccessibility (2003).Retrieved January 6, 2005, from http://www.euroaccessibility.org/press.php
- 59. European Commission. European Commission Report Number DG INFSO/B2 COCOMO4 – p. 14
- 60. Evans, J., & Rouche, N. (2006). "Utilizing Systems Development Methods in Archival Systems Research: Building a Metadata Schema Registry" in Journal Archival Science. Publisher Springer Netherlands, ISSN 1389-0166 (Print) 1573-7519 (Online), Issue Volume 4, Numbers 3-4 / September, 2004, DOI 10.1007/s10502-005-2598-4, Pages 315-334. Retrieved April 4, 2008, from http://www.springerlink.com/content/0475856474rm8567/fulltext.pdf
- 61. FGDC (1998). Content Standard for Digital Geospatial Metadata, FGDC-STD-001-1998. Retrieved January 16, 2005, from http://www.fgdc.gov/metadata/contstan.html Also retrieved March 30, 2007, from http://www.fgdc.gov/standards/projects/FGDC-standards-projects/metadata/base-metadata/
- 62. Flowers, C.P., Bray, M., Algozzine, R.F., (1999). "Accessibility of Special Education Program Home Pages" in Journal of Special Education Technology 1999;14(2):21-26.
- 63. FLUID, (2007). Retrieved March 2, 2008 from from http://fluidproject.org/
- 64. Ford, M., & Nevile L. (2005). “Issues enabling support for Multi-locational Accessibility“ presented at IDABC: Cross-border E-Government Services for Administrations, Businesses and Citizens Conference', Brussels, February 2005. Retrieved ??? from http://europa.eu.int/idabc/servlets/Doc?id=19406
- 65. Forrester, Inc. (2004). Retrieved ??? from http://www.microsoft.com/enable/research/.
- 66. FRBR (1998). Functional Requirements for Bibliographic Records Final Report. Retrieved ??? from http://www.ifla.org/VII/s13/frbr/frbr.pdf
- 67. Friesen, N. (2005). Retrieved ??? from http://www.cancore.ca/access.html
- 68. Friesen, N. (2006). "CanCore Guidelines for the "Access for All" Digital Resource Description Metadata Elements." Retrieved ??? from http://www.cancore.ca/guidelines/drd
- 69. Garshol, L.M. (2002). "Topic Maps ... : What are Topic Maps?" Retrieved October 20, 2007, from http://www.xml.com/pub/a/2002/09/11/topicmaps.html
- 70. Garshol, L.M. (2004). "Metadata? Thesauri? Taxonomies? Topic Maps! Making sense of it all." Retrieved January 14, 2005, from http://www.ontopia.net/topicmaps/materials/tm-vs-thesauri.html
- 71. Gibson, W. (1984). Quoted from Neuromancer, New York: Ace Books. Retrieved March 28, 2006, from http://en.wikiquote.org/wiki/William_Gibson
- 72. Glinert - Ephraim, P. (1998). " Retrieved December 20, 2004, from http://lists.w3.org/Archives/Public/w3c-wai-ig/1998OctDec/0507.html (quoted in an email Mon, 7 Dec 1998 from Harvey Bingham who noted that Gregg et Larry Goldman???
- 73. Gillard, J., (2007). "A Social Inclusion Agenda" presented at Speech ACOSS National Annual Conference, November 2007. Retrieved March 12, 2008, from http://www.alp.org.au/media/1107/spesi220.php
- 74. Green, S., Pearson, E., Gkatzidoy, S., & Jones, R. (date???). "Accessibility, usability and adaptability: responding to Dublin Core Profiles of Needs and Preferences." Retrieved August 4, 2007, from http://learning.north.londonmet.ac.uk/im214/Adapatability.pdf
- 75. Halm, M. J. (2003). "Beyond the LOM: A New Generation of Specifications" in Learning Objects Research Collection, Ohio State University Knowledge Bank. Retrieved ??? from http://hdl.handle.net/1811/20
- 76. Hammond, T and Van De Sompel, H (2003). "Bootstrapping the Web" Retrieved July 12, 2008 from http://info-uri.info/registry/docs/misc/Bootstrapping%20the%20Web.htm
- 77. Harbo, K., Engelen, J., Evenepoel, F., & Bauwens, B. (1994). "Document processing based on architectural forms with ICADD as an example." Retrieved December 20, 2004, from http://xml.coverpages.org/harbo.html
- 78. Heath, A. (2004). BSI IST/43 Information Technology for Learning, Education and Training A British Standard for the Accessibility of e-Learning Systems and Content. A Proposal for New Work. Retrieved May 24, 2004, from http://www.schmoller.net/documents/IST_43.0110_04.pdf
- 79. Heery, R., & Patel, M. (2000). "Application profiles: mixing and matching metadata schemas" in Ariadne Issue 25. Retrieved March 15, 2007, from http://www.ariadne.ac.uk/issue25/app-profiles/intro.html
- 80. HFI (2005). Human Factors International. Retrieved January 15, 2005, from http://www.humanfactors.com/downloads/chocolateaudio.asp
- 81. HREOC (1995). Geoffrey Scott v Telstra Corporation Limited, Disabled People's International (Australia) Limited v Telstra Corporation Limited, Human Rights and Equal Opportunity Commission, Sir Ronald Wilson (Inquiry Commissioner). Retrieved ??? from http://www.hreoc.gov.au/disability_rights/decisions/comdec/1995/DD000060.htm
- 82. HREOC (1999) Bruce Lindsay Maguire v Sydney Organising Committee for the Olympic Games, The Hon William Carter QC (Inquiry Commissioner). Retrieved July 12, 2008 from http://www.hreoc.gov.au/disability_rights/decisions/comdec/1999/DD000150.htm
- 83. HREOC (2002). World Wide Web Access: Disability Discrimination Act Advisory Notes, Version 3.2, August 2002.Retrieved February 12, 2007, from http://www.humanrights.gov.au/disability_rights/standards/www_3/www_3.html
- 84. HTML Writers Guild. "Accessibility Standards". Retrieved March 10, 2005, from http://www.hwq.org/opcenter/policy/access.htm
- 85. HFI-chocolate (Human Factors International). Retrieved January 15, 2005, from http://www.humanfactors.com/downloads/chocolateaudio.asp
- 86. HFI- testing (Human Factors International). Retrieved January 15, 2005, from http://www.humanfactors.com/downloads/accessibletesting.asp
- 87. Howell, J.(2008). "Opinion - Web Accessibility. Life in the Post-Guideline Age", report of keynote address at E-Access '08 Conference. Retrieved June 25, 2008 from http://www.headstar.com/eablive/?p=195
- 88. Hudson, R., & Weakley, R (2007). "Web 2.0 and the concept of Universal Design" Presentation at OZeWAI 2007 conference, La Trobe University.
- 89. IBM (2005). "IBM Informix Database Design and Implementation Guide" Retrieved July 12, 2008 from http://publib.boulder.ibm.com/infocenter/ids9help/topic/com.ibm.ddi.doc/ddi53.htm
- 90. IEEE LOM (2002). IEEE 1484.12.1 - 2002 Learning Object Metadata (LOM). Retrieved May 10, 2008, from see ch .. - http://ltsc.ieee.org/wg12/20020612-Final-LOM-Draft.html
- 91. IMS Global Learning Consortium (2003). "Learning Design specifications." Retrieved May 11, 2008, from http://www.imsglobal.org/learningdesign/
- 92. IMS Global Learning Consortium (2001). "Learning Resource Meta-Data Information Model Version 1.2.1 Final Specification." Retrieved May 10, 2008 from http://www.imsglobal.org/metadata/imsmdv1p2p1/imsmd_infov1p2p1.html
- 93. IMS (2007) Retrieved April 5, 2007, from http://www.imsglobal.org/index.html
- 94. INCITS V2 community (http://v2.incits.org/) as they developed the Universal Console specifications http://www.itl.nist.gov/iad/vvrg/newweb/incits.html now becoming an ISO standard - http://www.open-std.org/JTC1/sc35/wg8/)
- 95. INCITS V2, Universal Console specifications (http://www.itl.nist.gov/iad/vvrg/newweb/incits.html) add a date...
- 96. INCITS/V2. Technical Committee on Information Technology Access for the InterNational Committee for Information Technology Standards http://www.incits.org/tc_home/v2.htm
- 97. Interactive Bureau, (2002). A Report in to Key Government Websites. Retrieved November 29, 2007, from http://www.iablondon.com/news.cfm
- 98. ISO in Brief (2006). Retrieved ??? from http://www.iso.org/iso/en/prods-services/otherpubs/pdf/isoinbrief_2006-en.pdf
- 99. ISO/IEC JTCI SC 36 (2008). Culture, Language, and Human Functioning Activities. Retrieved July 12,2008 from http://www.jtc1sc36.org/Workgroups/Work%20Group%20Seven
- 100. IT021-08 (Standards Australia) (2007). "IT-021-08 AGLS subcommittee Minutes of Meeting – 16 October 2007" Retrieved July 11, 2008 from http://www.naa.gov.au/Images/AGLS%20Working%20Group%20%20%20Standards%20Australia%20Committee%20IT21-08%20Meeting%20Minutes%20for%20~%20Final%20Version_tcm2-10050.pdf
- 101. Jackl, A., (Ed.) (2003). "IMS Learner Information Package Accessibility for LIP - Version 1 Final Specification." Retrieved January 11, 2006, from http://www.imsglobal.org/specificationdownload.cfm
- 102. Jackl, A, 2004 (Ed.). “IMS AccessForAll Metadata Overview”. Retrieved ??? from http://www.imsglobal.org/accessibility/accmdv1p0/imsaccmd_oviewv1p0.html
- 103. Jackson, B. (2004). for the Web Standard Group, of Fairfax DigitalRetrieved December 14, 2004, from http://webstandardsgroup.org/resources/documents/doc_317_brettjacksontransitiontoxhtmlcss.doc
- 104. Jankowski, P., & Nyerges, T. (2001). Geographic Information Systems for Group Decision Making: Towards a Participatory, Geographic Information Science. New York: Taylor & Francis.
- 105. Jeon, J., et al (2005), “Finding Semantically Similar Questions Based on Their Answers” in Proceedings of the 28th International ACM SIGIR Conference, pp. 617-618, 2005. Retrieved ??? from http://ciir.cs.umass.edu/~jeon/papers/p061-jeon.pdf.
- 106. Johnston, P (2006). "dctagging" Retrieved July 10, 2008 from http://efoundations.typepad.com/efoundations/2006/10/dctagged.html
- 107. Johnston, P., Powell, A, et al (2007). "Update on work of the Joint DCMI/IEEE LTSC Task Force". Retrieved July 11, 2008 from http://www.slideshare.net/eduservfoundation/report-on-work-of-joint-dcmiieee-ltsc-task-force/
- 108. Johnston, P. (2008). "A "layered" model for interoperability using Dublin Core metadata" Retrieved July 10, 2008 from http://efoundations.typepad.com/efoundations/2008/05/a-layered-model.html
- 109. JTC1 (2007). ??? Retrieved April 5, 2007, from http://www.iso.org/iso/en/stdsdevelopment/tc/tclist/TechnicalCommitteeDetailPage.TechnicalCommitteeDetail?COMMID=1
- 110. Kateli, B. (2007). Annosource: A prototype application based on an annotation server to customise content to match individual user's needs, preferences and interests. Unpublished masters thesis.
- 111. Keenoy, K. (2003). SeLeNe - Preliminary Report: Learning Objects, Meta-Data and Standards for the SeLeNe : Self e-Learning Networks Project. Retrieved July 10, 2008 from http://www.dcs.bbk.ac.uk/selene/reports/KK_Preliminary_report.pdf
- 112. Kelly, B., (2002). "Web Watch: An Accessibility Analysis of UK UNiversity Entry Points" in Ariadne Issue 33. Retrieved November 29, 2007, from http://www.ariadne.ac.uk/issue33/web-watch/
- 113.
- 114. Kelly, B., Phipps, L., & Swift, E. (2004). "Developing a Holistic Approach for E-Learning Accessibility" in Canadian Journal of Learning and Technology. Volume 30(3) Fall / automne 2004. Retrieved February 6, 2007, from http://www.cjlt.ca/content/vol30.3/kelly.html
- 115. Kelly, B., Sloan, D., Phipps, L., Petrie, H., & Hamilton, F. (2005). City University, London, UK "Forcing standardization or accommodating diversity?: a framework for applying the WCAG in the real world" in Vol. 88 Proceedings of the 2005 International Cross-Disciplinary Workshop on Web Accessibility (W4A) Chiba, Japan, Pages: 46 - 54 ISBN:1-59593-219-4 ACM International Conference Proceeding Series; Publisher ACM Press New York. Retrieved ??? from http://portal.acm.org/ft_gateway.cfm?id=1061820&type=pdf&coll=GUIDE&dl=GUIDE&CFID=10797224&CFTOKEN=47740524
- 116. Kelly, B. (2006). PowerPoint presentation for "Forcing standardization or accommodating diversity?: a framework for applying the WCAG in the real world" presented at 2005 International Cross-Disciplinary Workshop on Web Accessibility (W4A) Chiba, Japan. Retrieved April 8, 2007, from http://www.ukoln.ac.uk/web-focus/events/conferences/w4a-2006/w4a-2006-contextual-accessibility.ppt
- 117. Kelly, B., Sloan, D., Heath, A., Petrie, H., Hamilton, F., & Phipps, L. (2006). "Contextual Web Accessibility - Maximizing the Benefit of Accessibility Guidelines" for "Building the Mobile Web: Rediscovering Accessibility?" workshop W4A at the Fifteenth International World Wide Web Conference, in Edinburgh, Scotland, UK. Retrieved February 7, 2007, from http://www.w4a.info/2006/presentations/18-David-Sloan-et-al.pdf
- 118. Kelly, B., & Brown, S. (2007). "Accessibility 2.0: A Holistic And User-Centred Approach To Web Accessibility" in Trant, J., & Bearman, D. (Eds) (2007). Museums and the Web 2007: Proceedings. Toronto: Archives & Museum Informatics. Retrieved ??? from http://www.archimuse.com/mw2007/papers/kelly-brown/kelly-brown.html
- 119. Kelly, B. (2008). Government Web Sites MUST Be WCAG AA Compliant! Retrieved June 27, 2008, from http://ukwebfocus.wordpress.com/2008/06/25/government-web-sites-must-be-wcag-aa-compliant/
- 120. Kelly, B., Nevile, L., Draffan, E., and Fanou, S. (2008). One world, one web .. but great diversity. In Proceedings of the 2008 international Cross-Disciplinary Conference on Web Accessibility (W4a) (Beijing, China, April 21 - 22, 2008). W4A '08, vol. 317. ACM, New York, NY, 141-147. DOI= http://doi.acm.org/10.1145/1368044.1368078
- 121. Krempl, S (2008). "New doubts about ISO's fast-track standardisation of Microsoft OOXM" Retrieved July 12, 2008, from http://www.heise.de/english/newsticker/news/110736
- 122. Laviolette, A. (2007). "Understanding User-Centred Design." Retrieved April 30, 2007, from http://www.geoconnections.org/UCD.ppt
- 123. Lawrence, S., & Giles, C.L. (1999). "Accessibility of Information on the web." Retrieved ??? from http://www.nature.com/cgi-taf/DynaPage.taf?file=/nature/journal/v400/n6740/full/400107a0_fs.html
- 124. Levien, R. (1999). Retrieved December 22, 2004, from http://www.levien.com/svg/tiger.svg
- 125. Library of Congress (2006). ”Metadata Object Description Schema (MODS).” Retrieved ??? from http://www.loc.gov/standards/mods/
- 126. Library Thing. Retrieved May 15, 2006, from http://www.librarything.com/authorcloud.php
- 127. Lloyd, J.W. (2007). "Dyslexic entrepreneurs". Retrieved April 14, 2008, from http://ldblog.com/2007/12/06/dyslexic-entrepreneurs/
- 128. Lombardi, V. (2003). "Metadata Glossary." Retrieved January 14, 2005, from http://www.noisebetweenstations.com/personal/essays/metadata_glossary/metadata_glossary.html
- 129. MacEachren, A.M., & Kraak, M.-J. (2001). “Research Challenges in Geovisualization.” Cartography and Geographic Information Science, 28(1):3-12.all quoted in lit review ch in an article about geospatial stuff.
- 130. Maguire v Sydney Organising Committee for the Olympic Games Retrieved March 14, 2008 from http://www.egov.vic.gov.au/index.php?env=-innews/detail:m2750-1-1-8-s-0:n-1344-1-0--
- 131. Mark, D.M., Freksa, C., Hirtle, S.C., Lloyd, R., & Tversky, B. (1999). “Cognitive Models of Geographical Space” in International Journal of Geographical Information Science, 13(8):747-774 all quoted in lit review ch in an article about geospatial stuff.
- 132. McDougall, P (2008). "Norway Official Protests Country's OOXML Vote" in Information Week April 1, 2008. retrieved July, 8 2008 from http://www.informationweek.com/news/management/showArticle.jhtml?articleID=207001016
- 133. Microsoft (2003a). Retrieved January 14, 2007 from http://www.microsoft.com/enable/research/whobenefits.aspx
- 134. Microsoft (2003b). Retrieved January 14, 2007 from http://www.microsoft.com/enable/research/workingage.aspx
- 135. Microsoft (2003c). Retrieved January 14, 2007 from http://www.microsoft.com/enable/research/agingpop.aspx
- 136. Microsoft (2003d). Retrieved January 14, 2007 from http://www.microsoft.com/enable/research/summary.aspx
- 137. Microsoft (2008). Retrieved June 27, 2008 from http://www.microsoft.com/enable/research/
- 138. Microformats. Retrieved May 15, 2006, from http://microformats.org/wiki/microformats
- 139. Microformats-2. "Tags are Visible Metadata."Retrieved May 15, 2006, from http://microformats.org/wiki/rel-tag#Tags_Are_Visible_Metadata
- 140. Moock, C. (2005). Flash codeRetrieved January 15, 2005, from http://www.moock.org/webdesign/flash/detection/moockfpi/
- 141. MOPIX (2006). Retrieved January 6, 2006, from http://ncam.wgbh.org/mopix/mopixmovies.html#lf
- 142. Morgan, E., (2000). "Wordswork" in The Dyslexia Online Journal. Retrieved April 14, 2008, from http://www.dyslexia-adults.com/wordswork.html
- 143. Morozumi, A., Nagamori, M., Nevile, L., & Sugimoto, S. (2006). "Using FRBR for the Selection and Adaptation of Accessible Resources" presented at Dublin Core 2006. Proceedings of the International Conference on Dublin Core and Metadata Application, pps. 183-194. ISBN: 970-692-268-7. DCMI: Manzanillo (Méjico).
- 144. Morozumi, A., Nevile, L., & Sugimoto, S. (2007). "Enabling Resource Selection based on Written English and Intellectual Competencies" for ICADL, Vietnam, Dec 2007 (forthcoming).
- 145. Moss, T (2006). "WCAG 2.0: The new W3C accessibility guidelines evaluated" Retrieved January 6, 2006 from http://www.webcredible.co.uk/user-friendly-resources/web-accessibility/wcag-guidelines-20.shtml
- 146. MRC UNC (2008). Project Information, Knowledge Exploration Environment for Motion Pictures. Retrieved April 4, 2008, from http://ils.unc.edu/mrc/kee-mp
- 147. Munro, J. (2007). Using a Prototyping Approach to Build a Transformation System for Converting Literary and Technical Documents (XHTML and MathML) into Braille. Unpublished thesis. La Trobe University, 2007.
- 148. National Academies (1997). Retrieved December 20, 2004, from http://www4.nationalacademies.org/news.nsf/isbn/0309063574?OpenDocument
- 149. NBII. National Biological Information Infrastructure. Retrieved January 8, 2006, from http://www.nbii.gov/about/accessibility.html
- 150. NCD (2006). National Council on Disability. "Over the Horizon: Potential Impact of Emerging Trends in Information and Communication Technology on Disability Policy and Practice." Retrieved ??? from http://www.ncd.gov/newsroom/publications/2006/emerging_trends.htm
- 151. Negroponte, N. (1995). ????
- 152. Nevile??ref - not yet but soon! sent to Jon Mason )- being published??? what is it?
- 153. Nevile1, Nevile, L., http://webcontentaccessibility.org/AccessibleContentDevelopment - now in Appendix 8
- 154. Nevile, L. (2001). Retrieved January 6, 2005, from http://dublincore.org/groups/access/access-2002.shtml#dc2001
- 155. Nevile, L. (2002). DCMI Accessibility Working Group Charter. Retrieved January 6, 2004, from http://dublincore.org/groups/access/access-2002.shtml
- 156. Nevile, L. (2003a). Retrieved January 6, 2004, from http://www.dc-anz.org/access-roadmap/ (This resource is no longer available.)
- 157. Nevile, L. (2003b). - notes about proposed workshop at dc conf - for agls??
- 158. Nevile, L. (2003c). "Making a Mathematical Textbook Accessible in Braille." Paper presented at OZeWAI 2003. Retrieved July 10, 2008 from http://www.ozewai.org/2003/LNevile/maths-braille.html see also Liddy Nevile in Appendix 8
- 159. Nevile, L. (2004). "Metadata Generation and Accessibility Auditing." Paper presented at DC 2004. Retrieved July 10, 2008 from http://journals.sfu.ca/dcpapers/2004/Paper_03.pdf
- 160. Nevile, L., & Ford, M. (2004a). CEN Workshop Report 2004 CEN/ISSS MMI-DC (WI5), ISSS/WS-MMI-DC/121 "“A report identifying metadata issues enabling support for accessibility and multi-linguality.” Retrieved April 28, 2007, from http://www.cen.eu/cenorm/businessdomains/businessdomains/isss/activity/mmidcw15finalreportdoc.doc
- 161. Nevile, L., & Ford, M. (2004b). “User-centred Accessibility as Re-configurability for Location-based Information Systems." Retrieved July 10, 2008 from http://www.research.att.com/~rjana/WF12_Paper5.pdf
- 162. Nevile, L., and Lissonnet, S. (2004). The Case for a Person/Agent Dublin Core Metadata Element Set. In Volume 1, Number 3/2006 of International Journal of Metadata, Semantics and Ontologies, InderScience. Retrieved July 10, 2008 from http://inderscience.metapress.com/openurl.asp?genre=article&issn=1744-2621&volume=1&issue=3&spage=198
- 163. Nevile, L. (2005a). “Adaptability And Accessibility: A New Framework“ in Proceedings of OZCHI 2005, Canberra, Australia. November 23 - 25, 2005. ACM (the Association for Computing Machinery) Digital Library. Retrieved March 15, 2008 from http://portal.acm.org/dl.cfm
- 164. Nevile, L. (2005b). “Anonymous Dublin Core Profiles for Accessible User Relationships with Resources and Services“, presented at DC 2005 Conference. Retrieved March 15, 2008 from http://purl.oclc.org/dcpapers/2005/paper09. Later, republished as 2006 "Anonymous Dublin Core Profiles for Accessible User Relationships with Resources and Services" in New Technology of Library and Information Service, vol. 1/2006 Serial No.132, pp. 17-24.
- 165. Nevile L, Cooper M, Heath A, Rothberg M, Treviranus J (2005). "Learner-centred accessibility for interoperable web-based educational systems" in Proceedings 14th International World Wide Web Conference (WWW2005), Chiba, Japan, May 10–14, 2005.
- 166. Nevile, L. (2005c). “User-Centred Accessibility Supported by Distributed, Cumulative Authoring.” Retrieved ??? from http://ausweb.scu.edu.au/aw05/papers/refereed/nevile/
- 167. Nevile, L. (2006). “Research convergence to enable accessibility to be customised for individual users” presented at ASK-IT International Conference, Nice, France, October 2006. (Should be available from http://www.ask-it.org/conference_files/D%20Concertation%20of%20research%20initiatives/D1.%20Nevile.doc but isn't???)
- 168. Nevile, L. Retrieved ??? from http://webcontentaccessibility/AccessibleContentDevelopment/hyperlecture/INDEX.HTM See also ausweb paper... This is in Appendix 8 now.....
- 169.
- 170. Nevile -something personal communication between W3C and the PM's office via the author8/11/2007
- 171. Nevile, L., & Ford, M. (2005). “Issues Enabling Multi-locational Accessibility.” Retrieved ??? from http://europa.eu.int/idabc/servlets/Doc?id=19406
- 172. Nevile, L. (2005). “Anonymous Dublin Core Profiles for Accessible User Relationships with Resources and Services“ DC 2005, Madrid, Spain. Retrieved ??? from http://purl.oclc.org/dcpapers/2005/paper09
- 173. Nevile, L., & Ford, M. (2006). “Location and Access: Issues Enabling Accessibility of Information” in Cartwright, W., Peterson, M., & Gartner, G. (Eds.) (2007). Multimedia Cartography (2nd Edition) ISBN 3-540-36650-4 Springer-Verlag - Heidelberg.
- 174. Nevile, L., & Lissonnet, S. (2003). PowerPoint slides for presentation of "Dublin Core: the base for an Indigenous culture environment?" at MW2003. Retrieved ??? from http://www.archimuse.com/mw2003/papers/nevile/nevile.html
- 175. Nevile, L., & Mason, J. (2005). “Open Courseware: realising the potential of standards as enablers of valuable global participation” for Initiatives Colloquium held at WSIS 2005, Tunisia. See program, retrieved ??? from http://openforum.refer.org/IMG/pdf/Programme_avec_communications_v5-1.pdf
- 176. Nevile, L., & Treviranus, J., (2006). “Interoperability for Individual Learner Centred Accessibility for Web-based Educational Systems” in IEEE TCLT's Journal of Educational Technology & Society, Volume 9, Issue 4, 2006, pps 215-227. Retrieved June 5, 2007 from http://www.ifets.info/issues.php?id=33
- 177. New York Times Online, (2005). Retrieved January 1, 2005 from http://nytimes.com/pages/world/index.html
- 178. Nilsson, M. (2007). "Description Set Profiles." Retrieved October 11, 2007 from http://dublincore.org/architecturewiki/SingaporeFramework?action=AttachFile&do=get&target=DSP.pdf
- 179. Nilsson, M., Baker, T., and Johnston, P (2008). "Interoperability levels for Dublin Core metadata" Retrieved July 10, 2008 from http://dublincore.org/architecturewiki/InteroperabilityLevels
- 180. NJED. Retrieved December 20, 2004, from http://www.njedge.net/activities/assistive-04232002_Biographies.html
- 181. NLS (2002). Retrieved January 6, 2006, from http://www.loc.gov/nls/newsreleases/20020315.html
- 182. NLS (2006). Retrieved January 6, 2006, from http://www.loc.gov/cgi-bin/zgate.nls?ACTION=INIT&FORM_HOST_PORT=/prod/www/data/nls/catalog/index.html,z3950.loc.gov,7490&CI=194237
- 183. NLS About (2006). Retrieved January 6, 2006, from http://www.loc.gov/nls/reference/circulars/magazines.html#aboutformats
- 184. NLS Facts (2006). Retrieved January 6, 2006, from http://www.loc.gov/nls/reference/factsheets/network.html
- 185. Nomensa (2006). United Nations,Global Audit of Web Accessibility, Retrieved March 3, 2008, from http://www.nomensa.com/news/at-nomensa/2006/12/nomensa-publishes-global-audit-with-united-nations.html
- 186. Norton, M. (2004). "IMS AccessForAll Meta-data Specification - Version 1 Final Specification." Retrieved January 12, 2006, from http://www.imsglobal.org/accessibility/
- 187. NSF (2007).Retrieved December 20, 2004, from http://www.nsf.gov/od/lpa/news/press/pr9764.htm
- 188. Nunamaker, J.F., Chen, M. J.R. & Purdin, T.D.M (1990-91). ‘‘Systems Development in Information Systems Research’’, Journal of Management Information Systems, vol. 7, no. 3, (Winter 1990–1991), pp. 89–106.
- 189. NZ Land Information (2004). Geospatial Information the Future Role of Government: Discussion Document (November 2004) Retrieved January 8, 2006, from http://www.linz.govt.nz/geospatial/
- 190. OAI (2002). "The Open Archives Initiative Protocol for Metadata Harvesting". Retrieved January 16, 2005, from http://www.openarchives.org/OAI/openarchivesprotocol.html
- 191. OACSIM. US Office of the Assistant Chief of Staff for Installation Management. Retrieved January 8, 2006, from http://gisr.belvoir.army.mil/accessibility.html
- 192. Oliver, M., (1990a). The politics of disablement. Critical texts in social work and the welfare state. London: Macmillan Education.
- 193. Oliver, M., (1990b). "The individual and Social Models of Disability". Paper presented at Joint Workshop of the Living Options Group and the Research Unit of the Royal College of Physicians on People with Established Locomotor Disabilities in Hospitals. Retrieved March 3, 2008 from http://www.leeds.ac.uk/disability-studies/archiveuk/Oliver/in%20soc%20dis.pdf
- 194. Otkidach, D.S., et al (2004). Retrieved ??? from http://mail.python.org/pipermail/python-list/2004-November/251224.html
- 195. O'Reilly, T. (2005). Retrieved March 28, 2006, from http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html
- 196. O'Reilly T. (2004). Retrieved March 28, 2006, from http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html
- 197. OUT-Law (2004). OUT-LAW.COM is part of international law firm Masons. Retrieved January 5, 2005, from http://www.theregister.co.uk/2004/04/15/drc_names_notshames/
- 198. Paciello, M. (1995). Presentation for workshop called "Web Accessibility for the Disabled". Program archive retrieved December 20, 2004, from http://www.w3.org/Conferences/WWW4/Workshop.html
- 199. Paciello, M. Retrieved December 20, 2004, from http://www.gcritchley.freeserve.co.uk/accessible.htm#history
- 200. Paciello, M. (1995). "Web Accessibility for the Disabled "Retrieved December 20, 2004, from http://www.w3.org/Conferences/WWW4/Workshop.html
- 201. Palacios, V., Morato, J., Llorens, J., & Moreiro, J.A. (2006). "DCMI abstract model analysis. Resource Model" presented at Dublin Core 2006. International Conference on Dublin Core and Metadata Applications. Manzanillo (Méjico). 3 - 6 October 2006.
- 202. Palo Alto Research Center, Inc., (2008). Retrieved February 18, 2008, from http://www.parc.com/
- 203. Pandora (2007). Retrieved December 10, 2007, from http://pandora.nla.gov.au/apps/PandasDelivery/WebObjects/PandasDelivery.woa/wa/tep?pi=10052
- 204. Phipps, L., Witt, N. and McDermott, A. (2005). "To Logo or Not to Logo?" Retrieved February 17th 2008: http://www.techdis.ac.uk/index.php?p=3_8_8
- 205. Powell, A. (2006). Re: DC-Education Application Profile: update + feedback requested. Retrieved ??? from http://www.jiscmail.ac.uk/cgi-bin/webadmin?A2=ind0708&L=dc-education&T=0&F=&S=&P=792
- 206. Powell, A. (2007). note to DC-EDUCATION@JISCMAIL.AC.UK, 13/08/2007 see DC Ed email list on JISC
- 207. Powell, A., Nilsson, M., Naeve, A., Johnston. P., & Baker, T. (2007). DCMI Abstract Model. Retrieved October 18, 2007, from http://dublincore.org/documents/2007/06/04/abstract-model/
- 208. Pulis, S (2008). Application Profile Abstract Model. Retrieved July 10, 2008 from http://dublincore.org/accessibilitywiki/ApplicationProfileAbstractModel
- 209. Pulis, S., & Nevile, L. (2006). "Using the DC Abstract Model to Support Application Profiles Developers" presented at Dublin Core 2006. International Conference on Dublin Core and Metadata Applications. Manzanillo (Méjico). 3 - 6 October 2006.
- 210. QUT Queensland University of Technology. "Map Metadata for Web Site "Testing Website ID 5." Retrieved January 14, 2005, from https://olt.qut.edu.au/Manuals/adminm/Metadata/chapter.htm
- 211. Reding, V. (2007). "Towards an Inclusive Future: Impact and wider potential of information and communication technologies" in Roe, P.R.W. (Ed.) EUR: 22562 ISBN: 92-898-0027. COST: Brussels.
- 212. Regan, B. (2004) - at CSun?
- 213. Regan, B. Retrieved January 15, 2005, from http://www.markme.com/accessibility/archives/006073.cfm re Flash.Retrieved January 15, 2005, from http://www.pbs.org/wgbh/amex/zoot/eng_sfeature/mx/pop_zoot_mx.html
- 214. Regan, R. (2005). Retrieved January 15, 2005, from http://www.markme.com/accessibility/archives/006073.cfm
- 215. REVEALWEB (2006). Retrieved January 6, 2006, from http://www.revealweb.org.uk/catalogue.htm#content
- 216. Resnick, M et al?? (2006). "Computer as Paintbrush:Technology, Play, and the Creative Society" in Singer, D., Golikoff, R., and Hirsh-Pasek, K. (Eds.), Play = Learning: How play motivates and enhances children's cognitive and social-emotional growth. Oxford University Press.
- 217. RNIB, (2000). Get the Message Online. Retrieved November 29, 2007, from http://www.lancs.ac.uk/fss/resources/access/docs/gtmonline.doc
- 218. RNIB, (2003). "Accessible Web Design - exciting new development in Europe" Retrieved July 12, 2008, from http://www.rnib.org.uk/xpedio/groups/public/documents/publicwebsite/public_webaccesseuro.hcsp
- 219. Roe, P.R.W. (2007). Towards an inclusive future: Impact and wider potential of information and communication technologies, p. 2. EUR: 22562 ISBN: 92-898-0027. Brussels: COST. Retrieved April 3, 2008, from http://www.tiresias.org/cost219ter/inclusive_future/inclusive_future_book.pdf
- 220. Rothberg, M. (2007). Private email communications from the Director of the SALT project, responsible for those specifications.
- 221. Romano NC, Jr., (2002). "Customer relationship management for the Web-access challenged: inaccessibility of Fortune 250 business Web sites" in International Journal of Electronic Commerce 2002;7(2):81-117.
- 222. Saffer, D. (2005). Retrieved March 28, 2006, from http://www.adaptivepath.com/publications/essays/archives/000545.php
- 223. Seely Brown, J. (1998). “Research That Reinvents the Corporation,” in Harvard Business Review on Knowledge Management. Boston, MA: Harvard Business School Press, pp. 153-180.
- 224. Schmetzke, A. (2001). Online distance education - "Anytime, anywhere" but not for Everyone. Retrieved December 14, 2004, from http://www.rit.edu/~easi/itd/itdv07n2/axel.htm
- 225. Sheppard, C.L., Laplant, B., & Nevile, L. (2004). Dublin Core and the alternative interface access protocol. NISTIR, 7150. [Gaithersburg, Md.]: U.S. Dept. of Commerce, Technology Administration, National Institute of Standards and Technology. Retrieved ??? from http://ois.nist.gov/nistpubs/technipubs/recent/search.cfm?dbibid=16375
- 226. SiteMorse (2008). Website Survey June 2008 - UK Central Government. Retrieved June 27, 2008 from http://www.sitemorse.com/survey/report.html?rt=409&findings
- 227. Sloan, M (2005). "UK Resources for Web Accessibility and the Law" Retrieved July 12, 2008 from http://www.btinternet.com/~martin.a.sloan/
- 228. Slocum, T.A., Blok, C., Jiang, B., Koussoulakou, A., Montello, D.R., Fuhrmann, S., et al. (2001). “Cognitive and Usability Issues in Geovisualization” in Cartography and Geographic Information Science, 28(1):61-75.
- 229. Smith, E. (2004). "Mathematics Texts for Blind Students: A Cautionary Tale." Retrieved July 9. 2008 from http://www.ozewai.org/2004/presentations/smith.doc
- 230. Steenhout, N (2008). Retrieved July 12, 2008 from http://accessibility.net.nz/blog/it-costs-too-much/
- 231. Stephens, U. (2008). "Social Inclusion". Retrieved April 16, 2008 from http://mediacentre.dewr.gov.au/mediacentre/Stephens/Releases/SocialInclusion.htm
- 232. STSN (2006). Retrieved January 6, 2006, from http://www.stsn.org/servicechart.html
- 233. Taylor, D.R.F. (Ed.) (2006). Cybercartography Theory and Practice ISBN-13: 978-0-444-51629-9 ISBN-10: 0-444-51629-8 Elsevier
- 234. Ternier, S, Massart, D. et al, (2008)."Interoperability for Searching Learning Object Repositories" in D-Lib Magazine January/February 2008, Volume 14 Number 1/2, ISSN 1082-9873. Retrieved July 11, 2008 from http://www.dlib.org/dlib/january08/ceri/01ceri.html
- 235. Thatcher, J., Kirkpatrick, A., & Theofanos, M., (2004). "Prioritizing Web Accessibility Evaluation Data" presented at CSUN 2004, University of California at Northridge, Los Angeles. Cited by Kelly et al (2005).
- 236. The Age (2007).Retrieved ??? from http://www.theage.com.au/news/national/flight-without-sight/2007/04/30/1177788019629.html
- 237.
with the facility for application profiles that contain combinations of these.
As some might see it, DC is providing for infinitely extensible, n-dimensional mapping of resources.
In general, the maps of metadata are not read so much as used in the discovery or identification process. But mapping in this sense is analogous to mapping as we commonly think of it in the cartographic sense. There are rules for the co-ordinates (descriptions) of resources and there are structural rules known in the information world as taxonomies that are topologies. The browse structure of a Web site allows one to zoom in and out on details, and map intersections and location finders are common.
Metadata for Web 2.0
Web 2.0 is not a new Web but it is a world in which resources are distributed and combined in many ways at the instigation of both the publisher and the user. It is not possible to limit the ways in which this will be done and it is not yet clear how to 'freeze' or later reconstruct any given instantiation of a resource. (Arguably, Web 3.0 will be a Web in which this is done by machines (Garshol, 2004).)
There is another aspect of Web 2.0 that is relevant to the work in accessibility. Social interaction on the Web is being generated in many cases by what is known as 'tagging' of resources. These resources are often very small, atomic, objects such as an image, or a small piece of text, or a sound file. While these objects have been on the Web since the beginning, in general they have been published within composite resources where the components have not been separately identified and they have rarely been described in metadata. The move is towards what is known as microformats:
a set of simple open data format standards that many (including Technorati) are actively developing and implementing for more/better structured blogging and web microcontent publishing in general. (Microformats)
Associated with this move is the departure of many Web users from Web site visitations to the use of 'back doors' into information stores. So many people use Google and its equivalent to find what they want and then 'click' their way into the middle of Web sites, that the time has come to think seriously about the role of Web sites. Blogs and wikis as publishing models are increasingly becoming the source of information for many people. The increasing availability of atomic objects, or objects in what is becoming known as micro-formats, is expected to increase the accessibility of the Web.
Taxonomies
With respect to taxonomies, Lars Marius Garshol has the following to say:
The term taxonomy has been widely used and abused to the point that when something is referred to as a taxonomy it can be just about anything, though usually it will mean some sort of abstract structure. ... In this paper we will use taxonomy to mean a subject-based classification that arranges the terms in the controlled vocabulary into a hierarchy without doing anything further, though in real life you will find the term "taxonomy" applied to more complex structures as well. ...
Note that the taxonomy helps users by describing the subjects; from the point of view of metadata there is really no difference between a simple controlled vocabulary and a taxonomy. The metadata only relates objects to subjects, whereas here we have arranged the subjects in a hierarchy. So a taxonomy describes the subjects being used for classification, but is not itself metadata; it can be used in metadata, however (Garshol, 2004).
He then points out that at one level higher, there are thesauri that usually provide preferred terms, wider and narrower terms. Of these he says:
Thesauri basically take taxonomies as described above and extend them to make them better able to describe the world by not only allowing subjects to be arranged in a hierarchy, but also allowing other statements to be made about the subjects (Garshol, 2004).
The ISO 2788 standard for thesauri provides for more details and helps make thesauri more useful for information discovery. The extra qualifiers are similar to those used in metadata definition, such as scope note, use, top term and related term.
Graphical (and interactive) metadata
'Tagging' has become a feature of what many people think of as Web 2.0, the social information space where users contribute to content. This is often done simply by adding some 'tags' or freely chosen labels to others' content. For example, a user may visit a site and then send a tag referring to that site to a tag repository, organised by such as del.icio.us or digg. Typically such tags have values chosen freely by the user and so they may vary enormously for one concept, as well as the concepts associated with tags varying incredibly. In 2006, the STEVE Museum's Jennifer Trant (2006) reported that museum visitors who viewed paintings on a site were prone to submit one tag but a completely different one when they re-visited the same painting remotely or searched for it via a digital image. As indicated below, tags are generally displayed in what might be called a graphical form, for example, in tag clouds. With the increasingly graphical representation of metadata, including tags, metadata maps are starting to emerge. These can be used in a variety of ways, as considered below. Usually, words associated with the tags are not the traditional formal thesauri, as in the case of more structured metadata, but inform what are called folksonomies. These are, in fact, ontologies but with very different characteristics from the more traditional library subject terms and generally not structured; that is, users typically add tags with subject, author, format, etc., all mixed in together. This is not necessary, and some users are precise in their use of tags, including encoding them to relate to standard DC Terms, for example (Johnston, 2006).
In response to the increased use of tags on sites, the author started a community within the Dublin Core Metadata Initiative that is concerned with the relationship between standard metadata and tagging (DC Social Tagging). It is not yet known if tagging is merely a fashion or here to stay as a robust way of getting user-generated metadata but it is of interest to see how users use words, and so might help in the selection of terms for standard thesauri. It is also hoped that the energy available for tagging in the wider community can be harnessed to provide much needed accessibility metadata in the future.
Tags as metadata for resources
Rel-Tag is one of several MicroFormats. By adding rel="tag" to a hyperlink, a page indicates that the destination of that hyperlink is an author-designated "tag" (or keyword/subject) of the current page. (Microformats-2)
Tags are described on the Microformats Web site as follows:
rel="tag" hyperlinks are intended to be visible links on pages and posts. This is in stark contrast to meta keywords (which were invisible and typically never revealed to readers), and thus is at least somewhat more resilient to the problems which plagued meta keywords.
Making tag hyperlinks visible has the additional benefit of making it more obvious to readers if a page is abusing tag links, and thus providing more peer pressure for better behavior. It also makes it more obvious to authors, who may not always be aware what invisible metadata is being generated on their behalf. (Microformats-2)
Typically, tags are gathered and presented in a variety of ways including in tag piles as shown in an extract from an author cloud:

Figure ???: A tag cloud (Library Thing)
Tag clouds have no specific structure (see Figure ??? above). They tend to be simply piles of words, in no particular order except perhaps either alphabetical or temporal, with more popular terms displayed in larger font than less popular ones. Other systems use the graphical representation to show relationships between terms used, displaying the underlying structure in hierarchical, or other maps. Sometimes this is done explicitly, as in the case of the subject terms used in the Dewey Decimal System [DDS], for example, or implicitly, as done with the DC terms, in an abstract model that is completed for any set of actual terms.
Organization schemes like ontologies are conceptual; they reflect the ways we think. To convert these conceptual schemes into a format that a software application can process we need more concrete representations... (Lombardi, 2003).
The simplicity with which tags can be associated with content, and simultaneously find their way into a metadata repository, suggest that this might provide a way to capture metadata for accessibility, particularly for popular sites with a number of visitors. The energy that is apparently available for the tagging process is also of interest: can it be harnessed to produce accessibility metadata about resources?
Topic maps
Lars Marius Garshol describes several types of content organising schemes:
Data Model - A description of data that consists of all entities represented in a data structure or database and the relationships that exist among them. It is more concrete than an ontology but more abstract than a database dictionary (the physical representation).
Resource Description Framework (RDF) - a W3C standard XML framework for describing and interchanging metadata. The simple format of resources, properties, and statements allows RDF to describe robust metadata, such as ontological structures. As opposed to Topic Maps, RDF is more decentralized because the XML is usually stored along with the resources.
Topic Maps - An ISO standard for describing knowledge structures and associating them with information resources. The topics, associations, and occurrences that comprise topic maps allow them to describe complex structures such as ontologies. They are usually implemented using XML (XML Topic Maps, or XTM). As opposed to RDF, Topic Maps are more centralized because all information is contained in the map rather than associated with the resources (Garshol, 2002)
He writes:
When XML is introduced into an organization it is usually used for one of two purposes: either to structure the organization's documents or to make that organization's applications talk to other applications. These are both useful ways of using XML, but they will not help anyone find the information they are looking for. What changes with the introduction of XML is that the document processes become more controllable and can be automated to a greater degree than before, while applications can now communicate internally and externally. But the big picture, something that collects the key concepts in the organization's information and ties it all together, is nowhere to be found.
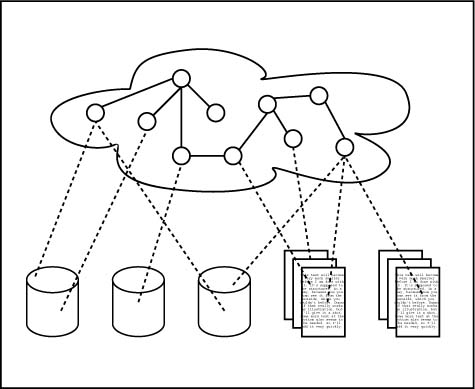
This is where topic maps come in. With topic maps you create an index of information which resides outside that information, as shown in the diagram above. The topic map (the cloud at the top) describes the information in the documents (the little rectangles) and the databases (the little "cans") by linking into them using URIs (the lines).
The topic map takes the key concepts described in the databases and documents and relates them together independently of what is said about them in the information being indexed. ...
The result is an information structure that breaks out of the traditional hierarchical straightjacket that we have gotten used to squeezing our information into. A topic map usually contains several overlapping hierarchies which are rich with semantic cross-links like "Part X is critical to procedure V." This makes information much easier to find because you no longer act as the designers expected you to; there are multiple redundant navigation paths that will lead you to the same answer. You can even use searches to jump to a good starting point for navigation (Garshol, 2002).
Topic maps need not be just for describing the content of the resource, such as the subject of the resource. They could be used to describe the accessibility characteristics of that content.
Faceted classification, according to Garshol, was first developed by S.R. Ranganathan in the 1930s.
and works by identifying a number of facets into which the terms are divided. The facets can be thought of as different axes along which documents can be classified, and each facet contains a number of terms. How the terms within each facet are described varies, though in general a thesaurus-like structure is used, and usually a term is only allowed to belong to a single facet ...
In faceted classification the idea is to classify documents by picking one term from each facet to describe the document along all the different axes. This would then describe the document from many different perspectives (Garshol, 2004).
In Rangathan's case, he picked 5 axes. There has been significant work on faceted classification and recently it has been demonstrated as a powerful and useful way to use metadata. Again, this technology could be used to present accessible versions of resources to different communities of users.
Garshol's list of classification systems includes categories, taxonomies, thesauri, facets and then ontologies. He argues that as we progress through the list we are getting more expressive power with which to describe objects for their discovery. Of ontologies, he says:
With ontologies the creator of the subject description language is allowed to define the language at will. Ontologies in computer science came out of artificial intelligence, and have generally been closely associated with logical inferencing and similar techniques, but have recently begun to be applied to information retrieval.
He goes on in this article to describe topic maps as an ontology framework for information retrieval and to show that topic maps have a very rich structure for information about an object that is also quite likely to be interoperable. As his example he gives:
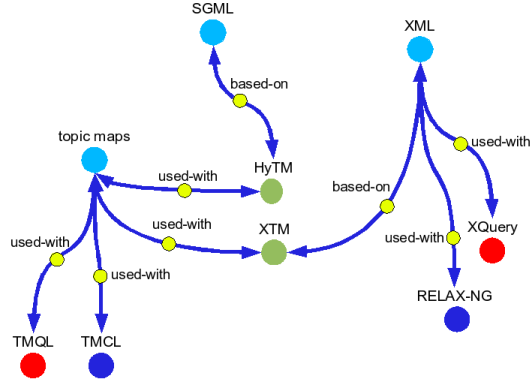
Figure ???: Topics maps as an ontology framework
The colours have significance as shown:
| Identifier | Meaning |
| round discs | names of topics |
| arrows | associations |
| aqua | occurrences of a topic |
| blue | vocabulary languages |
| red | query languages |
| green | markup languages |
| yellow | these show the association types |
| Note: | different colours could be read as scope of topic names, or type of topic |
| colour legend | |
Ontopia's Omnigator is a tool that allows the user to click on any topic name and have it become the 'centre of the universe' with its connections surrounding it. This makes interactive navigation around the graphical maps very simple and intuitive, and seamless across topic maps encoded differently [Ontopia]. The same idea could be used to group resources with particular accessibility characteristics.
Resource Description Framework
In a similar way, the Resource Description Framework (RDF) provides a very flexible way of mapping resources. RDF requires the description of properties of resources to be strictly in the form:
resource ----- relationship ----- property
or
subject ---- predicate ---- object
as in
http://dublincore.org ---- has title ---- Dublin Core Metadata Initiative
The theory is that if all the properties are so described, it will be easy to make logical connections between them. Currently, RDF is implemented in XML, as that is the language of most common use today, but the framework is independent of the encoding. RDF maps, like other good metadata systems, are interoperable and extensible. An example of RDF maps and how they interoperate is provided in Figures ??? and ???.
 and
and 
Figure ???: Two fragments of the Semantic Web
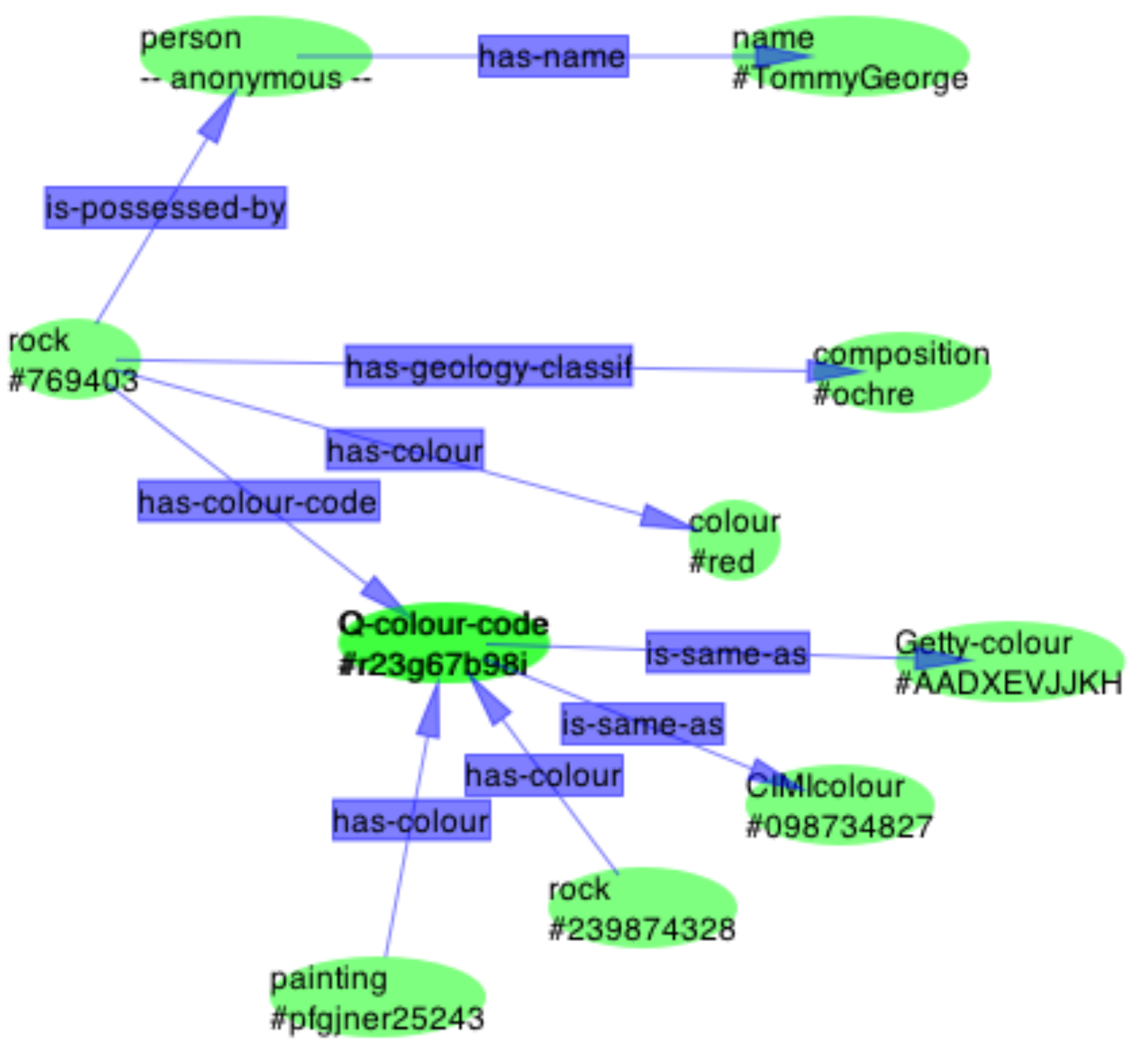
Figure ???: ???
Figure ??? The two map fragments in Figure ??? as combined simply by overlaying the matching entities Q-colour-code #r23g67b98i to form the greater map (Nevile & Lissonnet, 2003).
One of the features of graphical maps that is of interest to those with vision disabilities, and many programmers, is that graphical programming is, when undertaken with the right tools, simultaneously graphical and textual. This is the same as for traditional geospatial maps, where databases often hold the data and where they can be interrogated by users who do not choose to work graphically (sometimes just because of the complexity and enormity of the graphical representation). This is also typical of the way CAD designers work. RDF or Semantic Web maps are also of interest because of their potential to automatically make connections with alternative forms of the same or similar content.
The progression through the various metadata technologies provides an insight into the possibilities that can be exploited in there is suitable AccessForAll metadata available for resources.
Cross-walks and mappings
The interoperability of metadata is considered one of its strengths and it has, in its short recent history, led to many institutional digital libraries sharing their metadata to develop what operate as united libraries, following a range of organisational and technical models. Where sets of metadata are to be combined for some purpose, such as integration, if the metadata sets are not based on the same standards, it is often possible to map them both to a third set of metadata terms so they can be shared, even if with some loss.
The mapping can be loss-less when the two systems are fully compatible but often this is not the case and some compromises are made. Dublin Core metadata, for example, follows the flat model of one property for each metadata statement and all properties can be repeated and none but the identifier of the resource are mandatory. IEEE Learning Object Metadata (LOM), on the other hand, is deeply hierarchical, that is, a property can also have sub-properties and the sub-properties can have their own sub-properties. Mapping from LOM to DC metadata is not possible without loss at this stage, in general, although it is possible to do some mapping from LOM to DC when RDF encoding principles are applied (not the general case).
Chapter summary
It may be, as some would suggest (Vickery, 2008), that the most important thing in the Web today is the facility to find things. Metadata, of one sort or another, is essential to this process and hence its significance in Web research and development worldwide. It is not a new topic, but it is attracting unprecedented attention, and the technical complexity of it has grwn significantly. In the next Chapter, there is a discussion of yet more specificity about metadata, this time accessibility metadata.
Chapter 7: Accessibility Metadata
Introduction
Given the Dublin Core as a huge base for international, cross-domain metadata, it seemed obvious when the research started with accessibility and metadata that the two should be combined. First, it is necessary to establish that there is a reasonable chance that there will be metadata about accessibility of resources. It is also important to know if there are, as proposed, Web services that adapt resources for users. Finally, in this chapter, the relevant pre-history of the Dublin Core's role in AccessforAll accessibility metadata work is explained.
Existing accessibility metadata
There is always, in the mind of metadata experts. experience that shows that metadata is expensive to produce and that it is very often inaccurate. For this reason, it is important when proposing a new use or context for metadata, to be sure that it is necessary, not overly-complicated, and likely to be created and used. This section locates the current research in a world that is already partially prepared for it. Showing that there is a substantial amount of discoverable material in a range of formats suitable for people with varied needs and preferences is important if there is to be more work in finding a way to describe the necessary needs and preferences and the resources that might satisfy them. Thus, the quantity of discoverable material is indicated within this section. In addition, unless the new descriptions can be used alongside those already in use, that is, unless there are existing descriptions that are interoperable with the new ones, there is not much point in undertaking the research. What follows shows that there is sufficient material and provides a base against which the new metadata should be interoperable.
Sources of accessible resources and their descriptions
The Royal National Institute for the Blind (RNIB)
In the UK, the Royal National Institute for the Blind (RNIB) has developed and maintained the National Union Catalogue of Alternative Formats.
Ann Chapman, in "Library services for visually impaired people: a manual of best practice" (2000), states that only 5% of the 100,000 new British titles published each year were converted into alternative formats. She points out that these formats were created by a range of individuals and organisations and made available in a number of different ways and places. "In 1989 R.N.I.B. began the process of computerising its card catalogues, thereby creating the National Union Catalogue of Alternative Formats (NUCAF)". Prior to this date, the RNIB had a catalogue of its own conversions and for five years prior to the establishment of the NUCAF, was spasmodically collecting catalogue records from others.
She continues,
As part of the Department for Culture, Media and Sport funded programme to improve library and information services to visually impaired people, the role of NUCAF was reviewed in 1999 (Chapman, 1999). The review concluded that a national database of resources in alternative formats was an essential tool in service provision and that while NUCAF in its present form had limitations, particularly in respect of access, it did provide a good basis for a more comprehensive database of resources." ...
It further recommended that the new database should primarily cover the output and holdings of the specialist non-commercial sector, and that collaborative agreements with existing databases and union catalogues should be developed to cover the commercial sector publications." The review pointed out that, "In addition to libraries, a range of agencies (doctors, dentists and health professionals, banks, advice centres, electricity, gas and water companies, tourist offices, schools and academic institutions, government departments, and service providers of various kinds) would either use the database or refer people to it. Currently visually impaired people and those working to support them are restricted to a few narrow avenues of access to NUCAF. The new database will be designed to be far more widely accessible to end users and library staff. To achieve this it was recommended that the national database should be held on a web-based system, supported by CD Rom and electronic file versions.
Eventually, as a result of various funding opportunities and projects carried out in a number of places, NUCAF was merged into a new service called REVEAL. In "Project One part A: The future role of NUCAF and a technical specification of the metadata requirements", Chapman (1999) reported "The national database should where possible use national and international standards. It should use the UKMARC format and conform to AACR2. Current RNIB subject indexing should be used for subject indexing, and LCSH entries retained where they exist in the records for the original items. A single set of headings for fiction genre/form should replace the existing ones. A full set of the data elements required has been identified."
These were found to be:
· Basic Bibliographical details (Title, author(s), publisher, date of publication, edition, series, and subject.)
Search Support (Subject indexing, fiction genre and form indexing, target audience, format type.)
Decision Support (Annotation or content summary, target audience, series and character information, serial frequency, abridgement notes, narrator or cast notes for audio materials, format type and level, number of units comprising the title, serial holdings information.) Also desirable: sample passages, serials article indexing.
· Support for inter-library lending and Loans (Holdings, locations, loan status)
· Support for sale and hire (Availability status and charge, producer/hirer/retailer
· Support for production selection (Statement of intention to produce, format, producer, copyright permission details.)
· Record format
· Subject indexing
· Genre indexing
While NUCAF had catalogue records for many items, they were only items converted for the benefit of users with vision disabilities and they did not include representations in all formats or modes of access. Initially, they did not include commercially produced formats and they were expected to be catalogued only so they could be discovered, as was typical of the understanding of the use of metadata at the time (1999). The MARC21 007 fields provide for quite specific information about the form of tactile representation of information such as that it is contracted Literary Braille or 'spanner short form scoring' of music.
At 2.4, Chapman points out that the existing NUFAC's "only clearly defined objectives are those that relate to stock management and production management at the RNIB. It is therefore difficult for it to satisfactorily address functions outside the RNIB". She asserted that given the difficulties associated with copyright with respect to the transformation of information into alternative formats, the new data base would need to do more. She did not think of computers at that time as being able to automatically decompose information resources and recompose them to suit the needs and preferences of users. Her final recommendations included that, "The database must provide data rich bibliographic records".
At the time, the Library was UK’s most comprehensive collection of material on the subject of visual impairment. The resultant REVEALWEB, at the beginning of 2006, boasts 100,000 resources in accessible formats (2006). This is indicative of the quantity of material that could be made available for use by people with vision disabilities, and therefore all others who are for one reason or another not using their eyes as they might to view content.
REVEALWEB's formats are:
· Braille
· Braille Music (based on the same six dots as traditional Braille letters but in addition there are separate symbols for each note, key, tempo and duration)
· Moon (a line-based tactile code in which many of the letters are simplified versions of the printed alphabet that is easier to learn than Braille and helps many older people continue to enjoy reading for themselves)
· Braille with Print
· Moon and Print
· Tactile maps and diagrams (produced by either photocopying or printing onto heat sensitive 'swell' paper)
· Audio cassettes 2 track (often produced with the author or an actor reading the printed word)
· Audio cassettes 4 track (that need special equipment for playback)
· Talking Books 8 track (digital audio files on CD)
· CD-ROMs spoken word
· DAISY (DTB) format (Digital Accessible Information System that enables navigation)
· Electronic text files
· Electronic Braille music files
· Electronic Braille files
· Large Print
· Audio described videos. (RevealWeb, 2006)
Given the size of this collection of well-described, discoverable materials, it is important that any new metadata descriptions are interoperable with this list. There is every indication that these resource are described with standard metadata and therefore could be used by an AccessForAll service.
National Library Service for the Blind and Physically Handicapped (NLS), Library of Congress
The USA also has a union catalogue maintained by the Library of Congress National Library Service for the Blind and Physically Handicapped (NLS). The Union Catalogue (BPHP) and the file of In-Process Publications (BPHI) can both be searched via the NLS Web site [NLS].
Indicative statistics for the NLS (according to those posted on 2005-01-11) are:
Each year it distributes 23 million books and magazines to a readership of more than 759,000 individuals who cannot read regular print for visual or physical reasons. NLS functions as the largest and frequently only source of recreational and information reading materials and services for a segment of the population who cannot readily use the print materials of public libraries. The NLS International Union Catalog contains 382,000 titles in 22 million copies. (NLS, 2002)
The formats available appear to be press Braille, digital Braille (Web-Braille), audio cassettes, large print text, digital text, maps (tactile), electronic resource, music (Braille), music (large print), and sound recordings (NLS, 2006).
In a fact sheet, NLS explains: "Currently, this service includes the acquisition, production, and distribution of Braille and recorded books and magazines, necessary playback equipment, catalogs and other publications, and publicity and marketing materials" and that, "One of the primary reasons for instituting a national program was to obviate the inevitable difficulty and high cost for individual libraries to acquire books in special formats" (NLS About, 2006). In a sense, this is the same motivation as is being suggested in this thesis for the development of a metadata standard for AccessForAll materials.
The Library of Congress uses standard metadata and it is this collection of resources is therefore evidence that there are alternatives available for immediate use by people with disabilities and that they are already described by suitable metadata. They could therefore be used by an AccessForAll service.
NCAM, the National Center for Accessible Media at WGBH
NCAM, the National Center for Accessible Media at WGBH in Boston have developed software and techniques for making media of all sorts available to all people. As part of this process, they have developed a clever way of distributing captions and descriptions (known as MOPIX) to theatre and cinema goers. Currently there are more than 300 films available with captions and descriptions (MOPIX, 2006).
Other services
The American Printing House for the Blind [APH] currently hosts the Louis Database of Accessible Materials for People who are Blind or Visually Impaired. The Louis Database contains over 145,000 titles of accessible materials, in braille, large print, sound recordings and computer files, from over 200 agencies throughout the United States. The database can be searched via the database Web site and there is a link to the NLS Web site and union catalogue database.
The Canadian National Institute for the Blind operate a number of services including online access to their library collection via VISUCAT. The library collection contains over 45,000 titles with materials in braille, print braille, audio, electronic text and descriptive video. Access to the catalogue is via a telnet connection. Library clients can search VISUCAT, check on titles currently on loan to them and reserve titles.
Vision Australia has a new major project that will augment the work already done by a number of organisations to provide people with vision disabilities with services for better accessibility.
The relevant organisations clearly have a lot of resources to offer and many of these already have standard metadata describing them. It can be assumed that if such resources can be used more frequently and discovered more generally, it is likely that their value will increase and more of them will be made available.
Dynamic Content Adaptation Services
There are two kinds of content adaptation services: those that adapt the components of a resource to fit a given specification and those that in some way adapt the components, such as converting text into Braille. As well as static, or held content, there are services for creating accessible content - some of which work on-the-fly and others which can be used asynchronously.
Component adaptation services
The Speech-to-Text Services Network
For some time the Speech-to-Text Services Network [STSN] has been making accessible content alternatives for content that cannot be used by people with hearing disabilities. They describe their three real-time speech-to-text services according to the technology used to process incoming speech:
The STSN has a table that shows differences and similarities among their services. This table also makes clear the sort of services that are valued by people with hearing disabilities. Some of these are relevant in the current context because they represent services that some people will use when they cannot access auditory information.
| Steno machine-based Stenography Systems - CART | Laptop-based Speed Typing Systems | Automatic Speech Recognition Systems (ASR) |
| Verbatim, or near-verbatim translation, i.e., word-for-word | Meaning-for-meaning translation, i.e., "all the meaning in fewer words" | Communication access usefulness determined by ASR software error rate, reader's error tolerance, skill of speaker, etc. |
| Typist who is trained court reporter | Typist who is trained in specific system | Trained "Shadow" speaker |
| Info Link CART | Info Links ASR, CaptionMic, iCommunicator, Liberated Learning Initiative |
Table ???: Services offered by the Speech-to-Text Services Network (STSN 2006)
As is apparent from the table, human services are provided to render the content accessible to those who are not able to hear it in its original form. Such services exist alongside new ones being developed like those offered and proposed by ubAccess, particularly SWAP that will utilise computers to perform 'intelligent actions' on inaccessible content.
ubAccess
ubAccess has developed a wizard Semantic Web Accessibility Platform SWAP, that can transform a given Web page to have characteristics that will suit users with special needs. As this service depends upon knowing the users' needs, it is appropriate for it to be considered as an example of the type of service that will be enabled by the AccessForAll approach to accessibility.
Component selection services
There are many services that are built into content servers that could be described as adapting content, or components of aggregate content, into suitable composites for users. In general, these are driven by the device and software requirements. The materials delivered to a telephone by a standards compliant browser will at least attempt to adapt the resource for that device. For example, the Opera browser can present the user with a newspaper page in a way that makes sense to someone with a very small screen, as shown in Figure ???. Opera has recently released a browser for general use that contains a screen reader.
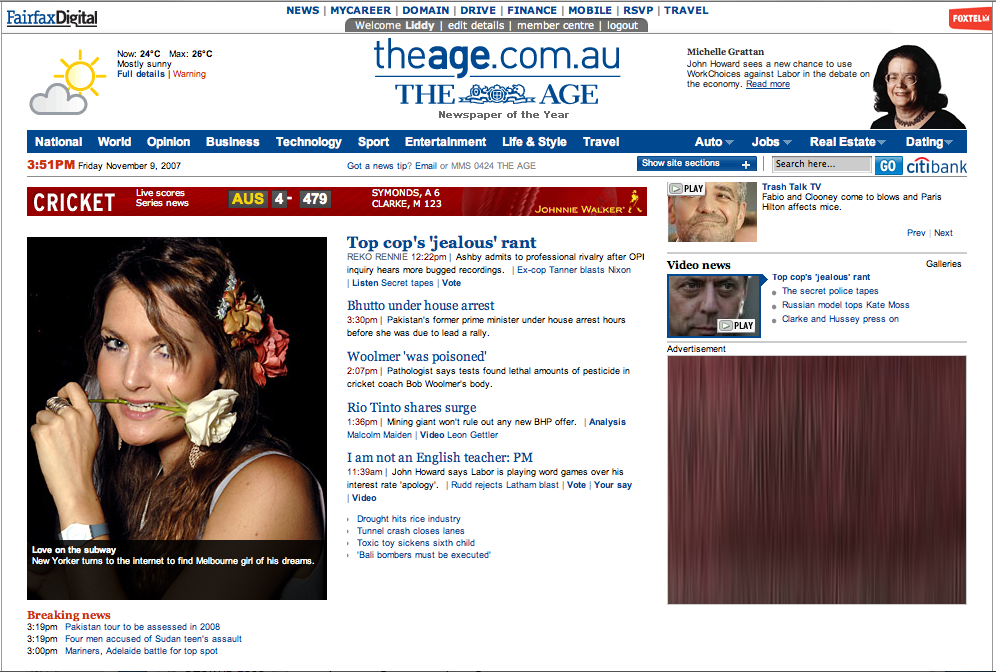
Figure ???: Front page of the Age newspaper on 9/11/2007 in Safari and Opera Mini showing headlines so phone users can easily select what to read or look at.
Dublin Core accessibility metadata
The early DC accessibility work is relevant because it cleared the way for the AccessForAll approach that has become to main work of that group.
The Dublin Core Accessibility Working Group was founded in 2001 to investigate the use of metadata in accessibility work (DC Accessibility Working Group, 2001). There was a follow-up joint Meeting of W3C WAI Interest Group and IMS Accessibility Working Group, Melbourne, November 2001 (WAI-IG, 2001). The aim, at the time, was to be proactive in setting an accessibility agenda for content developers by bringing their attention to the need for accessibility, as much as to provide functional metadata. Some time later, a Director of DCMI, Eric Miller, strongly defended this position at a DCMI Advisory Committee (as it was then) meeting and there was general support within that Committee for the work.
Over a number of years the following efforts to find a way to define accessibility metadata were promulgated.
AccessForAll and DC metadata
The early work on the AccessForAll approach has been described. Now the special requirements for Dublin Core metadata are considered.
The 'rules' for DC metadata have always been that the metadata terms must comply with the Dublin Core model. That the model has not, until late in 2007, been expressed in an unambiguous way made this process very difficult. Once the accessibility work left the fold of the DC and was led elsewhere based on another type of metadata, the best that coulld be done was to ensure that the new metadata matched as closely as possible the DC model, and that it was at least possible to cross-walk without loss from one system to another.
Given the changing nature of the DC model, there were many iterations of the AfA metadata in an attempt to match the model but they always seemed to fail to do this. Once the model became stable, it was possible to determine the requirements once and for all and the most recent version of the abstract model of the DC AfA metadata appears to do this.
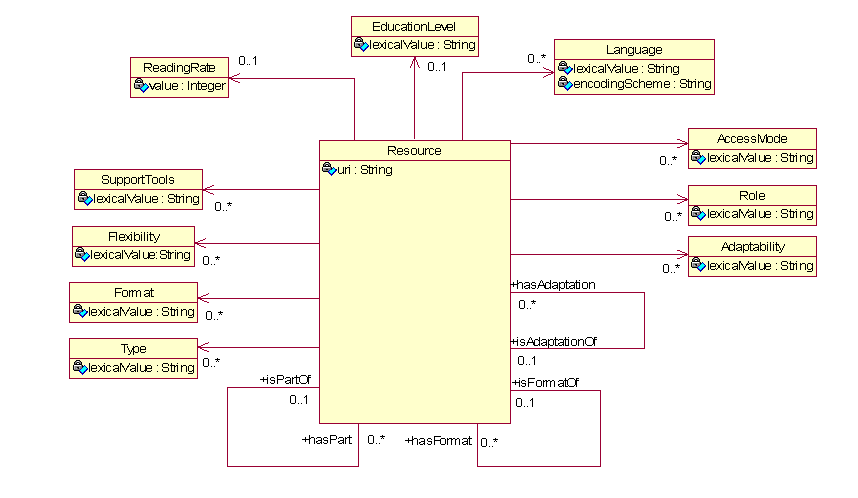
Figure ???: Accessibility Abstract model (Pulis, 2008)
This model and the associated vocabularies have not been formally adopted by DC, which requires the approval of the DC Usage Board, but it has been informally accepted as now matching the rules. Achieving this status required input to the DC process of definition of that abstract model, as well as the development of this one to match it (Chapter ???; Pulis & Nevile, 2006).
Ensuring metadata is not too complicated to be useful
In 2007, Andy Powell had the following to say in the context of educational metadata:
so what does history teach us? Why are we where we are now? I would argue that the "effort aimed at distilling semantics & simplifying them through delivering sufficient consensus across a significant community of practice" essentially failed. It failed because the approaches reached thru that consensus cost more to implement than the benefits they realise in the context of the original use-case (resource discovery on the Web).
When was the last time you found something because it had been described using DC?
What history tells us is that DC is too complex for the 'simple' resource discovery scenarios envisaged when the initiative started. Those scenarios now tend to be catered for by full-text indexing and social tagging of one form or another. At the same time DC is not complex enough for the scenarios typically found in digital libraries, scholarly communication, elearning, commerce and the like.
Yes, the DCMI Abstract Model tends to move us more towards the latter. Yes, explicitly modelling the entities in the world that we want to describe is more complex than not doing so.
Complex but necessary. All IMHO of course.(Powell, 2007)
In a sense, the metadata being proposed for accessibility is very complex but it is meant to be used differently in different circumstances. The typical use of it is with a single term (Dublin Core or other) where the values identify limitations to the perception mode for the content. The research shows that this information alone will make a huge difference to discoverability for a user. Then, when a resource is made or catalogued by experts and designed to satisfy an accessibility problem, those who have developed it can use their expertise to give maximum value, and exposure, to the resource.
Accessibility metadata and WCAG 2.0
The final stages of development of the WCAG 2.0 specifications were under way as the AfA metadata has been finalised as an ISO standard. Convincing the W3C Working Group responsible for WCAG 2.0 to include a requirement for AfA metadata would have made all WCAG 2.0 conformant resources suitable for adaptation according to AfA principles. For a number of reasons this was not possible, not the least being that the WCAG authors were not prepared to simultaneously allow that a resource might be less than conformant to the rest of WCAG and yet 'legitimately' be described by metadata as specified by WCAG. They did consider it important to allow for the use of metadata, however, especially to identify an alternative resource that could be used by a user when that alternative had special feature to make it more useful than a standard, conformant resource, and the original was already WCAG conformant. Given the inclusion of this as a technique, there is, of course, no reason why a developer should not provide full AfA metadata and if there are tools that make this easy, it might happen. Such tools are promised for demonstration at the September 2008 Dublin Core conference in Germany.
Chapter summary
In this chapter, the availability of resource that will already have metadata is investigated for two reasons: if there are, in fact, no alternative components that are accessible to people with disabilities, there will be nothing to find, and secondly, because if such accessible components do exist, it is important that they are organised and described with electronic catalogues that are capable of providing metadata, even if it needs to be transformed to comply with the interoperable standards.
Chapter 8: User needs and preferences
Introduction
Given that universal design alone is not able to cater for the needs and preferences of all users, even when the principles embodied in the WCAG specifications are complied with, and that is not often as has been shown, it was timely when a complementary approach was suggested by the ATRC at the University of Toronto. Already there was a prototype system operating that could match resource components to user-determined requirements (TILE) when the work was shared with those at the IMS Global Learning Consortium (IMS GLC). At this time, the author was working with the IMS Global Learning Consortium for IMS Australia (Australian Department of Education, Science and Technology) ). The first task had been a set of guidelines for educators about accessibility (Barstow and Rothberg, 2002). These guidelines were developed at about the same time as the Accessible Content Development section (Appendix 8), and both showed the inadequacy of the then current work. The adoption of a complementary approach that would take into account the needs and preferences of individual users might make a difference.
In fact, the AccessForAll approach was a significant development and only the beginning of a chain of developments that has most recently led to the FLUID Project, a major user-interface architecture re-design project directed from the ATRC.
The first part of this chapter is a modified version of a paper for the 2005 Dublin Core Conference (Nevile, 2005b). It presents the case for a private (anonymous) personal profile of accessibility needs and preferences expressed in a Dublin Core format. It introduces the idea that this profile, identified only by a URI, is motivated by a desired relationship between a user and a resource or service. It assumes a new Dublin Core term DC:Adaptability (since renamed back to to DC:Accessibility) and argues that, without any reference to disabilities, personal needs and preferences, including those symptomatic of common physical and cognitive disabilities, context or location, can be described in a common vocabulary to be matched by resource and service capabilities.
Individual differences
As explained above, everyone, at some time or another, is disabled by the circumstances in which they find themselves and most people, as they age, will experience disabilities more often. Most people will find their disabilities vary according to the circumstances in which they are operating. Disability, in this sense, is a description of a poor relationship between a person and their immediate operational requirements.
Similarly, it is inappropriate and inaccurate to attribute descriptions of disabilities, which are descriptions of relationships, to named people. At the same time, it is efficient to recognize that many relationships are similar and that when involved in a user-resource relationship, many people will want to use the same description of that relationship. For instance, many blind people trying to access a Web page with images will want to use similar profiles of non-visual relationships between a user and a resource.
The existence of a machine-readable profile of a disability relationship can be used, by suitable applications, to match users with resources and services they can use. This process involves a description of a user's immediate needs and preferences being matched with a description of the components of a resource or service until there is no disability. This may involve the replacement, augmentation or transformation of components of the resource or service, such as changes of sensory modality. The user's descriptions of their needs and preferences, often called their profiles, will be used according to the context or circumstances and may differ according to the occasion. For convenience, a user will want to store and refer to such profiles rather than to create them afresh every time one is required. In some cases, they will depend upon profiles created for them by others and, in such cases, may be especially dependent on their being stored and available at all times.
Accessibility profiles
An accessibility profile for use by a blind person attempting to read a newspaper online will be very similar to that for a person driving a car wanting to access Google News: both users will want vision-free access to the resource. Both users will need alternatives to visual content contained in the primary resource they seek and both will want to control their access to that resource using non-visual techniques. It is unlikely that either of them will want to see the 'Google ads' that would normally accompany the content on a screen presentation. A simple description of the relationship with the resource they seek will be non-visual. The description of the characteristics of this relationship, the user's needs and preferences profile, should be simply expressed in machine-readable form and available to any resource publisher. It can be identified by its URI and does not need to contain any information about any individual or community of people. It is, in fact, a description of functional requirements and could be known simply as non-visual functional profile "x".
A more complicated example occurs where, for whatever reason, there is a need for a visual relationship but the objects being viewed need to be larger than they might be when used on a stand-alone desktop computer. Such a case occurs frequently when resources are displayed on a large screen before a large audience. For this to be an accessible relationship, it does not need to be non-visual but there are some qualifications to be made to the visual qualities: the text and images need to be enlarged. Exactly how large the text should be will usually be decided by the author in a situation where the details of the relationship are well-known, as for the large audience, but should always be available for customisation where individuals may have special needs.
Flexibility of the kind required in this case means there needs to be a common way of describing the range of sizes of text and images so that the correct accessible relationship can be indicated by the user. Responses to the description of the relationship in such a case may depend upon the transformability of the resource components: scalar vector images will be easily transformed to suit such requirements and text that is to be presented according to cascading styles should be suitably transformable but, if it contains tables, there will be more complicated considerations.
In some cases, it is not a transformation of available components that is required so much as their replacement or augmentation. Such a case exists where a non-auditory relationship is required with, for example, a movie. Then, a text transcription of the background sounds might need to be supplied with captions for all speech. These may all need to be synchronized with the visual content. Where the only problem with the aural content is likely to be the choice of language, captions might be required but the background sounds will not be a problem.
Accessible resources and services
The provision of resources and services that ensure the correct accessible relationship for a user depends upon the existence of many components all with special accessibility characteristics. Captions for films are usually made by organizations known as caption houses: caption houses specialize in making captions but not films. Signing for people who use sign languages is usually done by specialists in that field; videos of signing that might be needed to complete an accessible relationship are likely to come from a source other than the original publisher of the resource.
In other words, the components that may be required to complete an accessible relationship with a resource or service are often distributed and may be the result of cumulative authoring. All that is necessary is that the components are available just-in-time for delivery to the user. Very often, as is obvious from the examples already given, they may be combined in different ways for different user/resource relationships. This means it is most convenient to not fix them to a particular relationship with any one resource, but to maintain them separately and make available the necessary metadata for them to be discovered and fetched when needed. The same metadata can be used to identify a need for more components in anticipation of a demand for them.
The definition of accessibility implied here is that the relationship between the user and the resource is one that enables the user to make sensory and cognitive contact with the content of the resource. This is expected to occur at the time of accessing the resource or, in other words, to be achieved just-in-time. This is the definition being advocated as the AccessForAll definition of accessibility.
In addition to the availability of the necessary components to satisfy the relationship required by the user, there is a requirement for the metadata that will be used to arrange the final composition of the resource. There is also, of course, a need for a way of communicating the requirements, or the metadata. The vocabularies and common specifications for their description are the topic of this chapter. W3C was working on similar issues in their Device Independent Working Group and their focus is on what they call the Composite Capabilities and Personal Preferences specifications [CCPP].
Relationship Descriptions
Organising the possibilities for resource relationship descriptions means ensuring that the characteristics are uniquely described. Such organisation is common but can take some time to determine. Fortunately, the ATRC has been requesting needs and preferences for people with disabilities for some time, and they have reliably determined the best way to 'divide up' the characteristics for user needs and preferences profiles.
There are three sensory modalities universally recognized as relevant to the current human-computer relationship: visual, auditory and tactile. Smell and haptic modalities are not yet often included. There are many possible variations of the modalities and their roles can be important: auditory input and output are not necessarily related to a user rather than their context. In a library, one may be able to listen with headphones but asked not to use voice input; in a car, general auditory output may be acceptable and voice input may be essential. While input and output are useful distinctions to make, in some cases, in the case of accessibility, the ATRC uses three classes: display, control, and content characteristics (TILE). As this is not a relevant area of research, the practice of the ATRC was simply copied.
For people who use adaptive technologies with special settings, describing their control needs and preferences may mean providing information about the settings for their personal adaptive technology, especially when that requires something like an on-screen keyboard to be activated by a head-pointer. In the case of an on-screen keyboard, the display characteristics of the resource also need to be adapted to allow for the loss of screen space for display purposes. In addition, there may be requirements for other display characteristics, and there may be separate needs for content adjustment. Particularly for users for whom settings are crucial to their engagement with resources, needs and preferences need to be distinguished. If a need cannot be fulfilled, their preference for what to compromise can make all the difference. For others, if flexibility is possible, it can mean greater satisfaction. For accessibility reasons, it is essential that the user's profile always overrides all other profiles, as is the case with cascading style sheets (W3C, 1999).
As the requirements can conflict in combination, determining a structure for their representation that allows for them to be described fully and unambiguously is essential. For this reason, descriptions of needs and preferences for display, control and content characteristics need to be separated. The needs and preferences need to be easily describable, so it is essential that if there are no special needs, nothing needs to be described, but that when there is a need, there is a hierarchy of details that are easily understood and registered.
In addition to the three categories described and their details, there is an over-riding quality that is essential in the human-computer context. Usability is not a technical quality but it can be the most significant quality when user resource interactions are required. It is not included as a technical characteristic of AccessForAll but it must be considered. Figure ??? shows the classes of characteristics proposed by the ATRC for AccessForAll for digital resources.
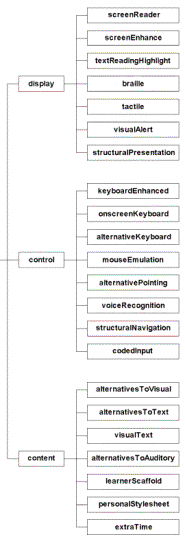
Figure ???: AccessForAll structure and vocabulary (image from AccessForAll Specifications, [IMS Accessibility].
Display descriptions
Where there can be no effective visual relationship with resources and services, all visual displays need to be presented in some other modality. Often the choice is for auditory presentation of the visual content but it may be for tactile displays such as Braille or other tactile forms. Where the adaptive technology does not change the modality but changes the characteristics of the display, as in the case where screen-enhancing software is being used, the requirements for the desired display may involve object sizes, colour, or placement on the screen. The requirements can be very detailed and vary depending on the circumstances. Changes in the modality of content, as occur when a screen reader renders visual content (text) as auditory content, may depend upon it being possible to transform the content in this way. This in turn will depend upon the form of the original content: it can be transformed easily unless there is formatting, for example, that interferes with the process. The ‘transformability' of the text will need to be described if it is relevant to the user's relationship with the text.
Tables ???, ??? and ??? show the potential characteristics (attributes), how many there may be and what kind of values are expected.
| Attribute | Allowed Occurrences | Datatype |
| screen reader preference set | Zero or one per Display Preference Set | Screen_Reader_Preference_Set |
| screen enhancement preference set | Zero or one per Display Preference Set | Screen_Enhancement_Preference_Set |
| etc | etc | etc |
Table ???: 6.2.1 Display Preference Set (Treviranus et al, 2005)
| usage | Zero or one per Screen Reader Preference Set | Usage_Vocabulary |
| screen reader generic preference set | Zero or one per Screen Reader Preference Set | Screen_Reader_Generic_Preference_Set |
| application preference set | Zero or one per Screen Reader Preference Set | Application_Preference_Set |
Table ???: 6.2.2 Screen reader Preference Set (Treviranus et al, 2005)
and
| font face preference set | Zero or one per Screen Enhancement Generic Preference Set | Font_Face |
| font size preference | Zero or one per Screen Enhancement Generic Preference Set | Positive integer |
| foreground color preference | Zero or one per Screen Enhancement Generic Preference Set | Color |
| background color preference | Zero or one per Screen Enhancement Generic Preference Set | Color |
| etc | etc | Etc…. |
Table ???: 6.2.9 Screen Enhancement Generic Preference Set (Treviranus et al, 2005)
Control descriptions
Not all users control their systems using the typical mouse and keyboard combination. In some cases, they use assistive technologies that effectively replace these devices without any adjustment but in others they use technologies that require special configuration. An on-screen keyboard will use screen space that will have to be denied to the resource or service. Any resource or service that cannot accommodate this loss of screen space, for example because it demands a full-screen display for all controls to be available, will not be suitable for use in some circumstances.
It is necessary to be able to capture what is necessary with proprietary devices and systems as well as what is generic to types of systems and devices. It is also necessary to be aware of possible developments so there is room for extensions. A typical example of the definition of these needs is as shown:
3.2.41
text reading highlight generic preference set
a collection of data elements that states a user's preferences regarding how to configure a text
reading and highlighting system that are common to all text readers/highlighters, regardless of vendor
3.2.42
text reading highlight preference set
a collection of data elements that states a user's preferences regarding how to configure a text
reading and highlighting system (Treviranus et al, 2005)
These definitions have been represented in a structured hierarchy so that it is easy for users or their assistants to provide only as much detail as is necessary. Nevertheless, due to the complexity of dealing with the multitude of possible needs, the vocabulary is very large.
Content descriptions
The relationship between a user and a resource or service will also be accessible only if the content is perceptible by the user. Perception in this sense includes the case where a dyslexic person needs more than the usual image-based content because they cannot process a text-heavy resource; or where a person with neurological damage, such as a stroke victim, can not manage a screen that is too ‘busy', or where a blind person is working with an explanation that is based on an example that is useful only to people with vision. It is often the case that the original content has to be supplemented, perhaps with the availability of a dictionary or captions, or replaced by different content that achieves the same outcome but in a different way. Information about the resource that indicates that it contains such alternative content, or the location of such content that is available externally, is needed to determine if the user will be able to form an accessible relationship with it in terms of perception.
Metadata models
The original IMS GLC approach was to add the AccessForAll element into the established hierarchy of the IMS Learning Resource Meta-Data Information Model Version 1.2.1 Final Specification (2001).
Whereas the DCMI metadata model provides several ways in which a DC metadata set can be extended whenever necessary, the LOM requires the extensions to be determined in advance:
In particular, most elements have <application> and <param> elements that allow additional parameters to be defined for a particular accessibility application. In addition, the binding provides for arbitrary extensions. See the Binding Guide document for more details. In general, these extension methods are provided as placeholders for future revisions of this specification. Both the <display> and <control> elements provide for sub-elements named <futureTechnology> which are intended to allow new technology approaches to be included (Jackl, 2003, Sec.4.1 Extensibility Statement).
Figure ??? shows the structure of the extension mechanisms in LOM.
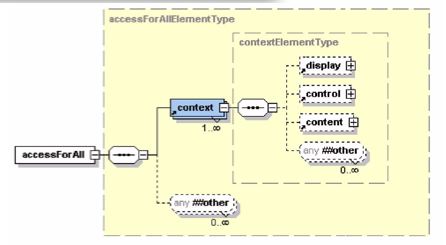
Figure ???: Access Extensibility Statement (Jackl, 2003).
Not only is the model hierarchical (see Figure ???) but the thinking was. If one has thought for a long time with a particular model, and is obliged to implement systems in a hierarchical environment, it is very difficult to think otherwise. This problem was acute for some time with the group working on AfA metadata but it led to very lively, activity as the participants struggled to make the AfA work as interoperable as they could, trying to accommodate both the hierarchical LOM model and the 'flat' DC model. The challenge was insurmountable but it led to very thorough efforts and what all parties in the end agreed was at least an elegant solution. There was considerable confidence that in the end it could, indeed, be implemented in both LOM and DC without loss, even if this did depend on a cross-walk from one to the other.
Profiles of user needs and preferences
User needs and preference profiles are of no use if they are not available when they are needed.
Web-4-All uses a smart card to provide a portable set of user needs and preferences for adaptive devices and software available within a device. These cards were designed to make it easy for users of computers distributed throughout Canada and for those managing the computers. The computers are fitted with suitable adaptive technology and a card reader. By inserting or extracting the cards, users can set up the computers, use them, and then leave them in a basic state for other users, without the need for a technician.
The paper presented at the 2005 Dublin Core conference argued that if the resource or service's capacity to adapt to different user needs and preferences is described in a Dublin Core element, the individual user's needs and preferences also should be described in Dublin Core format (Nevile, 2005b). It proposed a resource that contains information about a user's needs and preferences; what in some contexts is being called the user's Personal Needs and Preferences (PNP) and a metadata record of that resource.
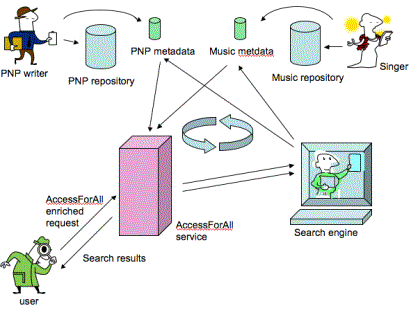
Figure ???: Diagram showing cycle of searches and role of AccessForAll server
It reiterated the argument that in order to match a resource or service to a user to achieve accessibility, there is no need to identify the user. All that is required is machine-readable information about their needs and preferences.
The need for this paper lay in the fact that the more common use of DC metadata which was to describe an object. Previous attempts to encourage the DCMI to extend their way of working to include descriptions of people (Nevile & Lissonnet, 2004), even though that was often practised, were still being resisted. It was later discovered that this was because the person is usually not the resource that is being described, but the author of it, and so descriptions of the person are not really properties of the resource. In some cases, however, it has been of interest to describe people using DC style metadata, for example where an organisation uses software that manages DC metadata and so could be used to manage metadata about the people in the organisation as well.
In the case of the AccessForAll situation, the person is not being described, deliberately. In fact, the description is a profile of their functional needs and preferences relative to a context. This was, at the time, very contentious, particularly as it was not well-understood by the author that there was the historic problem that was worrying the experts. It was also difficult because, as explained earlier, some of the decisions made in the formation of the initial set of DC terms were made in the knowledge that they could lead to difficulties later on, and this was a typical case of what could highlight the problems with the early DC models. In addition, of course, there were potential problems with the model being used at the time for the semantics of the user needs and preferences profiles that would raise the hierarchy vs flat metadata issues. (In the end, the DC model has moved more closely to that of the Semantic Web and there is less emphasis on this issue because it is no longer relevant in the way that it was.)
The paper presented a way of thinking about some of the problems.
An application profile for user accessibility needs and preferences that satisfies the requirements needs to contain one vital element; the DC:identity of the information (resource) expressed as a URI. This URI must, therefore, point to the user's accessibility needs and preferences information which should be in a machine-readable form. Users may like to think of profiles as being associated with certain contexts, for instance the lecture theatre version, or the JAWS lap-top version, and in such a case the profile could be named. So we could find DC:title being used for this. The application profile may contain more DC elements, such as DC:subject, DC:description, DC:creator, etc. None of these need identify the user for or by whom the AccessForAll information will be used. On the other hand, they may clarify who could take advantage of the profile: for instance, all students in a lecture theatre will probably share the need for large print on the overhead screen. This could be explained in a DC:description element. It may be of interest to know who developed the user needs and preferences profile, so DC:creator could be used to indicate this. The date of a profile might be significant when new versions of adaptive software are released so DC:date may be useful. (Nevile, 2005b)
A shared profile
In general, the paper argued, a profile will be for a single person, sometimes from within a class of people, such as someone with Jaws with the default settings, for instance. The profile could cater for a combination of users, however, with a combination of needs and preferences, even asking for redundant components so that everyone in the group has what they need. It is very common for a person with a disability to be working with someone who has different needs. In fact, some users' needs include a person who can assist them. This may or may not mean they have special functional requirements for the resources they want to access.
When a system is to be used simultaneously by two users who point to different profiles, it may depend on the circumstances how this is to be handled. If they are to share a screen, their needs will have to be harmonized. If they are working on the same application but separately, as when two remote users share a chat session, their individual needs should be accommodated. When the two users are, for example, a corporate group for whom there is a corporate set of ‘needs and preferences' that conflict with the individual's essential needs and preferences, the latter should be matched in preference to the former.
Table ??? shows a typical set of user needs and preferences that might be used as a default set for some users with some specific values indicated.
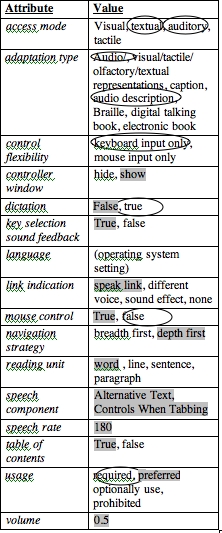
Figure ???: A typical set of user needs and preferences showing the default and the user's individual choices.
User needs as a resource
By rendering the user's needs and preferences profile as a resource, problems associated with the politically unpopular activity of labeling people by disabilities can be avoided. The technical problem that a single person will be associated with a number of AccessForAll profiles is also avoided as they can point at different times to any of a range of profiles. In addition, where there is a need for many users to share a profile, as with students in a lecture theatre, this is easily achieved. This approach was difficult to work within the DC rules for profiles but on a day in 2007 when it became very important to solve the problem if metadata was to be included in the forthcoming WCAG Version 2.0 (W3C WCAG 2.0, 2008a), a W3C Working Group considering a similar problem, released their first version of the POWDER protocol. The POWDER protocol provides a way for exchanging metadata about a resource but it also defines a collection of metadata as a resource, in that case establishing the useful term 'description resource' (W3C POWDER, 2008). This seems very appropriate.
A system working on the match, to ensure accessibility, will read the AccessForAll profile selected by the user (or user group) and use that information to test the metadata of potential components for the resource or service to be delivered. In the absence of an AccessForAll profile, systems will have to assume that a user has no special needs to constrain their relationship with resources and services at that time.
Accessibility Vocabularies
At this point it should be noted that while the user's PNP is described by a metadata record, it is itself metadata in another sense. The value of this is that it can be used in conjunction with resource metadata in the matching process for accessibility.
The vocabularies for the metadata to be associated with the resource or service and with the user's needs and preferences for accessibility have been carefully matched in the AccessForAll profiles. Other technical device information might also need to be conveyed to the resource server but it is expected to be covered by the work of the W3C Device Independence Working Group or others using CC/PP.
For all preferences, usage is required to determine if the user must or must not have it or if they merely have a preference for the setting. Flashing content, for example, can be dangerous for some users and content with nothing but graphics will be useless to a blind person unless they have a friend available to describe it to them.
As the values of the descriptive elements are what is matched once the elements have been matched, it is important that there is a standard vocabulary available to be used for those values. This can occur several ways: a recommended form such as yyyy-mm-dd or mm--dd-yyyy, an encoding conformant to some set standard, such as Getty colour schemes, or what is called a controlled vocabulary - a set of words with definitions. All these rules need to be available to any matching software. It is very often possible to adopt existing standard vocabularies as has been done throughout the AccessForAll profiles. For example, the vocabulary for settings for dynamic Braille displays; AccessForAll has no reason to redefine it.
Chapter summary
In this chapter, the redefiniton of accessibility that assumes all people have accessibility needs, or alternatively that these are just part of the environment, suggests a way in which the three areas of concern to users of digital resources might record their needs and preferences: diplay, control and content. In the next chapter, the matching characteristics of resources that users might access are examined.
Chapter 9: Resource Profiles

Figure ???: What do we need to know about an object for accessibility?
Introduction
The AccessForAll specifications are intended to address mismatches between resources and user needs caused by any number of circumstances including requirements related to client devices, environments, language proficiency or abilities. They support the matching of users and resources despite [some universal accessibility] short-comings in resources. These profiles allow for finer than usual detail with respect to embedded objects and for the replacement of objects where the originals are not suitable on a case-by-case basis. The AccessForAll specifications are not judgmental but informative; their purpose is not to point out flaws in content objects but to facilitate the discovery and use of the most appropriate content for each user (Jackl, 2004).
The AccessForAll specifications are part of the AccessForAll Framework. They do not specify what does or does not qualify as an accessible Web page but are designed to enable a matching process that, at best, can get functional specifications from an individual user and compose and deliver a version of a requested resource that meets those specifications. It depends upon other specifications (such as WCAC) for the accessible design of the components and services it uses.
Having a common language to describe the user's needs and preferences and a resource's accessibility characteristics is essential to this process. That is why the resource descriptions proposed below so closely match the descriptions of the needs and preferences of individual users. It is not essential, however, for there to be a matching process for there to be value in having a good description of the accessibility characteristics of a resource. In the discovery and selection processes, a user can take advantage of such a description and at least be forewarned about the resource.
It should be clear that, as AccessForAll does not specify the functional characteristics of Web content, but rather the specifications for the description of those characteristics, it is not intended to support any claims of conformance of resources to other standards and specifically, not conformance to the WCAG specifications. On the other hand, the WCAG specifications might well be used to determine the characteristics of the resource, such as if the text is well-constructed, or if images have correct alternatives. AccessForAll specifications are only concerned with metadata.
(A significant amount of the content in this chapter has been published (Nevile, 2005a) or has been contributed to other documents (Barstow & Rothberg, 2002; Jackl, 2004; Chapman et al, 2006).
Primary and equivalent alternative resources (or components)
The AccessFprAll (AfA) way of organising metadata has to take into account that most resources are thought of as having a set form with modifications for accessibility purposes. This is not an inclusive way of thinking of resources, and it is not what is emerging as the model on the Web. Given the technology, resources are being formed at the time of delivery, according to the delivery mechanisms available and the point of delivery, but often resulting in many very different manifestations. AfA is designed to contribute to, in fact take advantage of, that process.
Matching users and resources involves not only the user's needs and preferences from a personal perspective, but also accommodations for their access devices. Figure ??? shows a single Web page rendered by 10 different access devices, not including any that don't produce visual displays of any kind:
Figure ???: Multiple instantiations of a single Web page (HFI-testing).
AfA metadata is also designed to facilitate the just-in-time adaptation of resources to make them accessible for individuals. This process depends on metadata being available so it can be used to manage the substitution, complementing or adaptation of a resource or some of its components.
Given that most resource publishers do not know much about accessibility, and have been shown to not do much about it, it is assumed they will not be very careful about what metadata they contribute to resources, if any. For this reason, there has been an effort to find the minimum that makes a difference and is easy to write, with the hope that those who do more about accessibility, either making better resources or fixing others, are more inclined and better informed about what metadata to use. In cases where a resource contains or is intimately linked to alternatives, such as where there is an equivalent resource like a text caption for an image, the metadata for the resource should indicate this and provide metadata for both versions of that component. It is handy for one component to be referred to as the 'primary' component and for the other as the 'equivalent alternative'.
Equivalent alternative resources are of two types: supplementary and non-supplementary. A supplementary alternative resource is meant to augment or supplement the primary resource, while a non-supplementary alternative resource is meant to substitute for the primary resource. Although in most cases the primary and equivalent alternative resources will be separate, a primary resource may contain a supplementary alternative resource. For example, a primary video could have text captions included. In this case the resource would be classified as primary containing an equivalent supplement. A primary resource can never contain, within itself, a non-supplementary resource (Jackl, 2004, Sec. 3.2.1 Equivalent Alternative Resource Meta-data).
The AfA metadata is tightly specified and very detailed. This is not done in ignorance of the practicalities of metadata that suggest it should be very light-weight, easy to create, etc.. It is this way because people with disabilities have special needs. They use technologies that are built specially for them and that means for a small market given the range of different devices they need. This does not mean that the market for standardised accessibility metadata is small - it can be shared across all the different adaptive technologies and beyond them to great benefit. It means rather that it is very important to be very precise about the metadata and to maintain its stability very carefully so that adaptive technology device and software developers can be assured of the stability of the functional requirements for metadata and thus reliable availability of that metadata. There is not the usual room for tolerance when not having something means having no access to information for someone. Thus, the threshold for interoperability is high in this context.
The personal access systems used by people with disabilities can be seen as unique external systems that need to interoperate with the system delivering the resource. These personal access systems must interoperate with many different delivery systems. The personal access systems must also adjust frequently to updates or modifications in an array of delivery systems. For these reasons it is important that the delivery systems tightly adhere to a common set of specifications with information relevant to accessibility. To promote interoperability this information should be found in a known consistent place, stated using a consistent vocabulary and structured in a consistent way. To support this critical interoperability the AccessForAll specifications offer less flexibility in implementation than other specifications (Jackl, 2004, Sec. 3.2.4 The Importance of Interoperability for Accessibility).
The WCAG architecture treats resources as single entities despite the fact that it may take a number of files to form a Web page. This is not how resources are understood in AfA architecture:
Content can be considered either atomic or aggregate. An atomic resource is a stand-alone resource with no dependencies on other content. For example, a JPEG image would be considered an atomic resource. An aggregate resource, however, is dependent on other content in that it consists not only of its own content but also embeds other pieces of content within itself via a reference or meta-data. For example, an HTML document referencing one or more JPEG images would be considered an aggregate resource. The use and behavior of AccessForAll Meta-data for atomic content is straightforward. .... For aggregate content, the required system behavior is slightly more complex but it still involves matching. In other words, if the primary resource is an aggregate resource, then the system will have to determine whether or not the primary resource contains atomic content that will not pass the matching test. If so, it will examine the inaccessible atomic resources to determine which resources require equivalents. This means a primary resource must define its modalities as inclusive of those of its content dependencies (Barstow & Rothberg, 2002).
Creation of reliable metadata
As the required metadata is quite detailed, there may be some concern about who will produce it. Even where the metadata is created by a well-intentioned party, there may be a question about how reliable it is. Fortunately there are a number of applications available that help with the description process and even do some of it automatically.
There are a number of tools for the authoring of metadata but in the accessibility context, there are tools for assessing accessibility that also produce metadata. Many of these produce their reports in a language called Evaluation and Report Language [EARL]. EARL provides a way to encode metadata such as AfA metadata. EARL requires all statements to be identified with a time and the person or agent making them. This makes it easier to identify the source of the description for trust purposes. EARL statements are generally intended to convey information about compliance to some stated standard or specification. This information is typical of what is needed for accessibility. An example is an EARL statement that includes information about the transformability of text determined by reference to the relevant WCAG provisions.
The AccessForAll metadata specifications
The original IMS AccessForAll specifications were very closely based on the specifications developed by the ATRC for TILE. These were subjected to rigorous scrutiny because of the need to satisfy the other stakeholders involved but the attributes of interest were assumed to have been well-identified by the ATRC. As those specifications were advanced through the ISO/IEC process, they were subjected to scrutiny and some modifications were made. These are not important in the sense that they are details about attributes that can be adapted and adopted within the framework. What is important here is how the framework operates and how the specifications work.
Just as the user will want to define three classes of attributes of personal needs and preferences, there are three classes of attributes of digital resource to be described using AfA metadata. They are the control, display and content characteristics.
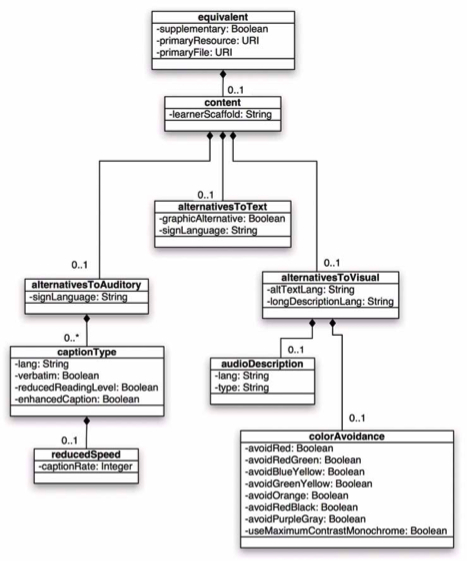
Figure ???: IMS structure for accessibility metadata from 2.3, Page 7, AccMD Norton, 2004
As can be seen in Figure ???, the original structure of this metadata was deeply hierarchical. Somehow, it needed also to be represented as 'flat' Dublin Core metadata. This was achieved by using the DC structures but only interoperable with the assistance of cross walks. 'Depth', in Dublin Core metadata, is achieved by having qualifications of elements that comply with DC rules for such qualifiers. DC qualifiers constrain either the element itself or the potential values of those elements, by providing such as an encoding scheme or a controlled vocabulary. To achieve this in Dublin Core form, it was necessary to reconsider some of the elements so the final DC version is not merely a flattened version of the hierarchical IMS model.
This is most easily shown by a sample mapping from one form to the other. In the case of the LOM version, to indicate that a resource is a text alternative to an image, the following encoding would be used:
alternative >> alternative resource content description >> altToVisual >> textDescription >> French, caption
while the same information would be conveyed using the DC version, by:
accessMode: textual
isTextDescriptionFor: URI of the original component being made accessible; caption
language: French
While both systems can provide the same information, it can be seen that the DC model leaves the language independent of the type of resource (caption) and these properties need to allied while both these pieces of information are specific to the textDescription of the altToVisual of the alternative resource content description of the alternative.
The research involved finding a way to do this for all the information, satisfying both the requirements for IMS GLC and the ISO/IEC metadata definition, and for the DCMI community. Based on the hierarchical model of the IMS version, an equivalent version was developed according to the DC model. This meant ensuring that none of the deeply embedded information in one model was not available in the shallow format of the other. The two hierarchies (Appendix 7) allow for all the information that is available for an IMS profile to also be available in a DC profile. So long as this is done correctly, that is, so long as the DC rules for elements and application profiles are observed, the metadata can be encoded in a number of ways, particularly in HTML, XML and RDF(XML).
The DC rules state:
At the time of the ratification of this document, the DCMI recognizes two broad classes of qualifiers:
Element Refinement. These qualifiers make the meaning of an element narrower or more specific. A refined element shares the meaning of the unqualified element, but with a more restricted scope. A client that does not understand a specific element refinement term should be able to ignore the qualifier and treat the metadata value as if it were an unqualified (broader) element. The definitions of element refinement terms for qualifiers must be publicly available.
Encoding Scheme. These qualifiers identify schemes that aid in the interpretation of an element value. These schemes include controlled vocabularies and formal notations or parsing rules. A value expressed using an encoding scheme will thus be a token selected from a controlled vocabulary (e.g., a term from a classification system or set of subject headings) or a string formatted in accordance with a formal notation (e.g., "2000-01-01" as the standard expression of a date). If an encoding scheme is not understood by a client or agent, the value may still be useful to a human reader. The definitive description of an encoding scheme for qualifiers must be clearly identified and available for public use (DCMI, 2000)
Originally, qualifiers of elements were explicitly declared with a syntax of the type DC:<term>:<qualifier> but now they are just used as terms as in DC.<Qualifier>. This does not mean they do not follow the rules, but once this is established, they are used alone. That a term is a qualification of another is of significance when the metadata is being transformed for some purpose: a qualified term's value must make sense as the term's value, according to what is called the dumb-down rule. This often introduces some loss of specificity, but at least means that the information can be transferred without loss. It also accommodates what might otherwise be hierarchically structured information.
What it is hoped that the DC verison of the AccessForAll principles can do that would not be likely with other forms of metadata, is to provide a way for all resources to be classified and made available with accessibility metadata. DC metadata is used in many countries to describe government information, in libraries and museums around the world, within software applications such as Photoshop and MS Word, widely in education, and by international agencies such as the Food and Agriculture Organisation (FAO). There is an inordinate amount of DC metadata in existence. If that can be both harvested for use in accessibility, and interwoven with accessibility metadata, the hope is that the vast quantities will make the difference that only quantity can make - the network effect will become a possibility. This can be achieved by using the correct form. The example above shows the alternative captions in French. If the captions are, in fact, from a collection of resources for French speaking people, and the collection is described as using the French language, this would imply the captions are French. This information might not be available otherwise when the language of the captions is being questioned. (This is an example of how the use of the Semantic Web and Topic Maps can help with accessibility, as shown in Chapter 6).
Facilitating discovery of alternatives
One of the significant outstanding challenges for the metadata work is how to use these new specifications when it is not clear what the alternatives are and so a search is required to locate suitable alternatives. It is envisaged that the specification of display and control characteristics will not be a problem beyond the existence or otherwise of the necessary metadata but finding suitable alternative content may be a challenge. TILE has so far only worked with content developed with accessibility in mind and so can guarantee the availability of the necessary combinations of components.
Typical problems for the discovery of suitable content are exemplified by two scenarios:
· There is a film of the play Hamlet with XXX and YYY as the lead actors. Those who cannot see the film but can hear it will require a description of the action but those who cannot hear it will need a description of the sound effects and the dialogue.
· The dialogue has been documented in the past (by Shakespeare) so a text copy with the appropriate control and display qualities will satisfy their needs but it may need to be synchronised with the action in the film, so there will be a need for a synchronisation file (a Synchronised Multimedia Integration Language (SMIL) file, for instance). If this is not available, at least having access to the dialogue should satisfy many users’ needs but if the user is trying to work on the relationship between actions and dialogue in the play, they will need the synchronisation file. If the film does not follow the Shakespearean script, then there may be an issue with finding a text version of the film’s dialogue. Again, depending on the immediate user’s purpose, this may or may not matter.
· It has been suggested that the work defining the functional requirements for bibliographic records [FRBR] provides some guidance as to how the appropriate alternative content might be located (Morozumi et al, 2006).
and
· There is a Web site that contains resources for students working on economic modeling. The Web site contains a number of diagrams that are integral to the text available and yet cannot be viewed by a blind student undertaking the course. Her university has a policy that requires all materials to be accessible to all students and in cases where this is not immediately true, allows the university staff to create the necessary alternative content within 24 hours of receiving a request for it. It so happens that the diagrams in the course materials were taken from another source where they were used differently from in the course: in the former case they were used to demonstrate economic trends and in the latter to show how certain economic models are diagrammed. As the blind student has never seen graphs and does not have any facility with them, they are not suitable for her as illustrative unless they are accompanied by significant other descriptive information. As the graphs were generated from databases, however, there is material that would be suitable for her in the form of database material.
· This example shows the use of content in a quite different form and format from that originally made available but, again, needs to be discoverable. It is not obvious that it is available and so the only way of finding it would be to search for material with the same content as the originally offered diagrams, taking no notice of the purpose of those diagrams in the original teaching resource, and then substitute the database content for the diagram. This means looking for content that is described differently from the content to be replaced but which serves the same purpose for the user.
In order to make it possible to discover alternatives, it may be necessary for descriptions of the content of resources to be mulitply-layered, as in the case of a 'FRBR-type' description. Such descriptions are not yet common on the Web, but it is apparent from work in some quarters that this may be the case in the future (Denton, 2007).
User Interfaces
In this chapter, the possibility of user interface adaptation is considered as an extension of the AccessForAll model. First, a project being undertaken simultaneously with the AccessForAll work is discussed, and then some new work that has been started only since the emergence of the AFA model.
This chapter contains writing that was part of a paper about universal remote control devices that was co-written by the author (Sheppard et al, 2004).
A universal remote control
At the time when the early AccessforAll work was being undertaken, Gregg Vanderheiden and a number of people from the National Institute of Standards and Technology [NIST] and elsewhere were working on a universal remote control (URC) in a technical committee working on standards for the InterNational Committee for Information Technology Standards [INCITS/V2/] in the area of Information Technology Access Interfaces. The aim of the URC was to be able to give a person with disabilities a single remote control device that would be able to talk to a range of devices. For example, they might use the URC to control their front door, garage door, car locks, office doors, office elevator, home air conditioner, microwave oven, etc.
The idea was that the remote control device would interact with the main device, say an oven, to obtain information about the controls available on that device, and then construct an interface setup that would allow the user to talk to the main device using the URC and the new 'skin'. This work led to some interesting problems such as those associated with a lift. If a person goes into a lift well in a modern building, they usually have to press a button to hail the lift, then another to indicate where they want the lift to stop, and then another to shut the door, if it is not already shut, and then maybe one to hold the door open for a bit linger while they exit the lift. All this button pressing is very difficult for some people with disabilities, and very confusing for a person with a vision disability. The URC was designed to enable them, in this situation, to simply press a button to indicate where they wanted the lift to stop. The URC should be able to transmit information to attract the lift, take it out of the usual pattern synchronising it with other lifts in the same location, hold the doors open for longer than usual, or as long as is required, and then to close the doors, go to the destination, and open the doors again for longer than usual before merging back in to the pattern.
The author was involved in this work at an early stage to advise on the possibilities for the descriptions necessary for the URC and the devices it would interact with. By 2006, it was also being considered as an international standard, this time by ISO/IEC JTC1 SC35.
The URC specifications
As with other AfA specifications, the goal is to develop a common description language so that computers can interchange descriptive information and make use of it.
An URC is capable of being used with a range of devices, in a range of languages, and with a variety of accessibility features. It is, in fact, no more than a platform on which intelligence is loaded in real time for the benefit of users confronted by other devices. The type or brand of device is not important if the URC protocol is observed as each device can have skins and information specific to its needs and comply with the generic URC specifications for that type of device.
So URC compliance is about metadata standards: the description of device and user needs and commands in URC specified ways makes for a common language that can be used any time by an URC, in any context for a user.
Wireless communication technologies make it feasible to control devices and services from virtually any mobile or stationary device. A Universal Remote Console (URC) is a combination of hardware and software that allows a user to control and view displays of any (compatible) electronic and information technology device or service (which we call a “target”) in a way that is accessible and convenient to the user. We expect users to have a variety of controller technologies, such as phones, Personal Digital Assistants (PDAs), and computers. Manufacturers will need to define abstracted user interfaces for their products so that product functionality can be instantiated and presented in different ways and modalities. There is, however, no standard available today that supports this in an interoperable way. Such a standard will also facilitate usability, natural language agents, internationalization, and accessibility (Sheppard et al, 2004).
Disabled people are obvious beneficiaries of this technology but others, too, will want a more convenient way to control things in their environment.

Figure ???: A user with a voice-controlled URC and a seated user employing a touch-controlled URC (Gottfried Zimmermann).
The definition of a stable URC standard will enable a target manufacturer to author a single user interface (UI) that is compatible with all existing and forthcoming URC platforms. Similarly, a URC provider needs to develop only one product that will interact with all existing and forthcoming targets that implement the URC standard. Users are thus free to choose any URC that fits their preferences, abilities, and use-contexts to control any URC-compliant targets in their environment.

Figure ???: A wheel-chair user struggling to reach an ATM (HREOC (with permission).
URC Metadata
We are using the Dublin Core Metadata Element Set (DCMES) to describe and find the additional resources that may be needed by a URC using the AIAP. The metadata for the AIAP defines a set of attributes for specifying resources. Text labels, translation services, and help items are examples of such resources. The metadata also defines the content model needed to interface with suppliers of such resource services.
The [Alternative Interface Access Protocol] AIAP metadata is being defined in multiple phases, two of which have been identified. The first phase deals with the identification of resources so that they can be found and used. Phase 2 involves establishing metadata for identifying targets (devices or services), classes of interfaces and user preferences. Taxonomies will be identified or developed for classifying values for each of these major areas (Sheppard et al, 2004).
FLUID
Fluid is a new project that also aims to provide choice of suitable interfaces to people with disabilities, this time for interaction with digital resources.
Fluid is a worldwide collaborative project to help improve the usability and accessibility of community open source projects with a focus on academic software for universities. We are developing and will freely distribute a library of sharable customizable user interfaces designed to improve the user experience of web applications [Fluid].
Fluid expects to develop an architecture that will make it possible for users to swap interface components according to users' needs and preferences, following the AccessForAll model. This project at the time of writing had started with a demonstration of a drag-and-drop interface alternative for people with disabilities (Fluid Drag-and-Drop).
As with other AfA projects, it is essential that there is a common language for describing user needs and preferences and similarly, a matching set of descriptors for interface components.
Chapter summary
In this chapter, resource description metadata is considered. Primarily, the research has been about the use of metadata to manage digital resources with which users are presented but, as shown, this process could be used for a wider range of resources and in a wider range of contexts. indeed, there are subsequent parts to the original metadata already being developed by ISO/IEC JTC1 SC 36 and other projects are already underway elsewhere. In the next chapter, the process of matching a resource to a user's needs and preferences is considered.
Chapter 10: Match and interoperate
Introduction
In this chapter, after considering the process of matching of resources to users, interoperability and the role of the Functional Requirements for Bibliographic Records [FRBR] are considered. The matching of resources to users' needs and preferences can be simplified when all the required components are available within a single context but is more complicated when they are either distributed or not yet available. When automated matching is not possible, it can still be done manually.
The close relationship between the FRBR model and accessibility metadata is slowly being recognised in the AccessForAll context as it is being realised simultaneously in emerging general metadata standards such as the Metadata Encoding and Transmission Standard [METS]. For accessibility, this is important because while those working in accessibility have for a long time been considered to be technical experts in encoding languages, due to the prominance of WCAG in the context, it may become more an issue for those information managers with library skills.
This chapter contains content from various presentations at the AusWeb 2005 Conference in Queensland, Australia (Nevile, 2005c); DC 2006 in Manzanillo, Mexico in 2006 (Morozumi et al, 2006), and an ASK-IT International Conference in 2006 in Nice, France (Nevile, 2006).
Matching
AccessForAll is a strategy for increasing accessibility by exploiting available technologies to match digital resources to users' individual accessibility needs and preferences. This is achieved just in time for the delivery of resources to users by working with descriptions of an individual user's accessibility needs and preferences and relating them to descriptions of a resource's accessibility characteristics. This strategy supports cumulative and distributed authoring of accessible components for resources where these are missing, and the reconfiguration of resources with appropriate components for users.
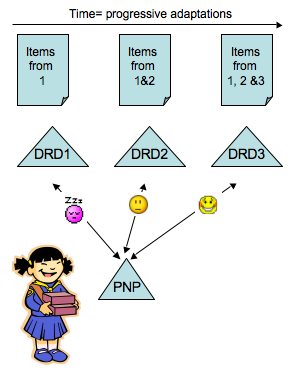
Figure ???: As the items are adjusted for matching to the user's PNP, their DRD more closely matches the PNP.
Assembling Web resources in an integrated way for delivery to the user is defined as just-in-time accessibility and can increase the availability of accessible resources. Moreover, compared to resources that are accessible to every potential user, universally accessible resources, these resources are less expensive, easier to develop (in terms of skills required), and developed using more satisfactory practices for authors and publishers. In addition, the provision of accessible content can be improved so significantly by the use of specifications-compliant accessibility tools, adopted by moderately competent computer users with no accessibility training, that it is cheaper and more effective to rely on the technology than yet-to-be-developed high-levels of human expertise.
The new approach involves a shift of responsibility from individual authors to technology and a supporting community. The shift means increasing responsibility in the final provision of resources, and thus, of server software but also content authoring tools. Where components are not universally accessible, e.g. well-formatted text that can be rendered in a variety of forms such as auditory, visual, and tactile, they may need to be re-written either in a universally accessible form, or with extra components to replace or supplement the existing components. The servers need to check the resources and possibly arrange for services to manipulate and reassemble them before delivering them. The accessible components need to be suitably described to enable their discovery. The components that constitute the final resources may be distributed. This means there is a need for metadata standards that promote interoperability. Finally, there is a need for descriptions not only of resources but also of user needs and preferences.
Accessibility is defined by AccessForAll as the matching of delivery of information and services with users' individual needs and preferences in terms of intellectual and sensory engagement with resources containing that information or service, and their control of it. Accessibility is satisfied when there is a match regardless of culture, language or disabilities (Ford & Nevile, 2005). For individual users, matching their needs is of primary importance and in some cases critical to their ability to function. It should be noted, however, that this does not mean some users only want resources that are dull or boring but simply that resources should be adjusted and adapted to suit the stated needs of individual users at the time so everyone can have what will be best for them.
Howell (2008) says,
Businesses are now investing a good deal more time and money into optimising ‘user journeys’ to ensure that the people using their sites find the route to making a purchase (or finding the information they are looking for) as quick, easy and enjoyable as possible.
I think of this as a pyramid. Web accessibility is the foundation. Usability by disabled people is the next layer. And both of these underpin the ultimate goal: excellent user experiences by disabled people (and everyone).
A logical extension of this gives the pyramid an apex:
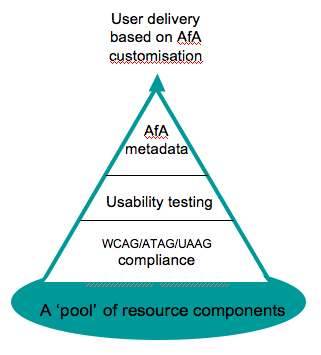
Figure ??? A pyramid based on the Howel model of accessibility ????
The value of metadata
What is significant, beyond the usual benefits from working with metadata before the final delivery of the resource, is that metadata is not the resource; it is not necessarily created by the same author as the resource, and it can always be added to, authored by someone else. It can be created by the resource author and stored as part of it or with it or it can be created by a complete stranger to the resource author and stored elsewhere. It can also link two or more resources that were not initially linked in any way. For increased accessibility of a resource, a third party may author a new component and use metadata to link it to the original resource. Where the original resource is well described in metadata, this may make for a new composition of the resource, avoiding any components that cannot be used by the particular user, and delivering only those that are useful, whatever their source. Where the original resource is not well described, that can be done after the event as well, and again, by a third party.
An example of the difference between the former approach of depending on the production of universally accessible resources and the shift to combine the use of metadata is well illustrated in the Australian universities context. As in many other countries, Australia has anti-discriminatory legislation that means any student at a university has the right to accessible versions of all the resources provided for students. A typical university will interpret this to mean that they must author all resources in universal accessible format (and typically will do this for only 3% of the resources) whereas a university using the AccessForAll approach could notify a student who has recorded their user requirements that a resource is not suitable for them and either re-author it or find a suitable alternative and link it to the original by metadata. It is true that a typical university can attempt to author an accessible version of the original resource but it is notoriously difficult to make an inaccessible resource accessible; finding alternative resources already in the chosen format, where successful, is much easier. (The reasoning here is based on the evidence provided in earlier chapters reporting quantitive assessments of accessibility.)
Providing materials that are accessible within 24 hours of a request would be considered much better than having only 3% of the resources available. It would probably make the resource suitable for that student while universally accessible does not always achieve this, and it would be possible to add to the metadata of the original resource so that next time a student searches for it, there will be more options available. It is perhaps relevant to repeat here that, without metadata, a universally accessible resource is unlikely to be found by someone who needs it. The AccessForAll approach being advocated means a shift from just-in-case to just-in-time and, as in many other circumstances, the latter can be much more economical (and, in this case, achievable).
Component reuse
One of the reasons Web developers use metadata is because it allows them to dynamically compose Web pages. They can develop components and then templates for various different sections of their Web site and have them dynamically composed just as they are to be delivered. This makes maintenance of content easier and can support accessibility, depending on the templates and tools being used. In some cases, re-use of single components can be extensive.
Figure ??? of the audit of content at La Trobe university several years ago demonstrated this dramatically; the La Trobe University logo, for example, is used in every Web page covered by the audit of 48,084 pages (Nevile, 2004). This is typical of organisational sites where content is produced using templates. Given an inaccessible object, it is transmitted with every page transmitted. Sometimes, a set of components are transmitted just-in-case. As shown by Fairfax Digital (Jackson, 2004), being able to transmit only what is required can save the publisher substantially, but also the reception costs for the user.

Figure ???: The reuse of components in the 48,084 pages on the tested section of the La Trobe Web site. from La Trobe Website audit (Nevile, 2004)
Access For All matching
The Inclusive Learning Exchange (TILE) process provides both a proof of concept and a model for the matching of resources to people's needs and preferences. TILE checks the user's profile and then finds objects from which to compose a resource that suits their needs. As TILE includes a tool for creating and editing the user's profile, this can be done while the user is using the service. TILE uses the AccessForAll metadata profiles to match resources to users' needs, with the capability to provide captions, transcripts, signage, different formats and more to suit users' needs.
The TILE prototype has the benefit that within the TILE system, all the necessary components are available. The resources are put together dynamically (Figure ???) so it demonstrates the desired outcomes but it does not offer a model for situations where either metadata, or sought components, are elsewhere and not identified, where the resource is being made accessible to the user just-in-time.
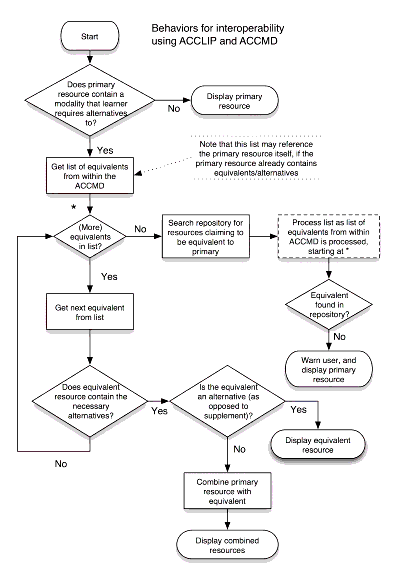
Figure ???: The behaviours for interoperability using AccLIP and AccMD in TILE (AccMD IM)
Accessibility transformation and repair services
Given that few resources are universally accessible, one can assume that most resources will need attention if they are to be rendered accessible for a particular user. As a strong motivation for accessibility often arises in a community of users rather than authors, it is not uncommon to find a third party creating an accessible component for an existing resource or part of a resource. Usually closed captions for films, for example, are produced by a party specializing in captions . So are the foreign language versions of the spoken sound tracks. A number of organisations offering such resources are listed in Chapter 7 where their availability of resources and description of them are considered.
Not all such services are perform in advance; some are able to provide the service either instantaneously, using automated services, while some involve people and take time. Nevertheless, being able to associate such a service with a resource can increase its accessibility. ubAccess has a service that transforms content for people with dyslexia; a number of Braille translation services operate in different countries to cater for different Braille dialects, and online systems such as Babelfish help with translation services.
Creating the accessible alternative components and making them available for use is shared by accessible content authors and repositories. Once there is an alternative for a resource component, it is a pity if a new one has to be created just because the existing alternative cannot be found. This means, of course, that repositories of accessible content should be online and their collections available and discoverable (see below). In the case of communities, such as an educational system, there should be no barriers to the development of networks of distributed accessible components.
Content management servers
To perform the accessibility match, there is a need for a service that provides the right combination of content and services for the user, where and when they need it. This depends on the user and resource profiles, the context information, and the pieces that are to be assembled for delivery to the user as the resource they require.
For a user, or an assistant working with them, it must be possible to create the necessary profiles and to change them for the immediate circumstances. In addition, it must be possible to make formal descriptions of the resources and link all of these together for the matching process. There are several layers of discovery involved. There is more than just discovery information needed, however, and therefore a need for systems that facilitate the making of such descriptions.
A better approach for publishers
In 2003-4, Fairfax Digital redeveloped their web site with accessibility in mind and the result is a saving of an estimated $AUD1,000,000 per year in transmission costs alone (Jackson, 2004). A bigger publisher would save even more. Flexible assembly satisfies the requirements for the users, allows for more participation in the content production process and has the benefit that it limits the production and transfer of content that will not be of use to the recipient. Descriptions of the accessibility of content of large collections can be done with tools designed for that purpose. Publishers can identify potential problems and gaps in their resource collections in advance, as was the case with the La Trobe University Web site when audited (Nevile, 2004).
Publishers who do not have complete sets of components for all potential users will need to provide or point to services that can either discover missing components, or create them. Their servers will need to be able to integrate the new components without having the original resource 'fall-apart' so the original resources should be composed dynamically of components just so others can be subsituted, added, etc. This does call for the design of more flexible resources, but can be done. If it is part of the general practice for a publisher, bringing in a foreign component should be possible without 'destroying' the original resource.
Where the original publisher does not manage the accessibility, a third party publisher will have to absorb an original resource, deconstruct it and test the individual components, and then find what is necessary and re-construct it for delivery to the user. In this case, it may not be well-formed unless it was well designed with flexibility in the beginning, even if it is accessible. That is, it may be 'accessible' component by component but not very usable. This is often better, however, than if it is simply not accessible.
The Web 2.0 strategy proposed, using technology to augment, supplement and in some cases replace author expertise, is more likely to be achieved by a combination of tools than the adoption of any particular tool. Many of these are not yet available as one-stop Web services but many are available as system components. The big changes will be possible when they are made into Web services as this will increase the network capabilities of the systems, and thus the quantity of sharing that will be possible. The possibilities will only be realised if there is commitment to them. This is not so difficult to imagine: the achievements of normal people using word processors, electronic spreadsheets and presentation tools today are similar to what could be expected for accessibility in the future with the tools and practices proposed.
Discovery of distributed accessible components

Figure ???: An AccessForAll process diagram
An outstanding issue is then, what is necessary for an accessibility service to find a suitable resource or component in a distributed environment. In the usual discovery process, users define the topic of interest and one or more other properties. In the case of an AccessForAll search, the user's needs and preferences impose additional constraints on the suitability of the resource. Initially, the author and others assumed that this would be possible and started with a simple model in which the user's needs and preferences profile (PNP) was simply added to a search query (Figure ???). The problem with this approach is that if no suitable resource is returned, or if components of a resource are unsuitable, a new search, with different requirements, will be necessary to find what is needed. Given that the results of the old search have already been evaluated, and the search information has already been used, this new search will need new requirements.
So this is where the use of FRBR becomes relevant (see Chapter 9). If resources are described with their content related to the intellectual work contained within them, it should be possible to find other resources or components with similar or even the same intellectual content.
In order to obtain the metadata that might be needed, it becomes necessary to not combine the user's needs and preferences with the other requirements in the primary search, but to use them to filter the results so that as much metadata about equivalent resources as possible can be gleaned from the resources found in the search. For this reason, the original diagram needs modification as shown in Figure ???.

Constructing a new query
There are a number of possibilities, in fact, for constructing a new query.
Let us assume somewhere a suitable result exists. (In case there isn't one, we will have to specify a fail condition.) So let us imagine we are seeking an alternative for an image that is usually inserted into a resource. Let that resource be a map, so we are looking for either a textual version of the content of the map or a recorded verbal description of it, and for our current purposes, we assume at least one such target resource exists. In other words, the problem is not to find a suitable resource so much as to find a resource with the same intellectual content as the map we already had in a situation where we did not find that alternative in the first search. This is not a new problem. We are, then, dealing with a classic problem of how to find resources like a given one that are not described in a way that has already found them. Many search engines offer a facility to ‘find similar'.
There are a number of potentially useful processes for doing this. For example, Jeon et al (2005) have proposed a method for finding similar questions by reference to the answers to those questions. Another approach is to find similar words to those used for the original search and then use the new set of words to search for more resources (Otkidach et al, 2004). Google offers some simple approaches such as: press the ‘Similar Pages' button, use the Page-Specific Search selector on the Advanced Search page, or use the related search operator. They even offer a browser button for those who are doing this frequently [Google] and provide a detailed explanation of how they find similar resources (Google Similar Pages).
Functional Requirements for Bibliographic Records
The library community is faced by the problem that a single work, such as a Shakespearean play, can be published in many forms, by many publishers, and usually with multiple copies of any particular publication. This means that a librarian offering a single copy needs to be fitted into a community of providers and, from another perspective, a user has a complex set of providers and locations for a single work.
To simplify matters, the International Federation of Library Associations developed a framework for the functional requirements for the catalgoue records they have for works. In fact, they defined four levels of development of a book starting with the intellectual endeavour, the work, which is expressed in some form, say a play, then manifested in some form, perhaps a publication by XYZ company, of a set of items, books. The four entities are therefore: work, expression, manifestation and item.
In the context of accessibility, while the FRBR authors did not explicitly take it into account because it was not relevant to them at the time, FRBR's entities can be very useful. The FRBR model assumes four user tasks: find, identify, select and obtain (Figure ???). These are not just for those seeking books but also relevant to users of digital resources. Just as book searchers may need to use information about the expression of the work they seek, so may the user who wants an alternative manifestation or item. In the case of items, of course in the digital context, any item may be displayed in many ways, and similar book items can be distinguished too, for example, the difference might be who owns them, where they arelocated, or what condition they are in. These qualities of the item, however, are similar in kind to those of interest to the digital resource user, and will need to be described to users for whom they make a difference, e.g. users of heritage books.
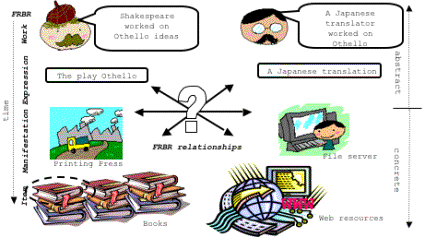
Translation into a foreign language is equivalent to tranformation into a different form, and conversion of a graphic of symbolic mathematics into a MathML version suitable for automatic transformation into Braille, for instance.
FRBR entity attributes
In the accessibility context, FRBR is relevant for helping locate other resources with the same intellectual content, as described above, but it is also relevant in that it can provide guidance for the development of application profiles for accessibility. FRBR is not a metadata schema and is not intended to be one. It is not implemented as metadata anywhere. It is a model for use by those who are working on metadata for user requirements.
The author and colleagues (Sugimoto & Morozumi) analysed FRBR as a way of testing the AccessForAll metadata (Morozumi et al, 2006). They compared the FRBR relationships and attributes of entities with Dublin Core Metadata Terms [DCMT Terms] and the ISO/IEC JTC1 Digital Resource Description (DRD) terms. In other words, the aim was to find out if the FRBR model proposed metadata that would be useful in an AccessForAll context with respect to accessibility characteristics of a resource. Similar work had been done previously with respect to the Dublin Core model when the Dublin Core accessibility work first commenced (Chapter 7).
DCMT (properties) describe what FRBR calls attributes of entities with the exception of the relation element. dc:relation is useful for describing relationships that can be of interest in the accessibility context, as demonstrated in the emerging DC Application Profile for AccessForAll (<http://dublincore.org/accessibilitywiki/>). The relationship between the attributes of dc:format and dc:type would be of interest but this depends on implementations, and is not in the metadata per se. dc:description and dc:audience may also be useful, depending on their use.
Not surprisingly, there was little in common between the elements of the DRD and the FRBR model; the DRD was designed to complement existing metadata schemas, not to duplicate them. These results led to the observation that the DCMT terms are limited in respect of accessibility adaptability in the same way as is the FRBR model. It was asserted then, that as the DRD represents the information as metadata that is required in the description of a resource to indicate its adaptability for accessibility, neither the FRBR model, nor examples of metadata such as the DCMT and MODS that are closely related to it, provide the metadata necessary for accessibility adaptability (Morozumi et al, 2006).
Interoperability
Much of the content of this chapter became a co-authored journal article (Nevile & Treviranus, 2006) and a co-authored paper presented at the World Summit on the Information Society [WSIS 2005] conference in Tunisia (Nevile & Mason, 2005).
Background
AccessForAll fits within a framework for educational accommodation that supports accessibility, mobility, cultural, language and location appropriateness and increases educational flexibility. Its effectiveness will depend upon widespread use that will exploit the ‘network effect' to distribute the responsibility for the availability of accessible resources across the globe. Widespread use will depend upon the interoperability of AccessForAll which, in turn, will depend on the success of the four major aspects of its interoperability: structure, syntax, semantics and systemic adoption. The last criterion, systemic adoption, is added here deliberately to the convention trio of criteria (Weibel et al, 2002).
There is no doubt that an important aspect of achieving interoperability is the widespread adoption of common solutions to problems. The new framework can inherit this from extensively used standards. In the case of educational resources and services, there are many major communities concerned with relevant aspects of descriptive standards and of those, a number have been engaged in the development of the AccessForAll model. Cross-domain metadata also has well-established standards that have been considered. The model is based on a set of principles that, when implemented in a variety of standard languages or systems, should maintain their interoperability at syntactic, structural and semantic levels. It also depends upon widespread systemic adoption to generate the volume of accessible components required.
The AccessForAll strategy complements work to determine how to make resources as accessible as possible done primarily by the World Wide Web Consortium Web Accessibility Initiative [WAI]. The focus of that work is technical specifications for the representation and encoding of content and services, to ensure that they are simultaneously accessible to as many people as possible. W3C also develops protocols and languages that become industry standards to promote interoperability for the creation, publication, acquisition and rendering of resources.
The focus of AccessForAll is ensuring that the composition of resources, when delivered, is accessible from the particular user's immediate perspective. It complements the W3C work by enabling a situation where a particular suitable resource is discoverable and accessible to an individual user even when it may not be accessible to all users. In some cases, this may mean discovery and provision of alternative, supplementary or additional resource components to increase the accessibility of an original resource. The distinguishing feature of AccessForAll is that it assembles distributed, sometimes cumulatively-created, content into accessible resources and so is not wholly dependent upon the universal accessibility of the original resource.
The AccessForAll specifications, while initiated in the educational community, are suitable for any user in any computer-mediated context. These contexts may include e-government, e-commerce, e-health and more. Their use in education will be enhanced if they are adopted across a broad range of domains and used to describe the accessibility of resources available to be used in education even if that was not their initial purpose. The AccessForAll specifications can be used in a number of ways, including: to provide information about how to configure workstations or software applications, to configure the display and control of on-line resources, to search for and retrieve appropriate resources, to help evaluate the suitability of resources for a learner, and in the sharing and aggregation of resources.
The AccessForAll specifications are designed to gain extra value from what is known as the ‘network effect': the more people use the specifications, the more there will be opportunities for interchange of resources or resource components, and the more opportunities there are, the more accessibility there will be for users.
So implementation has many paths available and, although only time will tell, it is important to consider these and their potential at this stage.
Interoperability an essential characteristic of Metadata
In Chapter 6, the need for metadata to be defined in a structured, formal way was defined. It was made clear that unless this is so, metadata cannot be used by machines that cannot reason or make judgements about how to interpret resource descriptions. Implied was the need for these constraints from an interoperability perspective. That is, if metadata is to be used to find distributed resources, the same query will need to be applied to a number of search engines. Interoperability implies that the single query will be comprehensible and useful to all such query engines. It is not necessary that the query is used by all of them in its original form as they may be able to transform it, prior to using it, to suit their purposes. In some cases, this means a cross-walk where two sets of metadata are linked by a mapping, one-way or two-ways. If such a mapping is not perfect, in other words is not lossless, the mappings will be, correspondingly, less than perfectly interoperable.
In Chapter 7, the need to ascertain if the metadata of resources that are already available and suitable as alternatives for inaccessible resources, was an analysis of the potential interoperability of AccessForAll metadata and the original metadata. In Chapters 9 and 10, the task of finding an accessible alternative to an inaccessible resource was considered. In such a case, it is obvious that the metadata search for the alternative needs to be interoperable with any catalogue referring to such a resource.
Developing metadata for interoperability
One aspect of interoperability is the ability to share the same kind of information with others using the same systems and acting with the same goals. Another is to work across devices including using different hardware and software without losing the necessary ‘look and feel' that facilitates learner mobility between devices.
W3C has a working group focused on Device Independence, another focused on the Mobile Web, another working on Evaluation and Repair, and a fourth working on metadata, the POWDER working group. All four Working Groups produce specifications that are important to the interoperability of AccessForAll (Table ???).
The vision we share with others is to allow the Web to be accessible by anyone, anywhere, anytime, anyhow. The focus of the W3C Web Accessibility Initiative is on making the Web accessible to anyone, including those with disabilities. The focus of the W3C Internationalization Activity is on making the Web accessible anywhere, including support for many writing systems and languages. The focus of the W3C Device Independence Activity is on making the Web accessible anytime and anyhow, in particular by supporting many access mechanisms (including mobile and personal devices, that can provide access anytime) and many modes of use (including visual and auditory ones, that can provide access anyhow).
| W3C Activity | Activity description |
| Device Independence | "Content authors can no longer afford to develop content that is targeted for use via a single access mechanism. The key challenge facing them is to enable their content or applications to be delivered through a variety of access mechanisms with a minimum of effort. Implementing a web site or an application with device independence in mind could potentially save costs, and assist the authors in providing users with an improved user experience anytime, anywhere and via any access mechanism." (W3C, Device Independence, 2003) |
| Mobile Web | This group aims to tackle ""interoperability and usability problems that make the Web difficult to use for most mobile phone subscribers." (W3C, Mobile Web, 2005) |
| Evaluation and Repair Language | "The Evaluation And Report Language is an RDF based framework for recording, transferring and processing data about automatic and manual evaluations of resources. The purpose of this is to provide a framework for generic evaluation description formats that can be used in generic evaluation and report tools." (W3C EARL, 2001) |
| POWDER | "Working Group is to develop a mechanism through which structured metadata ("Description Resources") can be authenticated and applied to groups of Web resources. This mechanism will allow retrieval of the description resources without retrieval of the resources they describe." (W3C POWDER, 2007) |
| Table ???: Relevant W3C metadata and interoperability activities | |
For a network delivery system to match users' needs with the appropriate configuration of a resource, two kinds of descriptions are required: a description of the user's preferences or needs and a description of the resource's relevant characteristics. If users are to be able to quickly configure their devices, they need their needs and preferences to be quickly recognized and implemented by the device they are using. Similiarly, if they are to search for appropriate resources (including where their search for resources causes their system to search for accessible components from which to make the resource they want), their needs and preferences descriptions have to be available to the search engine for searching and matching with the resources and their components. Where this is happening across collections of resources, a common way of describing the resources will be necessary and it will need to mirror the descriptions of the resources. So interoperability between the two sets of descriptions is necessary so that even though one is concerned with the user's needs and the other with a resource, they can both be used by the search engine. In effect, this means that the description of the user's needs should be in the same format as the description of the resource.
Typically, users with special needs will be looking for resource components that are developed by specialists. Usually specialists who have not made the original resources produce closed captions, image descriptions and video files of people signing. They are likely to know the standard assistive technologies and what they will require and can do to use the special components. In automating the matching process for the user, it is very important that the standard triggers are available for the assistive technologies. This means that the resources should be described in the way they can be understood by particular assistive technologies but also so that there is a generic description specification that all the assistive technologies can be expected to refer to. For this reason, care has been taken in AccessForAll to ensure that there is a seamless match and the established industry terms are used.
The implications for interoperability here are for exchange between systems known as ‘user agents' that typically include browsers. It is well known that browser developers pride themselves on the non-standard features they offer and that it is not easy to satisfy all browser specifications simultaneously. Fortunately, assistive technology developers who have a much smaller market are often more concerned to serve their customers and their industry associations. Nevertheless, it is important to recognize their differences and allow for their use so the AccessForAll model has to be capable of such flexibility. In fact, it aims for some generic functions to be described in a common way while allowing for extensions to accommodate custom functions or features.
AccessForAll metadata was first developed for use within the educational sector. As most resources for educational purposes are created within educational institutions, and therefore described by the educational community, descriptions of those resources are usually created according to standards designed for the educational community. Having worked with the goal of sharing resources for some time now, the educational communities have a number of ‘standards', the best-known being those developed by IEEE LOM, known as Learning Object Metadata [IEEE/LOM]. Clearly, the accessibility characteristics of resources that are ‘learning objects' need to be described in a way that interoperates with all other aspects of LOM descriptions.
Often, however, educational activities involve learners using resources that have been developed and described by other communities for their own purposes. For example, technical manuals are often used in Computer Science courses but they are not usually written for this purpose. Government information is often used in education, as are images of paintings and objects held in museums and galleries. The resources to be used by learners then, do not always originate from the educational or even the same communities and their description for discovery purposes can be very specific to the community from whence they come. In order to discover resources across communities or disciplines, then, the descriptions of the accessibility characteristics of resources need to be consistent with descriptions used in those communities.
Dublin Core metadata is not domain specific. As DC metadata is commonly used by governments, museums, galleries, and others for information sharing, AccessForAll needs to be able to take advantage of their interoperability. DC metadata also has the advantage that it is used in many countries for resources that are created in many different languages and so can be used for cross-language discovery.
DC Metadata and IEEE LOM and IMS LIP metadata are very different (Chapters 6, 7). They vary at several levels, including specifically at the structural, and semantic levels.
Not everything that will be useful to have as AccessForAll metadata is unique to the AccessForAll model so in a DC implementation, a significant amount of information will be expressed using standard DC elements. Exactly how to do this will be described in a DC Application Profile for which specific terminology (semantic values) will be defined. The value of this work for DC users is that they will be able to express the AccessForAll metadata in DC compliant ways so it will interoperate with other DC metadata. They will also be able to use standard DC applications without significant modification.
In summary, AccessForAll needs to interoperate with a number of other relevant metadata specifications and standards.
Interoperability in educational contexts
In 2003, Kevin Keenoy reported on the main metadata standards in use in education (2003):
The Dublin Core Metadata Element Set seems to be by far the most widely accepted and used set of metadata standards for ‘core’ categories applicable to any internet-based content. Almost all existing learning object metadata standards use the Dublin Core as a basis and then extend it with more specialised elements. (Keenoy, 2003, p.2)
He continued:
The standard builds on the Dublin Core, and is based on recommendations from the ARIADNE project and IMS (see later). The LOM metadata specification forms the basis of almost all existing implementations of metadata specifications for learning objects, and should probably be the basis for metadata used in SeLeNe. (Keenoy, 2003, p.3)
He goes on the explain the complex relationship between the LOM standard in many contexts and formats but explains they are closely related. This is also the case in Australia where the Educational network of Australia uses a DC-based metadata schema anas do many of the other educational systems in Australia,
So, between them, IEEE LOM and DC metadata describe a vast proportion of the resources that are of interest in education. Many educational systems use IEEE LOM metadata to describe their resources but others use DC metadata. It makes sense that these two communities should be able to exchange metadata records about their resources so they can, in fact, share their resources. To do this, they need to be able to transform metadata from one specification to the other. There is an activity, started in 2001, that aims to bring the two sets of specifications into harmony. It cannot be done easily because LOM and DC metadata are based on very different models.
The LOM abstract model is hierarchical and instead of having property-value pairs as DC metadata does, it has a rule that every element is either a container (of another element) or a leaf (to another element). This is a more typical model but very different from the DC one. Attempts to cross-walk (transform) metadata from the LOM to DC metadata, or vice-versa, typically result in substantial loss either in detail or value. LOM metadata has many more elements than the simple DC core set and so when LOM metadata is transformed into DC metadata there is a many-to-few transformation with a lot of metadata being discarded. When DC metadata is transformed for use as LOM metadata, a lot of the metadata of interest to educators is found to be missing. DC metadata lacks the structure of LOM metadata: DC metadata is ‘flat' while LOM metadata is hierarchical.
Figure ??? shows that in oprder to send a query across a number of metadata repositories in use in education, a special federated sytem is required. In this case, Stefaan Ternier et al (2008) have defined a new query language to facilite this process but each repository has to develop its own special way of exchanging information using that language - it is not possible to send the same query, as is, to all repositories, because their metadata schema are not interoperable.
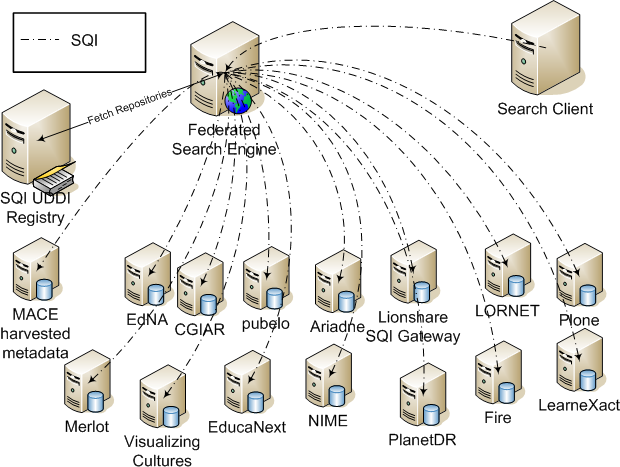
Figure ???: The Globe federated search model using ProLearn Query Language. (Ternier et al, 2008)
(insert the image of how DC and LOM cannot support a round-trip transformation....) etc - esp to quote from paper for ISO about why MLR is not right...
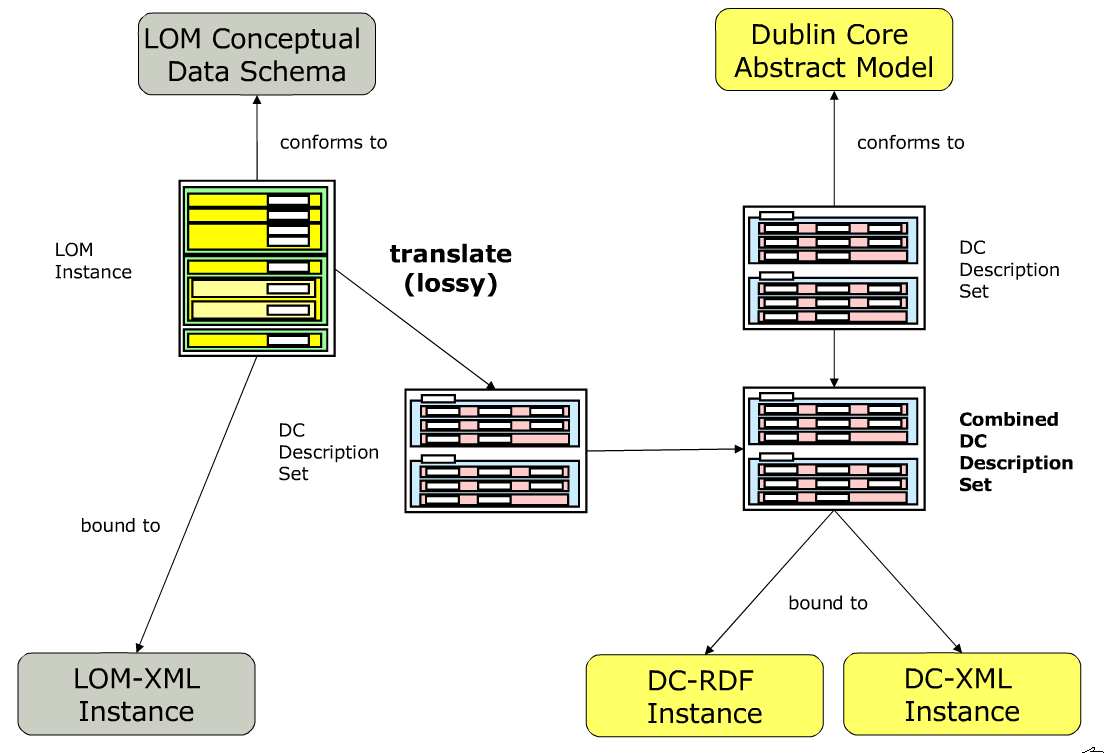
Figure ???: The point of loss of information in the LOM -> DC translation process (Johnston et al, 2007)
There have been several attempts to find good ways of moving metadata back and forth from one system to the other without loss. In late 2005 there was what appeared to be a useful model developed for this. Early work focused on moving information expressed as metadata from one system to the other but recently was decided that it is more effective to relate the elements that contain that information and then express the metadata in whatever syntax is chosen. Mikael Nilsson explains this in his model:
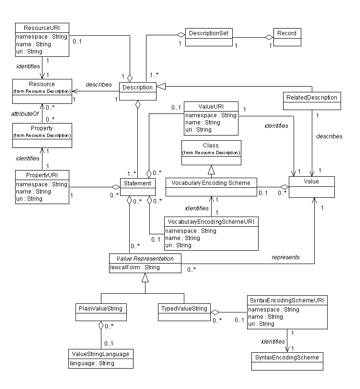
From “The Future of Learning Object Metadata Interoperability Towards a Framework for Metadata Standards“ publisher etc?]
Nilsson concludes:
We have demonstrated that true metadata interoperability is still, to a large extent, only a vision, and that metadata standards still live in relative isolation from each other. The modularity envisioned in application profiles is severely hampered by the differences in abstract models used by the different standards, and efforts to produce vocabularies often end up in the dead end of a single framework. In order to enable automated processing of metadata, including extensions and application profiles, the metadata will need to conform to a formal metadata semantics.
To achieve this, there is a need for a radical restructuring of metadata standards, modularization of metadata vocabularies, and formalization of abstract frameworks. RDF and the Semantic Web provide an inspiringly fresh approach to metadata modelling: it remains to be seen whether that framework will be reusable for learning object metadata standards.
This suggested that is may not be until there is a shared, single IEEE/LOM/DC abstract model for education that there will be perfect interoperability between DC and IEEE/LOM resource descriptions but it may, on the other hand, be possible in the particular case of AccessForAll metadata because it is based on a more interoperable abstract model.
More recently, Nilsson, Baker & Johnston have proposed a four-level model for interoperability (2008). Pete Johnston (2008) summarises the document as follows:
The document presents a "layered" approach, describing four distinct "interoperability levels", each building on the previous one, and attempting to specify clearly the assumptions and constraints which apply at each of those levels, and the expectations which a consumer can have for metadata provided "at" a specified level.
Level 1: "Informal interoperability", based essentially on the natural-language definitions of metadata terms;
Level 2: "Semantic interoperability", based on the RDF model;
Level 3: "DCAM-based syntactic interoperability", introducing the notions of descriptions and description sets, as defined by the DCMI Abstract Model;
Level 4: "Singapore Framework interoperability", in which an application is supported by the complete set of components specified by the Singapore Framework for Dublin Core Application Profiles.
Interoperability of personal needs and preferences
Keenoy (2003, p.7) points to a set of standards that are used to describe, in one way or another, learners for the purposes of learning management systems. DC is conspicuously missing from the list (as is to be expected according to Chapter 8). This is primarily because the DC profile has not yet been developed, but also because the AccessForAll proposal does not attempt to describe permanent characteristics of people, as does most learner profile metadata.
The Benefits of Interoperability
A key challenge in accessibility is the diversity of need; different people require different accommodations. Established approaches towards addressing this are to allow customization by the end user (e.g. text size and color) and to offer alternative presentations of the same content where automatic customization is not possible (e.g. text description of diagrams or audio descriptions of video content).
Integrated systems potentially offer an efficient way of managing and even extending this. They can personalize the way the interface and the content are presented to the user and further, which content is presented to them can be determined by the system on the basis of stored information about them and their preferences.
Such systems offer organisations the opportunity to efficiently manage their requirement to meet the needs of their users with disabilities. If they implement user profiles and adopt the AccessForAll approach, the system will “know” how best to present content and interfaces to each individual user. If they implement the approach for the metadata of the content stored in their repositories, then the system can automatically offer their content, and other information, in the most appropriate format to meet individual user needs.
The Semantic Web offers one obvious technology that will be enabled by the AccessForAll approach. Already the AccessForAll specifications recommend using EARL so that the metadata will be as flexible and rich as possible. The range of other extensions includes opportunities for valuable cross-lingual exchanges to suit learner needs as well as cross-disciplinary changes of emphasis. Applications and Web services that transform resources or resource components to suit the needs of users with cognitive disabilities is a huge area that has hitherto not received the attention it deserves.
Chapter summary
In this chapter, .....???
Chapter 11: Implementation
Introduction
This chapter faces the question of praarcticality, or generality: will this research lead to new behaviours and so make the Web of information more accessible to more people? It has a focus on the issues to do with interoperability that put pressure on all metadata developments and, in particular, AccessForAll metadata. It includes reports of implementations of the AccessForAll style metadata and also, at a different level, evidence of lessons about metadata being learned by at least the educational community from this work.
Implementation
By July 2006, it was clear that the AccessForAll approach was being adopted in the educational domain (Appendix 4). By October 2007, there were 86 resources listed as relevant to AccessForAll and a glance through the list shows the dissemination of this idea throughout the academic world (Appendix 5). The Accessibility Guidelines that preceded the AfA work were read 176,505 times between Sept 2002 and June 2006 and in the same period the IMS AfA Specifications were downloaded 28,082 times. The United Kingdom Government had included the need for metadata in its standard for accessible documents in the UK (Appendix 6) and on October 16, 2007 the Australian Government Locator Standard Committee voted to include an AccessForAll metadata element for all accessible documents in Australia (IT-021-08, 2007, p. 14). At the same AGLS meeting, the National Library of Australia representative reported that the NLA is starting to write metadata for individual components such as images and songs (IT-021-08, 2007, p. 14). This is an important, although independent, action that will contribute towards implementation of AccessForAll. Finally, the ISO/IEC JTC1 SC35 is now developing a user profile for use with the universal resource console (Chapter 8).
Authors notes: see the important new paper from italy: "Automatically producing IMS AccessForAll Metadata" in Proceedings of the 2006 international cross-disciplinary workshop on Web accessibility (W4A): Building the mobile web: rediscovering accessibility?Year of Publication: 2006 authors:Matteo Boni CRIAD -- Centro per la Didattica, Via Sacchi, Cesena (FC), Italy
Sara Cenni Università di Bologna, Via Sacchi, Cesena (FC), Italy
Silvia Mirri Via Nura Anteo Zamboni, Bologna Italy
Ludovico Antonio Muratori Corso di Laurea in Scienze dell'Informazione, Via Sachhi, Cesena (FC), Italy
Paola Salomoni
ISBN:1-59593-281-Xhttp://portal.acm.org/citation.cfm?id=1133219.1133237&jmp=cit&coll=GUIDE&dl=GUIDE
ABSTRACT
"Accessible e-learning is becoming a key issue in ensuring a complete inclusion of people with disabilities within the knowledge society. Many efforts have been done to include accessibility information in e-learning metadata and the major result consists in the IMS AccessForAll Metadata definition. Unfortunately the complex behavior managed by this standard could be perceived by authors as a new boring and difficult activity enforcing the idea that the production of accessible Learning Objects (LOs) is too complex to be accomplished. This paper presents a novel component of an authoring and producing software architecture, designed and implemented to automatically create the IMS AccessForAll Metadata description of an accessible LO."
Note that they have integrated the process into the workflow and have the following diagram:
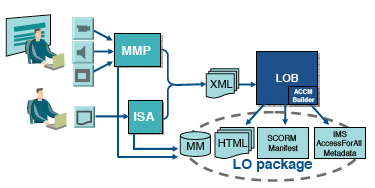
Having described acclip and accmd, they say:
While these metadata represent a truly enabling option, implementing an ACCMD description of each LO could turn into a new tiresome and protracted task for authors. Reducing the distance between users’ needs and authors’ efforts is now a crucial aspect to ensure accessibility of e-learning materials. The solution relies on authoring tools for creating LO that have to accomplish two main goals:
1. Offering support to author in creating fully inclusive materials by suggesting correct behaviors and sometimes imposing the completion of all additional information needed to ensure accessibility (e.g. once the image is inserted, the authoring tool ask for a description that is required for blind users).
2. Automatically structuring the media alternatives, both inserting correct markup inside the (X)HTML pages and describing the whole structure with ACCMD.
They say:
Such a tool is now integrated in a complex process used inside the University of Bologna to create accessible LOs. Accessibility of e-learning materials produced has been widely tested by involving a group of people with disability in verifying on-line contents and services. Universality of materials has been tested by using different browser running on different platforms (specifically MS Internet Explorer 5.0 and later, Mozilla Firefox 1.0 and later, Netscape Communicator 7.0 and later, Lynx 2.8.4 rel. 1, IBM Home Page Reader 3.0, Apple Safari 1.0). Finally, LOs produced by our process are compliant to all the constraints considered by the Italian Law on Web Accessibility,
but they also say:
Unfortunately, the IMS description is ignored by the LCMS (Learning Content Management System) in use. Generally this new technology is not fully supported and there are just few solutions that use ACCMD and ACCLIP to provide adaptive accessible contents. We assume that a growing availability of IMS ACCMD tagged LOs will drive the development of adaptive modules for the more diffuse LCMS and will definitively diffuse the use of the whole IMS specification on accessibility.
------------- ??
heading??
TILE
The ATRC developed a system known as 'The Inclusive Learning Exchange' initially as a prototype and then as the server for students at the University of Toronto. TILE is open source????
Proof of concept

Figure ???: ABC Video on demand
The author experimented with the idea of distributed metadata 'just for fun'. The result was surprising, and pleasing.
A page of the Australian Broadcasting Commission site offering video on command (ABC Video On Demand online at <http://www.abc.net.au/vod/news/>) was visited. This page had been casually recommended as a well-written resource. It was hoped that there might be sufficient information available from the resource for an alternative resource in a different mode to be found relatively easily using Google. On the day of testing (26/4/2006), the author took some words from the 'alt tag' for a video and submitting them to Google (and Flickr). This led to a blog (<http://biukili.blogspot.com/>) that provided text information about the topic – amazing and satisfying given that the first resource was only several hours old on the Web, as was the topic. Admittedly news might be a special case, but the exercise was gratifying. Google was used but not the special ‘similar resource' features. That too may have produced a text description of what was in the video.
In associated work attempting to explain why this approach will work, the author and colleagues have mapped Dublin Core and AccessForAll metadata to the FRBR model. They noted the distinction between metadata to identify the intellectual content of resources and that used to determine their presentation, control and content characteristics relevant to accessibility (as defined in the user's PNP). They were able to relate all the relevant attributes of potentially suitable resources using the hierarchy in the FRBR model but that when it comes to discovery of such a resource, we may need more than subject descriptions to find it. This means that descriptions of authors, publishers, etc may also be necessary.
Implementation activities
Implementation of AfA is not yet simple. While there is a set of machine-readable resources to help those implementing it in the educational context where they use IEEE LOM metadata, this is not yet the case for DC metadata, expected to be a much larger implementation context. Nevertheless, the signs are very positive as shown by the emerging evidence of acceptance of the AccessForAll approach.
W3C recognition of AfA metadata in POWDER
The set of POWDER use cases include the following:
2.1.6 Web Accessibility B (self labeling, content features, profile matching)
Automated production of metadata
A report from Italy included the following:
This work presents components, which are embedded in an existing authoring/producing tool and automatically creates the IMS AccessForAll Metadata description of a LO, starting from the natural structure of multimedia contents.
and
Such a tool is now integrated in a complex process used inside the University of Bologna to create accessible LOs. Accessibility of e-learning materials produced has been widely tested by involving a group of people with disability in verifying on-line contents and services (Boni et al, 2006).
That tool and its use are described in more detail in "Automatically Producing Accessible Learning Objects" (Di Iorio et al, 2006). The author also reported the benefit of using good accessibility evaluation tools that can produce the necessary metadata (Nevile, 2004).
Engage
The IMS Tools Interoperability project is part of the Engage project at the University of Wisconsin - The Engage program partners with UW Madison faculty and academic staff to apply innovative uses of technology for teaching and learning. In this project, UW-Madison, WebCT, Blackboard, Sun Microsystems, SAKAI, QuestionMark, and staff from Stanford, UC Berkeley, MIT, Indiana University, and the University of Michigan are all involved. A special server edition of ConceptTutor, and a Moodle LMS were proposed for 2005 Alt-i-lab [Alt-i-lab 2005] conference in Sheffield, England in June 2005.
The aim is:
To promote accessibility and to demonstrate the use of IMS ACCLIP and ACCMD standards for accessibility, we have modified Fedora to implement an RDF binding of ACCLIP and ACCMD. A student’s accessibility preferences are matched to the accessibility characteristics of the content at the time of the request. Thus, a visually impaired student will receive content tuned to her needs when she requests a ConceptTutor without having to know how to request the specially tuned content (Engage, 2007).
In "Beyond the LOM: A New Generation of Specifications," Michael J. Halm says:
The importance of the ACCLIP specification may not be immediately understood, but this specification provides enormous opportunities to customize and adapt the learning experience based on the users preference. This powerful capability now can be used for anyone, not just those with disabilities. These preferences will be stored in the Learner Information Package and could travel with the learner from one on-line environment to another. Since these preferences are created and maintained by the learner, this gives the individual the control to change the environment as needed. This also allows one to consider the learning style of the learner as part of the environment. Visual learner will be better able to set preferences that are unique to the type of way they learn. This preference can translate into the type of learning objects that are selected and deliver in the learning environment (Halm, 2003).
SAKAI and FLUID
SAKAI is a university consortium effort ot develop a set of open source tools for tertiary education.
FLUID is a huge project in which the AccessForAll idea is being taken to the next logical step: while it is useful to be able to switch components, it is really necessary to also be able to switch user interface components, and that is what FLUID is about.
Metadata in WCAG 2.0
In late 2007, the WCAG Working Group is finalising Version 2.0 of WCAG. The last remaining problem is what to do about metadata. It has produced some interesting challenges. The AccessForAll position, put by the author to the WCAG WG, is that there should be metadata to describe the content of every resource, inclusing its accessibility characteristics, on every Web page that is considered accessible. The Chair of the WCAG WG, Gregg Vanderheyden, is interested because he sees that in the case where a page is accessible in the sense that it is conformant, someone who wants a version of the page that happens to suit them but is not fully conformant, might want to find that version. As Jutta Treviranus wrote, (24/10/2007 - email):
I think we are missing the point. An important consideration is that Metadata does not require and is not about conformance. It is about labelling and finding accessible resources. You need to think beyond a single site or a single page. If there are a number of resources and some are accessible to you and some are not, Metadata helps you to find the ones that are accessible to you or alternatively to gather the same information as the Web resource you want from a number of pieces that are accessible to you. So is WCAG only about access to a single site or about access to the Web? If it is about access to the Web then you need to think about systems and varied resources, some that are more accessible to a given user and some that are not.
Sadly, some think, the response to this was:
This is beyond the scope of WCAG 2.0. It sounds like a good candidate for the next version.
WCAG 2.0 is addressing the accessibility of Web pages, the unit of conformance. There are a number of other issues related to the larger view of the web that have also been deferred to future work. (Loretta, 24/10/2007 - email)
One major constraint for W3C's work is that it needs to result in technical specifications; nothing can be recommended that cannot be tested. Another constraint is that it must be possible in every case. Vanderheyden posed the problem of the resource that is to be published but, by law, cannot be altered any way in the process. An example is an historic digital image, that has value in being that image. The problem with that image would be that metadata could not be added to it and nor could even a link to metadata. Fortunately, on the day this problem was to be solved, another W3C WG released their first version of a solution. The Internet Content Ratings Association community want to be able to add metadata about resources that is very similar to the AfA metadata in type - they want to describe the relevant characteristics of resource content that leads to ratings for nudity, violence, etc. The W3C Protocol for Web Description Resources (POWDER) Working Group [POWDER WG] developed POWDER to enable information to be conveyed via the http head of a resource and this is just what is needed for the Vanderheyden problem. The issue is what is to be conveyed, and the POWDER WG has now modified their examples to include two use cases that draw upon AfA metadata.
Metadata lessons
In the ISO/IEC context, a metadata activity has been underway on parallel with this research. National bodies and experts have been defining how metadata should be written for the educational context in what is known as the Metadata for Learning Resources standard (ref). This standard is supposed to assure that, in the future, educational metadata is consistent so that it will be more interoperable and useful.
The introduction to this standard (at the draft stage) states:
The primary purpose of this standard and its parts is to facilitate search, acquisition, evaluation, and use of learning resources, for instance by learners, instructors or automated software processes. The interoperability of these functions can be achieved through harvesting or federated search processes, among other technologies and solutions.
… It also has been developed with a view to achieve compatibility with both IEEE 1484.12.1-2002 LOM and Dublin Core ISO 15836, while also addressing user-driven requirements and uses not explicitly addressed in those two standards. (ISO/IEC CD2 19788-1, as at July 15, 2008, page 1, confidential document)
In an international collaborative effort to ensure this standard really does achieve its goals, the author produced the following diagrams (Figures ??? to ???) to illuminate the issues of incompatibility:
Insert MLR -1 to MLR-3 here….
The diagrams show that the first proposed model of metadata included many problems in terms of interoperability, which, to a large extent, depends on modularity and what is known in the Dublin Core community as the one-to-one rule: any metadata record should refer to only one resource (ref???). As explained earlier, hierarchical metadata models are not compatible with flat models, and for this reason, the proposed metadata model could not be assured of compatibility with the DC model. In addition, the mix of metadata about the resource, the contributor, the metadata record would break the necessary modularity rules and the first-class nature of good metadata.
Metadata is described as first-class when it can itself be treated as data. In such a case, a metadata record is itself treated as data for any metadata about it. So the meta-metadata record proposed by the draft proposal would break this rule. The Web’s inventor Tim Berners-Lee (1997), postulated the rule early in the life of the Web, and it was adopted early by the Dublin Core community.
Essentially, Berners-Lee explained that if metadata was not carefully defined and ‘first-class’, it would not be useful for logical inferences to be made by machines. That is, in lay terms, if a statement about an object is not also an object, it is not possible for a machine to perform the only sort of reliable functions we yet know to engage machines with, logical functions such as, AND, OR, NOT. As these functions are essential to search and control of metadata by machines, they are very important in the metadata world. If metadata is first-class, we can imagine something like this:
PRINT <metadata records> of <all objects> containing <title> includes “Fred” AND “Jones” but NOT “Freda”.
The work for the MLR is on-going but it is important to note that it is experiences such as those had by the ISO/IEC SC 36 Working Group responsible for AccessForAll metadata (Working Group 7) that has led to the international effort to control the metadata model (ref is posting to WG7 by LN ???).
Distributed Accessibility
While the TILE model can be extended within a given context, it is probably not until it is working across vast numbers of resources and context that it will really start to pay off for the individuals. The issue is: if a component is not accessible, how can an alternative resource, or component or service be discovered on the Web, if there is such a thing?
There are at least three approaches being considered; FRBR descriptions, OpenURIs and POWDER.
The author asserts that if it is easier to find alternatives on the Web, and items of interest in one mode are also available in other modes because more items are available and they are discoverable, providing users with alternatives to inaccessible content will become more of a community activity and thus more successful. If this hypothesis is right, the burden on individual content developers can shift a little from the frustratingly unsuccessful one of requiring all content to be provided in universally accessible form, to a requirement to provide accessibility services.
In the rare case where a resouce for some reason cannot be associated with metadata, for example when it is a sppecial archive and by law cannot have any chancges, not even the addition of metadata, it may be possible to use the POWDER protocol and put metadata in the HTTP header.
FRBR descriptions
rgnwrgnrf
OpenURL
One possibility is to launch a query once, and to develop a service that can formulate a suitable OpenURL from a user's content query in combination with their needs and preferences profile. Wikipedia provides a useful explanation of OpenURI:
An OpenURL consists of a base URL, which addresses the user's institutional link-server, and a query-string, which contains contextual data, typically in the form of key-value pairs. The contextual data is most often bibliographic data, but in version 1.0 of OpenURL can also include information about the requester, the resource containing the hyperlink, the type of service required, and so forth. For example:
http://resolver.example.edu/cgi?genre=book&isbn=0836218310&title=The+Far+Side+Gallery+3
is a version 0.1 OpenURL describing a book. ...
The most common application of OpenURL is to provide appropriate copy resolution: an OpenURL link points to the copy of the resource most appropriate to the context of the request. If a different context is expressed in the query, a different copy ends up resolved to; but the change in context is predictable, and does not require the creator of the hyperlink to handcraft different URLs for different contexts. For instance, changing either the base URL or a requester parameter in the query string can mean that the OpenURL resolves to a copy of a resource in a different library. So the same OpenURL, contained for instance in an electronic journal, can be adjusted by either library to provide access to their own copy of the resource, without completely overwriting the journal's hyperlink. The journal provider in turn is no longer required to provide a different version of the journal, with different hyperlinks, for each subscribing library (Wikipedia, 2007).
In simple terms, an openURI contains a place for customisation information to be added by a server. It is not difficult to imagine a versio of OpenURI that adds information not about the particular location of a copy of a book that is in a number of places, but about an accessible alternative version of a content component.
The future
There is a growing community who are publishing small objects on the Web and even offering some description of them. Social activities are then taking over and others are adding ‘tags' to those objects. As, in the end, such tags may be more plentiful than other metadata, we are interested in how this activity may serve to increase the effectiveness of our process.
Increasingly, images are ‘tagged' by either their creators or others. If an image is tagged, using such systems as Flickr (FLICKR online at <http://www.flickr.com/>), the tags could be used to discover a text resource that has the same intellectual content. We are aware that while it can be asserted with some confidence that tagging of images and the number of images on the Web is increasing, it is not yet clear if the same will be true for resources in other modalities. Although there is not an obvious rush to place text versions of sound files on the Web, there is a strong move towards more atomic resources and, in many cases, those are small ‘chunks' of text. The drive behind this move is the growing interest in RSS (Really Simple Syndication or RDF Site Summary) (RSS Specification online at <http://web.resource.org/rss/1.0/spec>) feeds, and many people are responding to this use of personal ‘pull' technologies by publishing in ways that support RSS. There is, then, some hope that there will be small chunks of text that are tagged and may be useful as alternatives to images.
Chapter summary
In this chapter, ...
NOTEs
Chapter 12: Conclusion
Introduction
The Preamble (Chapter 1) defines accessibility as a successful matching of information and communications to a user's needs and preferences to enable the user to interact with and perceive the intellectual content of the information or communications. The Introduction (Chapter 2) says:
The first decade of international effort to make the Web accessible has not achieved its goal and a different approach is needed. In order to be more inclusive, the Web needs published resources to be described to enable their tailoring to the needs and preferences of individual users, and resources need to be continuously improvable according to a wide range of needs and preferences, and thus there is a need for management of resources that can be achieved with metadata. The specification of metadata to achieve such a goal is complex given the requirements, themselves not previously determined.
The subsequent chapters report on:
· the last ten years' efforts to define disability and thus accessibility (Chapter 3);
· the development of universal accessibility techniques for making the content of the emerging Web accessible (Chapter 4);
· what success or otherwise has resulted from the universal accessibility approach and responses to this state (Chapter 5);
· an understanding and definiton of metadata and its potential role in a networked, digital world (Chapter 6);
· early investigations and efforts in the use and likely availability of metadata to support accessibility or resources (Chapter 7);
· a new use of metadata to describe individual user's needs and preferences with respect to resources in ways that are useful to people with special needs for effective perception of their content (Chapter 8);
· a more traditional use of metadata to describe resources in ways that are useful to people with special needs for effective perception of the intellectual content of the resource (Chapter 9);
· an extended use of metadata to provide a means of managing digital resource components for matching of compositions of those resources in ways that were effective for individual users (Chapter 10);
· the definition of effective interoperability and the need for technical interoperability of AccessForAll metadata if its implementation is to become a reality (Chapter 11), and then
· this conclusion.
Final discussion
In "Accessibility, usability and adaptability: responding to Dublin Core Profiles of Needs and Preferences", the authors assert:
.. the newly emerging IMS and Dublin Core adaptability and accessibility standards and the proposed profiles of needs and preferences (PNP) is set to have a profound impact on the way we view the creation of digital content as well as the way it is presented to us (Green S, ???, p. 18).
This thesis has worked its way through a maze of issues to justify a simple contention stated at the beginning:
Considering the problems of accessibility, the context in which the problem occurs, and the available solutions, it has been necessary to define a more comprehensive framework in which the available parts can function, taking better advantage of the emerging technologies, without compromising either the interests of stakeholders or existing efforts, to achieve a better outcome for users and publishers.
The thesis has followed the structure proposed in the diagram, also shown earlier:
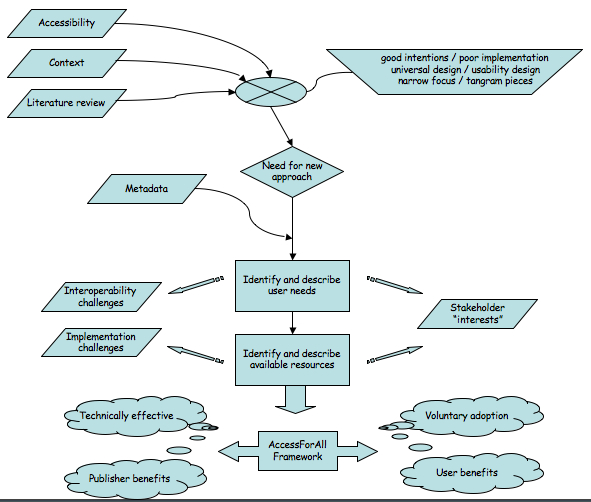
It has been shown that given the newer technologies and techniques, including what is known as Web 2.0 technologies and metadata, it is possible to be more comprehensive in the approach to accessibility without compromising hard-won efforts and that there is a receptive community that are willing to work with the new framework. The thesis is the first and only document to comprehensively explain this work and show its potential to justify the claims of Green et all and to support future work.
Future work
events and places, FLUID, distributed discovery, ..... further work includes work on how to discover the extra pieces - using FRBR??
References
for ref guides see http://www.education.uts.edu.au/fstudents/downloads/APA_Ref_Guide.pdf
{kind=link}