Navigation
This site is at beta test stage! Comments are welcome. Contributions are sought
and will be published with acknowledgement.
home page
quick overview
flow chart
site index
contact us
site use
contribute now!
©Liddy Nevile
Acknowledgements
Teaching language
The problem
Internationalisation of the web is a major goal for many. The problem is that
the use of many different alphabets involves more than changes of font. Some
alphabets it is not easy to allow for the wide variety of alphabets and character
representations that make up written languages, let alone have 'texts' that
run from left to right integrated with those that run from right to left, or
top to bottom. In addition, many languages are not written using alphabets at
all.
The most effective approach towards a solution to these problems has been the
work around the use of Unicode, coupled with SVG and SMIL and stylesheets. Unicode
is a more complex matrix set than the original ascii character set developed
in the early days of computing by Americans, for whom it mostly 'did the job'.
With the involvement of so many languages on the web, Unicode provides a way
for new character sets to be developed for languages that have not been used
on computers. This does not happen without a cost, however. Most legacy software
does not understand Unicode, and only a few new browsers etc can cope with it.
So there will be a transition period in which it will need to be specifically
indicated and promoted, and plug-ins may be needed.
The layout options are no longer a problem, and the use of Unicode is becoming
far more widespread in terms of authoring and access packages.
Basic accessibility requirements expect the change of language within a document
to be flagged by tags indicating the language of what follows.
See generally http://www.w3.org/International/
There are a number of new standards and practices that, in combination, make
it possible to create interesting multi-lingual pages. Language tagging, ie,
indicating a change of language, is an accessibility requirement. Because some
of the aspects of working with foreign languages, ie several languages within
a single web resource, or working with non-English language, can be difficult,
it is recommended that users consult the W3C help pages at http://www.w3.org/International/O-help.html.
Language tagging in HTML and XML
from http://www.w3.org/International/O-HTML-tags.html
"Language codes can be (and should be) used to indicate the
language of text in HTML and XML documents. For HTML 4, language
codes are specified with the lang attribute. For XML, language codes are given
in the xml:lang attribute. In both cases, language information
is inherited along the document hierarchy, i.e.it has to be given only once
if the whole document is in one language, and language information nests,
i.e. inner attributes overwrite outer attributes.
Language codes are defined in RFC 3066, which obsoletes the older
RFC 1766. XML has been
updated to use RFC 3066 by an erratum. RFC 3066 is based
on ISO-639 two-letter
and three letter language codes, and on ISO-3166 two-letter
country codes. RFC 1766 did not include three-letter language codes. Examples
include:
| Code |
Language |
Explanation |
| en |
English |
ISO-639 two-letter language code |
| mas |
Masai |
ISO-639 three-letter language code |
| fr-CA |
French as used in Canada |
ISO-639 two-letter code with ISO-3166 two-letter country code |
| en-scouse |
English Liverpudlian dialect known as 'Scouse' |
ISO-639 two-letter language code with addition, IANA-registered |
| i-klingon |
Klingon |
IANA-registered
language code |
| x-pig-latin |
Pig Latin |
Unregistered/Experimental |
Note that other specifications, such as SMIL, SVG, etc. often expect language
encoding to be in their own format. See http://www.w3.org/International/O-HTML-tags.html
HTTP
from http://www.w3.org/International/O-HTTP.html
"HTTP is the protocol that
is used to transfer Web pages from the server to the client (or back in some
cases). HTTP(HTTP 1.1) contains
the following internationalization features:
- Indicating the character encoding of a page sent from the server to the
client (charset
parameter) [local]
- Indicating the character encodings understood by the client to the server
- Indicating the language(s) of a page sent from the server to the client
This is done using the Content-Language response header.
- Indicating the language(s) understood by the user to the server (language
negotiation)
This is done using the Accept-Language request header."
CSS & other style sheets
from http://www.w3.org/International/O-CSS.html
"Level 1 of the CSS style sheet
language doesn't have any explicit provisions for styles other than those
practised for western, left to right languages. However, most of the formatting
properties are neutral with respect to writing direction.
CSS level 2 adds explicit control
over writing direction, quotation styles, numbering styles, and other things.
HTML 4.0 has its own attributes and elements for writing direction, but CSS2
provides the necessary control for XML documents.
Vertical text, ruby, and additional spacing & line breaking for multilingual
documents are on the agenda for the next level of CSS."
Charset parameter
from http://www.w3.org/International/O-HTTP-charset.html
"Documents transmitted with HTTP that are of type text, such as text/html,
text/plain, etc., can (and should!) have a charset parameter, which specifies the character
encoding of the document.
[HTTP 1.1 says that the default charset is ISO-8859-1,
but because there are still too many unlabeled unlabeled documents in various
encodings, browsers use the reader's preferred encoding when they don't get
the information, on the assumption that most readers read documents in their
own language. Therefore it is important to always label Web
documents explicitly.]
The line in the HTTP header typically looks like this:
Content-Type: text/html; charset=iso-8859-1
Any character encoding that has been registered with IANA can be used, but
it may be too much to ask of a browser to understand all of them. Some people
have suggested limiting the allowed encodings to just ASCII, ISO-8859-1, UTF-8
and UTF-16. (See the charset
table for an indicative list of encodings supported by major browsers.)"
Ruby
"Ruby" are short runs of text alongside the base text, typically
used in East Asian documents to indicate pronunciation or to provide a short
annotation. This specification defines mark-up for ruby, in the form of an XHTML
module [XHTMLMOD].
from http://www.w3.org/TR/ruby/
"Ruby is the term used for a run of text that is associated
with another run of text, referred to as the base text. Ruby text is
used to provide a short annotation of the associated base text. It is most often
used to provide a reading (pronunciation guide). Ruby annotations are
used frequently in Japan in many kinds of publications, including books and
magazines. Ruby is also used in China, especially in schoolbooks.
Ruby text is usually presented alongside the base text, using a smaller typeface.
The name "ruby" in fact originated from the name of the 5.5pt font size in British printing, which is about half the
10pt font size commonly used for normal text.
Figure 1.1 shows an example, with three ideographs (kanji)
as base text, and six hiragana giving the reading (shinkansen - Japanese bullet
train).
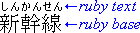
Figure 1.1: Ruby text giving the reading of each character
of the base text.
East Asian typography has developed various features that do not appear in
western typography. Most of these can be addressed appropriately with style
sheet languages such as CSS
or XSL. However, additional
markup is required to define the association between base text and ruby text.
This specification defines such markup, designed to be usable with XHTML,
so that ruby text is available on the Web without using special workarounds
or graphics. Although this specification gives examples of actual rendering
to make it easier for most readers to understand the markup, all such examples
are informational only. This document does not specify any mechanisms for
presentation or styling; this is part of the respective style sheet languages.
Sometimes more than one ruby text is associated with the same base text.
A typical example is to indicate both meaning as well as reading for the same
base text. In such cases, ruby texts may appear on both sides of the base
text. Ruby text before the base text is often used to indicate reading; ruby
text after the base text is often used to indicate meaning. Figure 1.2 shows an example of base text with two ruby texts,
giving reading using hiragana and Latin letters.

Figure 1.2: Two ruby texts applied to the same base text.
In addition, each ruby text may be associated with different, but overlapping,
parts of the base text, such as in the following
example:
| Month |
Day |
Year |
| 10 |
31 |
2002 |
| Expiration Date |
Figure 1.3: Base text with two ruby texts using different
associations
In this example, the base text is the date "10 31 2002". One ruby text is
the phrase "Expiration Date". This ruby text is associated with the entire
base text. The other ruby text has 3 parts: "Month", "Day" and "Year". Each
part is associated with a different part of the base text. "Month" is associated
with "10", "Day" is associated with "31", and "Year" is associated with "2002"."
Note that the coding for the table above is:
<div class="figure">
<table>
<tbody>
<tr class="rt" style="text-align: center">
<td>Month</td>
<td>Day</td>
<td>Year</td>
</tr>
<tr class="rb" style="text-align: center">
<td><strong>10</strong></td>
<td><strong>31</strong></td>
<td><strong>2002</strong></td>
</tr>
<tr class="rt" style="text-align: center">
<td colspan="3">Expiration Date</td>
</tr>
</tbody>
</table>
<p><strong>Figure 1.3</strong>: Base text with two ruby
texts using different
associations</p>
</div>
For more information about Ruby mark-up, see http://www.w3.org/TR/ruby/#simple-parenthesis
Ruby accessibility
from http://www.w3.org/TR/ruby/#non-visual
"Documents containing ruby markup may in some cases need to be rendered
by non-visual user agents such as voice browsers and braille user agents.
For such rendering scenarios, it is important to understand that:
- Depending on the user and the situation, different ways of rendering may
be appropriate.
- Ruby text that represents reading may have to be treated differently from
ruby text that contains other information.
- For appropriate non-visual rendering, it is important to indicate the function
of each ruby text.
- There often are some differences between the reading indicated by the ruby
text and the actual pronunciation.
- The reader may be interested in getting information about the (ideographic)
base text.
Depending on a user's needs, the way a text should be read may vary from
very quick and 'cursory' reading to very careful and detailed reading. This
may lead to different ways of treating ruby text in non-visual rendering,
from skipping ruby text in fast reading to detailed exploration of the ruby
structure and the actual characters used in careful reading.
In the frequent case that ruby texts represent reading, rendering both the
base text and the ruby text may produce annoying duplications. A speech synthesizer
may be able to correctly pronounce the base text based on a large dictionary,
or it may in other cases be able to select the right pronunciation based on
the reading given by the ruby text.
Not all ruby texts represent pronunciations. Authors should distinguish ruby
texts used for different purposes by using the class attribute. This is demonstrated
above by using class="reading" for ruby text used to indicate reading.
Ruby text indicating reading may not produce the correct pronunciation even
in cases where the script used at first glance seems perfectly phonetic. For
example, Bopomofo is associated independently for each character of the base
text; context-dependent sound or tone changes are not reflected. Similarly,
in Japanese, spelling irregularities can occur, such as using "?"
(hiragana ha) for the topic suffix pronounced "?" (wa), or using
vowels for indicating lengthening. For such cases, authors may want to supply
the actual pronunciation with special markup designed for that purpose, or
may rely on the aural rendering system being able to handle such cases correctly."
Last updated: 8 March 2002